



兵棋规则是兵棋中规范推演过程,约束作战行动,裁决行动结果的相关规定、数据及模型的总称。规则是兵棋的核心要素,也是兵棋中最核心、最复杂的组成部分。通常可分为规范兵棋运用的推演规则,以及定性判断为主的逻辑规则和定量判定为主的数据规则等。
推演规则主要是指针对如何确定先手方、推演程序等内容的规定。推演程序,是对推演和裁决机制的人为规定,决定了推演各方如何进行交互对抗,以及各种行动按照什么顺序进行裁决。推演程序又可分为推演流程和裁决流程,是手工兵棋能够顺利组织对抗推演的必要条件。在手工兵棋中,对抗各方需要严格按照推演流程来完成相关的操作,所以推演者感受非常明显。图1.9是“北约师指挥官”这款兵棋对抗式推演的基本流程。对抗双方需要严格按该流程完成相关的决策与操作。层级越低的手工兵棋,推演流程往往规定越细致,分队级的兵棋中甚至会规定推演各方每个回合中每一类行动的次数,譬如,每个回合的火力射击时节只能够进行X次间瞄射击、只能够进行X次机动等。而计算机兵棋(并非计算机化的手工兵棋)中,即使采用回合制推进,对抗各方也不再是交替决策和指挥,各种行动主要是按指定的时间来模拟和裁决,行动命令不需要按严格的次序来下达,因此推演者对此感受不深。尤其是实时制的计算机兵棋中,通常不再规定具体的推演流程。但是,对于每一类行动的模拟,需要根据行动分辨率来确定其基本的逻辑流程,合理地反映该行动的机理,只是这已经不属于推演规则,而是属于行动的逻辑规则。
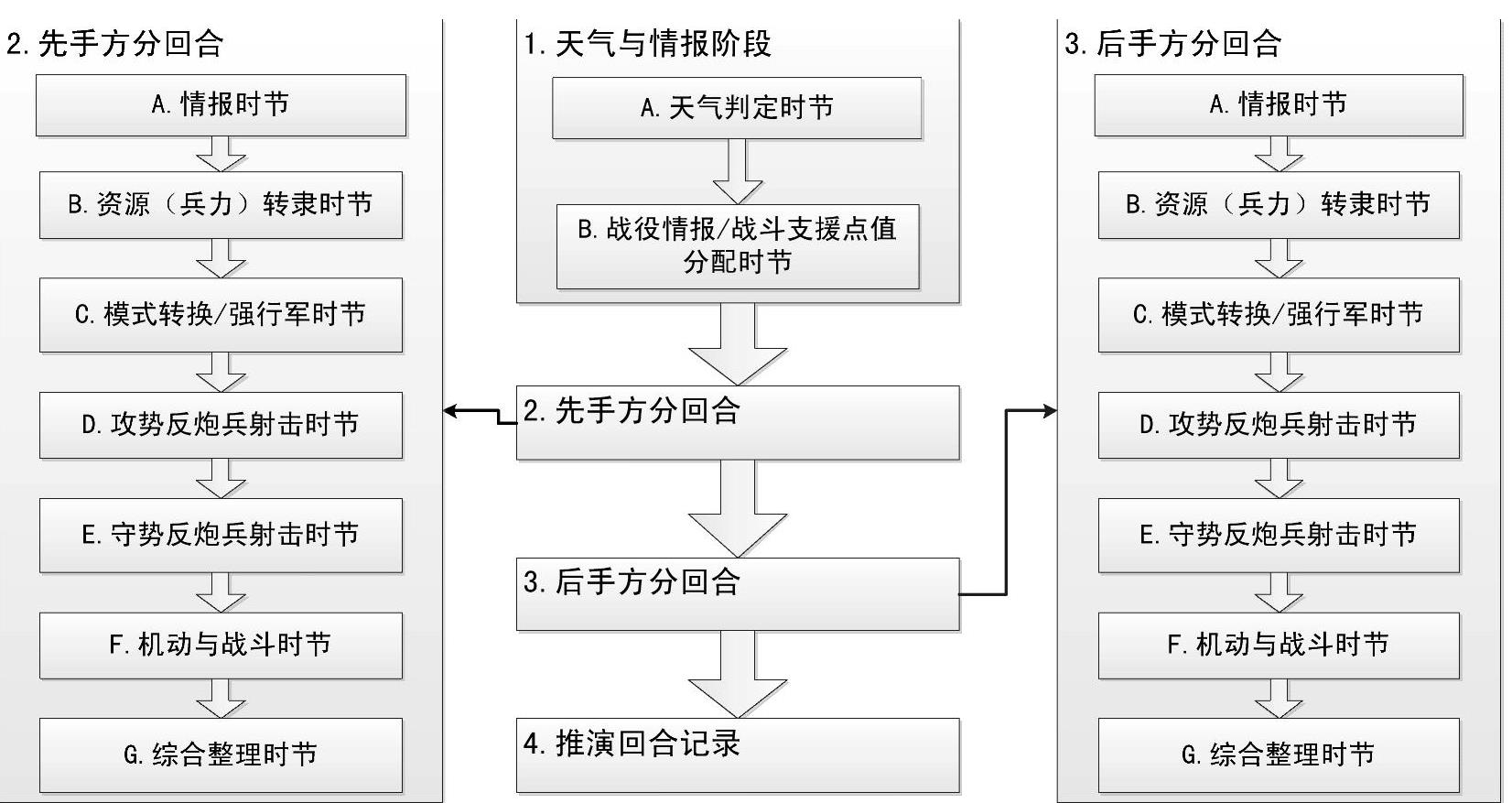
图1.9 “北约师指挥官”对抗式推演基本流程
需要注意的是,有的观点认为按回合制运行是兵棋的必要条件,这是值得商榷的。在辨析这一观点之前,需要先简要了解模拟(仿真)的基本原理[32]。模拟(仿真)可分为“连续时间”型和“离散时间”型,除了各种控制类模拟可能采用连续型之外,多数作战模拟都是属于离散型,譬如美军的JTLS系统就是属于离散型模拟。离散型模拟按照其推进机制又进一步可分为“时间步长”型和“事件驱动”型。时间步长型,就是模拟过程按照固定的时间步长推进,模拟的层级越高,通常时间步长值越大,战略层级模拟系统的时间步长可能是几小时甚至几天;相反,模拟的层级越低,时间步长值越小,战术层级模拟系统的时间步长可能是几分钟,在模拟某些高技术武器装备时可能是以秒甚至微秒为时间步长。事件驱动型模拟中,事件的发生是瞬时的,而任何一项活动是由两个瞬间事件决定的,即活动开始时的事件和结束时的事件;系统状态的变化发生在规定时间内,由事件而引发。模拟时间的推移会受到事件发生顺序的驱动,总会进行到下一个重大事件的时间点,所以不需要准确跟踪事件之间的时间推移。以地面机动为例,在事件驱动型模拟中机动开始和机动结束(暂停)都是一个事件,发生在瞬间,该机动单位的状态变化是发生在这两个事件之间的,系统只受到这两个事件的驱动,不详细跟踪机动过程。事件驱动型的模拟系统,相对于时间步长驱动型而言,模拟速度相对较快,对于计算资源的利用更为高效。但是,单纯的事件驱动型模拟系统,无法顺畅地表示模拟时间中同时发生的多项活动。还以地面机动为例,单纯的事件驱动型模拟将无法准确地模拟机动过程中遭受敌方火力或兵力攻击的事件。因此,离散型模拟,如果是时间步长型,通常需要为各种作战实体建立事件表,推进到某一时间点时先检查其事件表,如果没有事件需要触发则立即跳过,从而节省资源、提高速度;而事件驱动型,则通常需要维持模拟时间与事件速度的同步,确保在两个预定事件之间的模拟时间中,发生的其他相关事件可以得到处理,这可称为复合型。实际上,多数作战模拟系统都是属于复合型驱动的离散仿真。仍然以地面机动为例,作战模拟如果采用时间步长推进,则通常是在各个时间点根据其机动模型或规则计算该机动单位当前的位置信息,如果采用事件驱动,则需要在该机动单位预定的机动开始与机动结束之间将机动过程与模拟时间进行同步。特别要注意的是,即使建立了以时间(t)为参数的地面机动数学模型,在离散型模拟中其实也进行了离散化处理,只是根据时间步长计算出各个离散时间点当前的位置,而不能认为是连续时间型模拟。
无论是连续型还是离散型模拟,无论是时间步长型离散模拟、事件驱动型离散模拟还是复合型离散模拟,都是针对模拟(仿真)系统内部的运行而言的。而手工兵棋采用回合制,是对抗过程的一种抽象,其目的是确保对抗双方决策机会的公平,就如同象棋、围棋中“轮流落子”一样。在手工兵棋中,“回合”既是兵棋内在的推进机制,也是兵棋外在的推演机制。而计算机兵棋中,系统内部的推进机制,与系统外部的推演机制已经成为了两个相互关联但又性质不同的问题。就推演机制而言,回合制的典型表现形式是在推演各方下达行动指令的时候,模拟(作战)时间是暂停的,在推演各方下达完命令以后进行行动模拟与裁决时通常不能够同时下达命令,需要等到一个回合的模拟结束后才能够下达下一回合的命令。毫无疑问,回合制推演的计算机兵棋,其内在机制只能是离散仿真,但既可以是时间步长型也可以是事件驱动型。而与回合制推演相对应的,则是在推演各方下达行动指令的时间,模拟(作战)时间是按一定比率在运行的,推演人员可以持续地下达命令,对于出现的状态即时进行处置,可以称之为实时制(或连续型)推演。实时制推演的计算机兵棋,其内在机制理论上可以是连续仿真或者离散仿真,但由于受模拟速度、计算资源的限制通常也是采用离散仿真,同样既可以是时间步长型也可以是事件驱动型。也就是说,回合制推演是与实时制(或连续型)推演相对应的,而不是与连续仿真或离散仿真相对应。(https://www.xing528.com)
计算机兵棋(并非计算机化的手工兵棋)中,设计人员往往会将各种典型行动(活动)的持续时间(步长)设计为回合时间的倍数关系。譬如,如果联合战术层级兵棋的回合长度为1小时,则各种典型行动(活动)的持续时间(步长)通常都选择为0.5小时、1小时或2小时。其本质上就是上文所说的事件驱动型离散模拟中,需要维持模拟时间与事件速度的同步。但是,在这些计算机兵棋中,又人为地将这些典型行动(活动)在推演中的开始时间(事件)设定为回合开始时或回合的指定的时间点。这时候,好像“回合”和“时间步长”或“事件驱动”有机地结合起来了,似乎“回合制”与“时间步长”或“事件驱动”是对应关系了,也是系统内部的一种运行机制了。其实这是一种错觉。如果不强行设定这些行动(活动)在推演中的开始时间(事件)只能是指定的时间点,就会发现兵棋内部的行动模拟只能是按时间步长或者事件驱动而推进,与“回合”没有联系,此时的“回合制”仅仅是推演组织过程中的一种“暂停”,又回到了系统外部的推演机制,而并非系统内部的运行机制。实际上,几乎所有实时制(连续型)推演的计算机模拟系统,技术上都可以支持所谓的“回合制”推演,设定按“回合”的时间长度自动暂停,在暂停时允许各推演方输入命令即可。例如,美军的JTLS系统,通常是实时制(连续型)推演,但是也可以按作战阶段进行推演,如果将作战阶段按固定的时间长度来切分,就变成了“回合制”推演。因此,在计算机兵棋中,“回合制”仅仅是一种推演组织实施的机制,与系统本身并没有必然联系,也不能认为“回合制”是兵棋的本质特征。
定性判断为主的逻辑规则,通常是在对各种行动进行抽象,确定其详细模拟程度的基础上,形成限制各种作战力量及其行动的规定。通常可以分为三种:一是限定各种力量能执行什么行动、不能执行什么行动。主要是根据各类部(分)队及武器装备的物理特性所做的规定。譬如,坦克、步战车等各种地面车辆不能自行上天、舰艇不能上岸、飞机不能下潜;战斗机、轰炸机不能搭载人员和装备实施运输及空(机)降行动等。二是限定什么条件下能执行什么行动、什么条件下不能执行。譬如,各种车辆、舰艇、飞机等必须有燃油才能出动,燃料消耗完以后如果没有补充就不能再次出动。三是各种条件对相关行动的影响程度。譬如各种地形条件对不同单位(车辆)机动速度的影响,各种气象天候境况对于各种武器系统侦察发现概率、射击命中概率等。此外,还根据国际和各国有关战争政策法规提出一些限定性规定,这也体现为逻辑规则。
仅有定性的逻辑规则是不够的,尤其是后两种定性的逻辑规则,通常还必须结合数据才能支撑行动的模拟与裁决,也就是在定性的基础上通过数据进行定量的描述。譬如,不同单位(车辆)的机动速度,不仅要规定受到哪些地形因素的影响,还需要确定反应各种因素具体影响程度的数值。当然,各种作战力量或战场地物,需要先确定考虑哪些能力参数,再确定这些能力参数的具体数值,前者可以归为逻辑规则,后者则可以归为数据规则。尤其是具体行动的效果裁决,往往定性的逻辑规则与定量的数量是结合在一起的。但是,在计算机兵棋中,通常需要在编程时将数据与逻辑规则完全分离开,在程序源代码中只建立参数变量,不赋予具体数值,各种数据都在程序源代码之外单独存放。这样,既便于根据武器装备的发展和实践经验的积累而及时修改相关的数据,也便于数据的保密,甚至可以根据兵棋推演的目的而选择不同的数据体系。
兵棋的规则,通常是以便于军事人员理解的语言加上数据、表格来表示,而不是大量的数学模型。当然,兵棋的规则中,也可以包含一些必要的数学模型,尤其是经典的物理模型。譬如,地面机动或飞行的模拟,最基本的路线和航迹可以利用数学模型来计算,但必须加上其他的规则来体现地理因素之外的其他影响。与“modeling and simulation”对比,后者的军事概念建模对于设计兵棋定性的逻辑规则具有明显的帮助作用,而建模与仿真的结果则可以作为兵棋裁决表的重要依据之一。在手工兵棋中,各种作战行动的结果判定通常采用查表的方式来完成。各种裁决表的基本原理类似于炮兵射击时使用的“射表”,即针对各种可能的战场情况,提前准备好各种事件可能出现的“结果分布表格”。在计算机兵棋中,不一定全部都采用查裁决表的方式来判定各种行动的结果,尤其是像地面(兵力)作战,很难将各种可能的结果都“穷举”出来并形成分布表格。但是,很多行动,尤其是某些行动中某些环节的结果判定仍然采用裁决表的方式。一方面,有些影响因素可以通过建模进行量化计算,如武器性能、弹药消耗速度等,但是有一些影响因素难以建立准确的数学模型,如心理、疲劳、士气、荣誉、恐惧等,需要基于以往战争、演习、实验、训练数据的总结、提炼和抽象来形成裁决表,综合体现各种因素影响之下可能的结果分布,从而避免因为忽视了这些难以建模量化的因素而导致结果的失真。另一方面,通过模型的实时计算来判定行动结果,军事人员将难以直观了解裁决的过程及其原理,既难以理解裁决的结果,也难以通过对模型的学习来获得军事指挥经验,而裁决表则比较直观地体现了各种行动的影响因素及其效果,便于军事人员理解和相信裁决的结果,并通过对逻辑规则和裁决表的学习来获得军事指挥经验。美军JTLS中地面交战的结果裁决主要依靠拟合的“兰彻斯特方程”,而各种空间机动、地面防空、空中对抗、精确(非精确)火力毁伤等主要是在详细分解各种行动流程的基础上,通过查裁决表进行判定。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。