



通过7.2.1一节的学习,我们输入start-thriftserver.sh命令,Spark SQL Thrift Server启动时调用org.apache.spark.deploy.SparkSubmit,SparkSubmit向服务器集群提交一个class为HiveThriftServer2的应用程序,HiveThriftServer2类是一个Spark应用程序,也是main方法的入口类,因此,很有必要对其进行解析。
下面是HiveThriftServer2的UML类图,如图7-3所示。
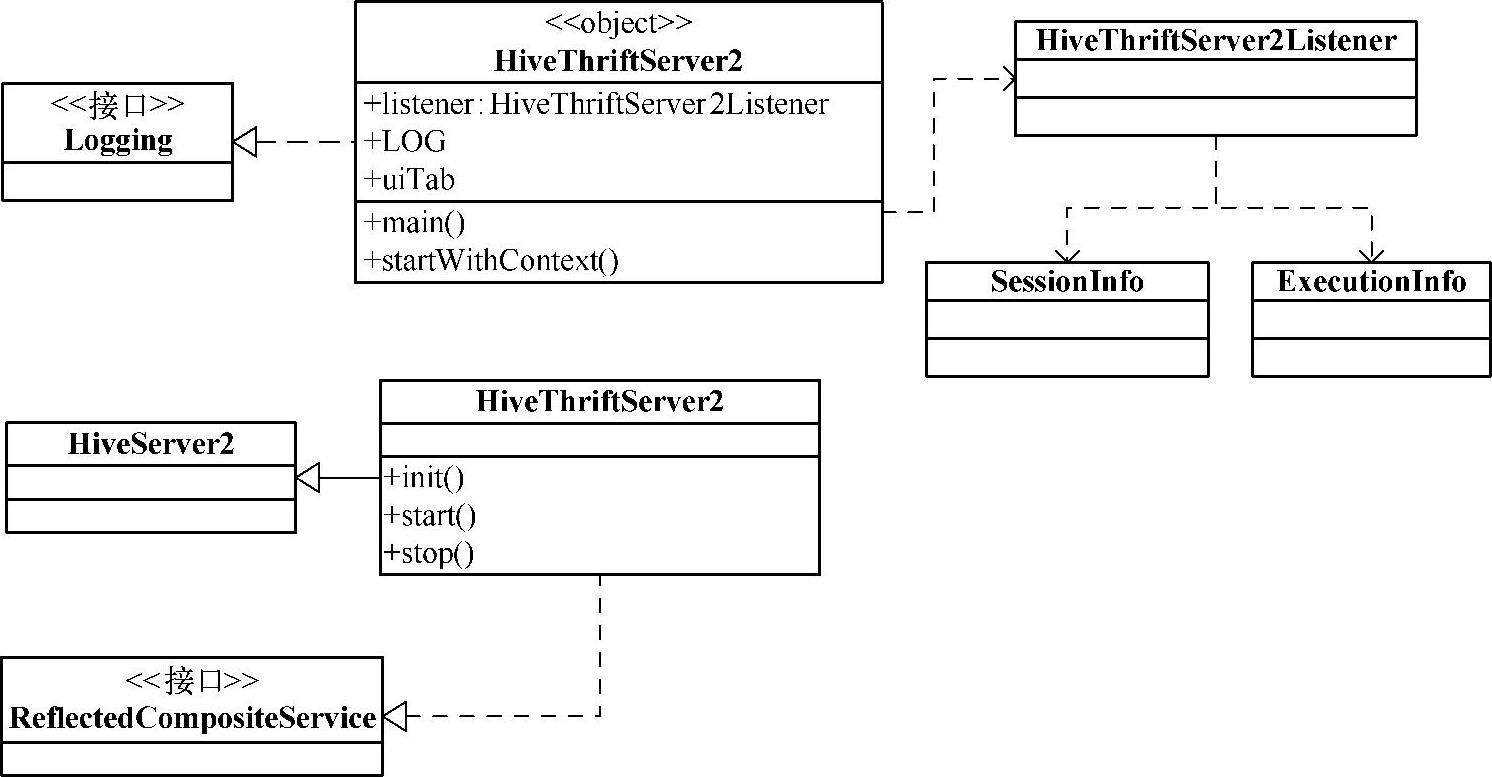
图7-3 HiveThriftServer2UML类图
伴生对象object HiveThriftServer2继承至Logging,是Spark SQL中连接HiveServer2的主入口点,启动SparkSQLContext和HiveThriftServer2thrift server服务。伴生类class HiveThrift-Server2继承至HiveServer2及ReflectedCompositeService,其中HiveServer2是Hive包中的类org.apache.hive.service.server.{HiveServerServerOptionsProcessor,HiveServer2}。
下面是主要的几个关键点。
1.init方法

HiveThriftServer2继承了Hive的HiveServer2和ReflectedCompositeService两个类,并且复写了init方法。在初始化(HiveConf)的时候,会添加cliService和thriftCLIService两个服务,作为后台守护进程。其中,cliService服务是SparkSQLCLIService对象的实例;thrift-CLIService服务在实例化时,会根据HiveConf参数进行判断,如果传输模式是HTTP,就使用ThriftHttpCLIService对象,否则使用ThriftBinaryCLIService对象。ThriftHttpCLIService和ThriftBinaryCLIService都是ThriftCLIService的子类,无论是哪个ThriftCLIService对象,都传入了SparkSQLCLIService的引用,Thrift只是一个封装。
在添加这两个服务之后,再调用initCompositeService方法,把所有的服务启动起来。
2.监听器(https://www.xing528.com)
在HiveThriftServer2伴生对象中,有一个listener对象作为监听器,它是HiveThriftServ-er2Listener类的实例。listener用来接收远程的请求,向SparkContext注册该监听器,把接收到的请求交给HiveThriftServer2类,再通过Spark SQL去执行任务。
3.main方法入口
在HiveThriftServer2伴生对象中,还有main函数入口。正如Thrift Server启动日志所见:


从Spark Command可以发现,启动Thrift Sever时,实际是调用SparkSubmit来提交HiveThriftServer2类的,所以该类必须要有main方法入口,用来创建一个新的进程。
在main方法中,主要处理逻辑是:创建HiveThriftServer2实例,以及创建HiveThrift-Server2Listener监听器。具体代码如下:


免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。