



Thrift Server启动的时候,其实是启动了一个Spark SQL的应用程序,同时开启一个侦听器,等待JDBC客户端的连接和提交查询。所以在配置Thrift Server的时候,可以在配置文件中配置Thrift Server的主机名和端口,如果要使用Hive数据的话,还要提供Hive Metastore的uris。通常,可以在conf/hive-site.xml中定义以下几项配置,也可以使用环境变量进行配置(环境变量的优先级高于hive-site.xml)。
我们查看一下本示例的hive-site.xml配置:

在当前hive-site.xml中只配置了Hive Metastore的uris的信息,其他配置采用默认配置。
接下来详细讲解Thrift Sever的启动过程。为了让大家深刻理解Thrift Server的启动过程,我们这里“挖一个坑”:
先把HDFS和Spark集群启动起来,但是此时先不启动Hive Metastore服务。为了稍后方便通过Spark Web控制台来查看Job的运行日志,此时需要把HistoryServer启动起来。
●在Hadoop目录下启动start-dfs.sh和start-yarn.sh,执行命令:
root@Master:/usr/local/hadoop/hadoop-2.7.1/sbin#./start-all.sh
●在Spark目录下执行命令:
root@Master:/usr/local/spark/spark-1.6.3-bin-hadoop2.6/sbin#./start-all.sh
●在Spark目录下启动HistoryServer:
root@Master:/usr/local/spark/spark-1.6.3-bin-hadoop2.6/sbin#./start-history-server.sh
●通过jps查看启动的进程,至少包含下面的进程:

此时我们特意没有开启Hive Metastore元数据服务。
1.尝试启动Thrift Server
为了启动Thrift Server,请在Spark目录运行下面的命令:

在命令终端上将会显示提示:正在启动HiveThriftServer2,并记录到对应的日志文件。
此时,我们可以通过VIM编辑器来打开该日志文件,命令如下:

可以发现日志中有异常信息。在74行处(以实际为准),可以看见有异常信息:

通过上面的日志信息,可以发现因为Hive的Metastore服务没有启动,所以导致访问Metastore失败。此处就是为了让大家要注意分析日志文件信息,Spark的很多日志文件信息,包括通过Web控制台都可以用来理解Spark的内部运行机制。
2.正常启动Thrift Server(以默认传输通道模式:binary模式)
1)首先,正常启动Hive Metastore服务,命令如下:
root@Master:/usr/local/spark/spark-1.6.3-bin-hadoop2.6#hive--service metastore&
或者也可以采用添加输出日志文件的方式启动:
hive--servicemetastore>Metastore.log 2>&1&
此时,通过ps命令查看Hive Metastore进程:

可以发现HiveMetaStore服务已经正确启动。
Metastore是Hive元数据的集中存放地,元数据包括表的名字、表的列和分区及其属性等,通常存储在关系数据库如MySQL、Derby中。
2)此时再次运行start-thriftserver.sh,执行命令如下:
root@Master:/usr/local/spark/spark-1.6.3-bin-hadoop2.6#./sbin/start-thriftserver.sh--
master spark://master:7077
打开spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-Master.out日志文件,没有发现异常信息。我们仔细阅读日志文件内容,尤其是下面这段日志内容很关键:(https://www.xing528.com)

通过上面这段日志信息,我们可以获知:启动Spark SQL Thrift Server,其实就是调用SparkSubmit向服务器集群提交一个class为HiveThriftServer2的普通Spark应用程序。
当然,我们直接使用Linux的ps命令也可以查看Thrift Server具体的运行信息,如下所示:

Thrift Server其实就是一个class为HiveThriftServer2的Spark应用程序。
3.以HTTP传输通道模式启动Thrift Server
Thrift Server的传输通道模式可以是Binary或者HTTP,通过HTTP传输通道,Spark SQL Thrift Server也支持发送Thrift RPC消息,这种方式在客户端和服务器之间支持代理中介是特别有用的(例如:负载均衡和安全原因)。
使用下面的配置以支持HTTP模式,如表7-1所示。
表7-1 使用HTTP模式的参数表

以上参数可以在JDBC Connection URLs系统参数中传入或者直接配置在Hive配置信息文件hive-site.xml中。
1)先停止刚才已经启动的Thrift Sever:

2)指定以HTTP模式再次运行start-thriftserver.sh,执行命令如下:

此时HTTP端口没有指定,默认值为10001,正如表7-1所示。
现在我们再次使用ps命令查看Thrift Server具体的运行信息,如下所示:


3)此时用netstat命令可以查看10001端口已经处于侦听状态:

当Thrift Server以HTTP模式启动后,就可以被beeling或者JDBC客户端程序通过HTTP通道模式来进行连接操作了。
4.查看ThriftServer命令参数
运行下面的命令:
root@Master:/usr/local/spark/spark-1.6.3-bin-hadoop2.6/sbin#./start-thriftserver.sh--help
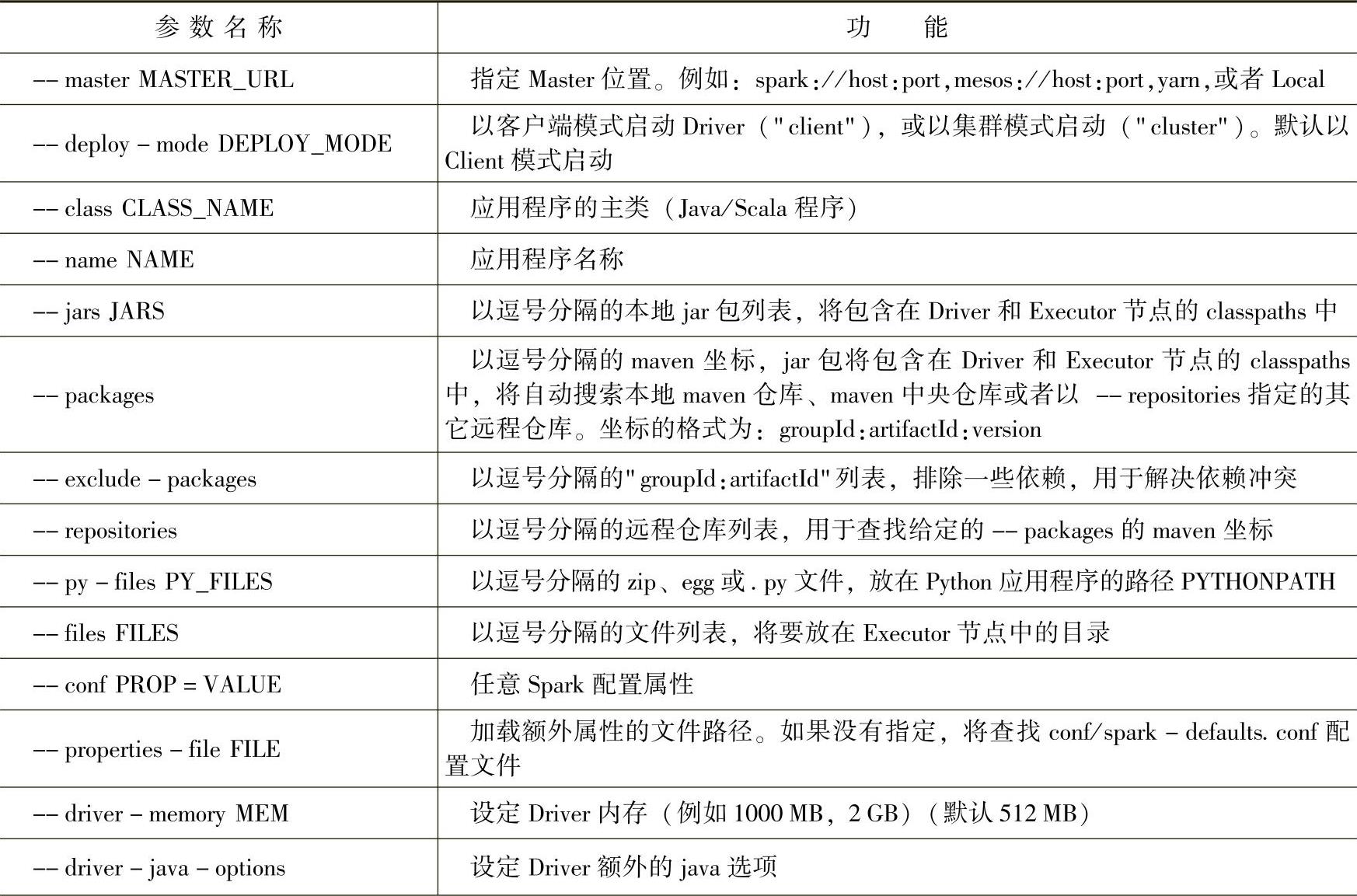
通过使用--help参数,可以列出ThriftServer的命令参数,如表7-2所示:
Usage:./sbin/start-thriftserver[options][thrift server options]
表7-2 ThriftServer命令参数
(续)

以上[options]参数列表,完全与spark-submit应用程序的参数一样,如果不设置master参数,Spark应用程序将在启动Thrift Server的机器中以local方式运行,可以通过ht-tp://机器名:4040进行监控。如果在集群中运行Thrift Server,一定要配置master、execu-tor-memory等参数。再通过hive-conf来指定[thrift server options]系列参数,因为参数比较多,通常使用conf/hive-site.xml进行配置。
5.退出Thrift Server
Thrift Server启动后处于监听状态,可以执行下面命令退出ThriftServer:
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。