



本节数学考试分数查询案例中,将综合应用Spark SQL的窗口函数,例如:row_number()、rank()、percent_rank()、tile、cume_dist、lag、lead等函数,统计班级内每位同学考试成绩的名次、百分比排名及相关统计功能:
1)将考试分数文件上传到HDFS系统(考试分数文件数据信息如表5-3所示)。
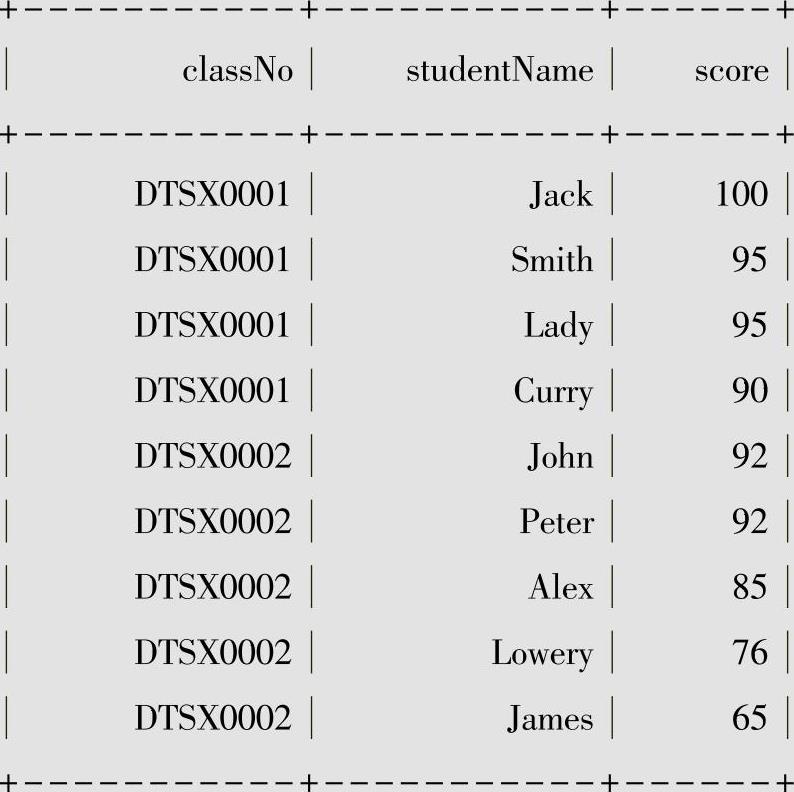
表5-3 考试分数数据信息

2)启动Hive metastore服务,启动Spark shell。
3)创建hiveContext,创建数据库表math_score,将HDFS分数文件加载到Hive数据库表中。
4)使用窗口函数查询班级内每位同学的考试排名情况。
1.将考试分数文件上传到HDFS系统并将HDFS分数文件加载到Hive数据库表
1)在HDFS中创建文件夹,代码如下。

2)将数据文件math_score.txt上传到HDFS中,代码如下。

3)启动Hive的metastore服务,代码如下。
4)进入Spark的sbin下启动Spark集群,代码如下。

5)进入Spark的bin目录下,采用./spark-shell--master spark://Master:7077启动Spark-Shell。
6)创建hiveContext上下文。

7)创建数据表,代码如下:

8)加载数据,代码如下:

查看数据结果如下:
2.使用窗口函数查询班级内每位同学的考试排名情况
在本节考试分数查询统计中,我们将使用Spark SQL的窗口函数row_number()统计班级内每位同学考试成绩的名次;分别使用窗口函数rank()、dense_rank统计学生的考试名次;使用窗口函数percent_rank()进行百分比排名;使用窗口函数ntile函数将分组数据按照顺序切分成n片;使用窗口函数cume_dist函数计算小于等于当前值的行数占分组内总行数的比例;使用窗口函数lag函数用于统计窗口内往上第n行的值;使用窗口函数lead函数统计窗口内往下第n行的值。
(1)def row_number():Column
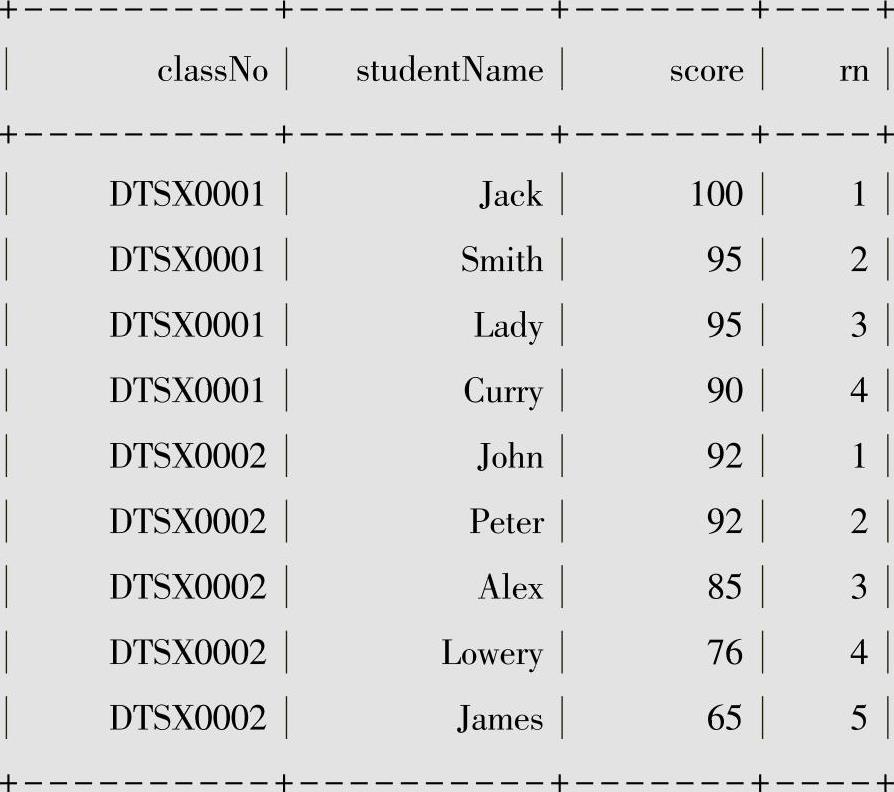
该函数会从1开始按照由小到大的顺序生成分组内记录的序列。比如,我们按照成绩降序排列,生成每个班级内每位同学成绩的名次,代码如下:

执行结果如下:
ROW_NUMBER()的应用场景非常多,通常可以用于Top N排名的统计,例如网易云音乐按照不同的音乐类别统计出榜单的TOP 10。在这里需要找出每个班级中成绩排名前三名的学生,代码如下:

(2)def rank():Column和def dense_rank():Column
row_number虽然能进行排名,但是在排序中出现相同值(例如并列第一名)的情况下仍依次排序,我们可能会分别采用rank和dense_rank进行排名,而这会对整个排名会产生一定的影响。rank函数在遇到排名相等的情况下会在名次中留下空位;而dense_rank在排名相等时在名次中不会留下空位。
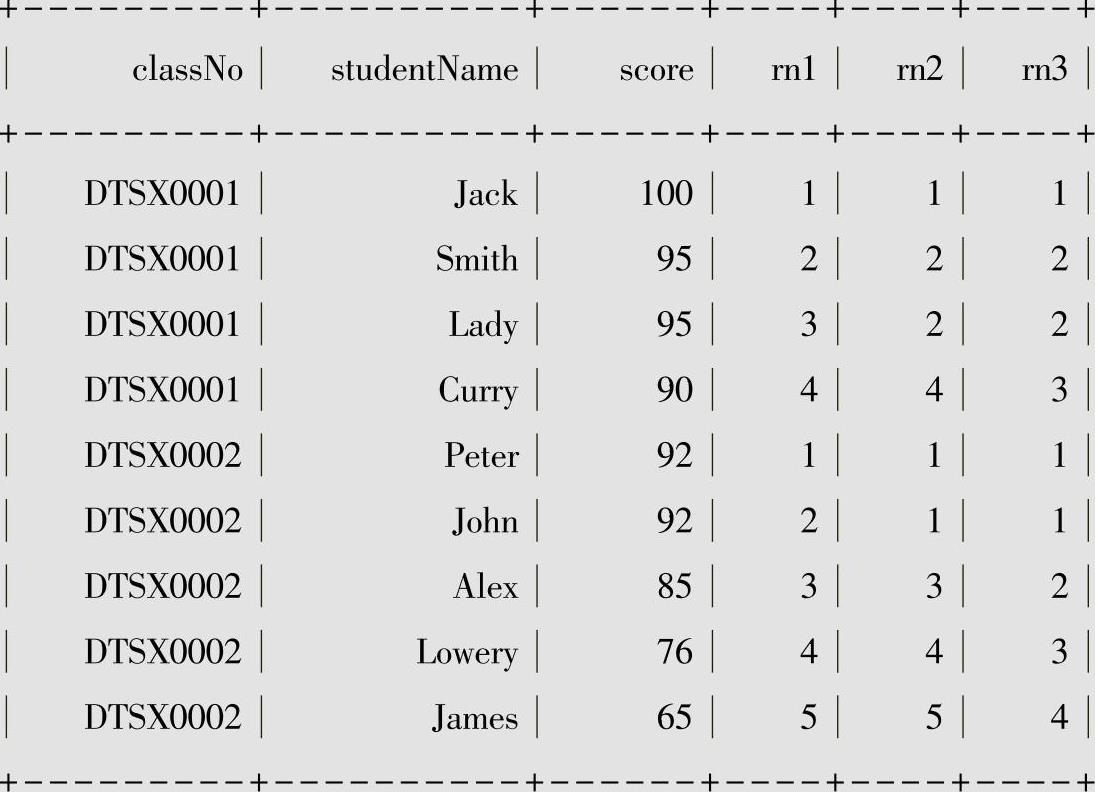
我们分别用3个窗口函数row_number()、rank()、dense_rank()函数对考试分数进行排名统计。
row_number()、rank()、dense_rank()窗口函数分别查询统计如下:


执行结果如下:
 (https://www.xing528.com)
(https://www.xing528.com)
●rn1列是row_number函数作用的结果。
●rn2列是rank函数作用的结果;班级号为DTSX0001的班级中,Smith和Lady同为95分,并列排名第2,由于前两名有3人,会在第3名留下空位,所以Curry排名第4,后续的排名按照这个规则进行排名。
●rn3列是dense_rank函数作用的结果;班级号为DTSX0002的班级中,Peter和John同为92分,并列第一,而后续的排名不会留下空位,即使有多人并列排名,Alex在有两个并列第一的情况下仍然排名第2。
(3)def percent_rank():Column
percent_rank函数是在分组内中计算:当前记录的rank值-1/分组内总行数-1。rank_列计算使用窗口函数rank()计算班级中每位同学的排名;count_列计算每个班级的同学总人数;percent_rank()列计算当前记录的rank值-1/分组内总行数-1的百分比排名。

执行结果如下:
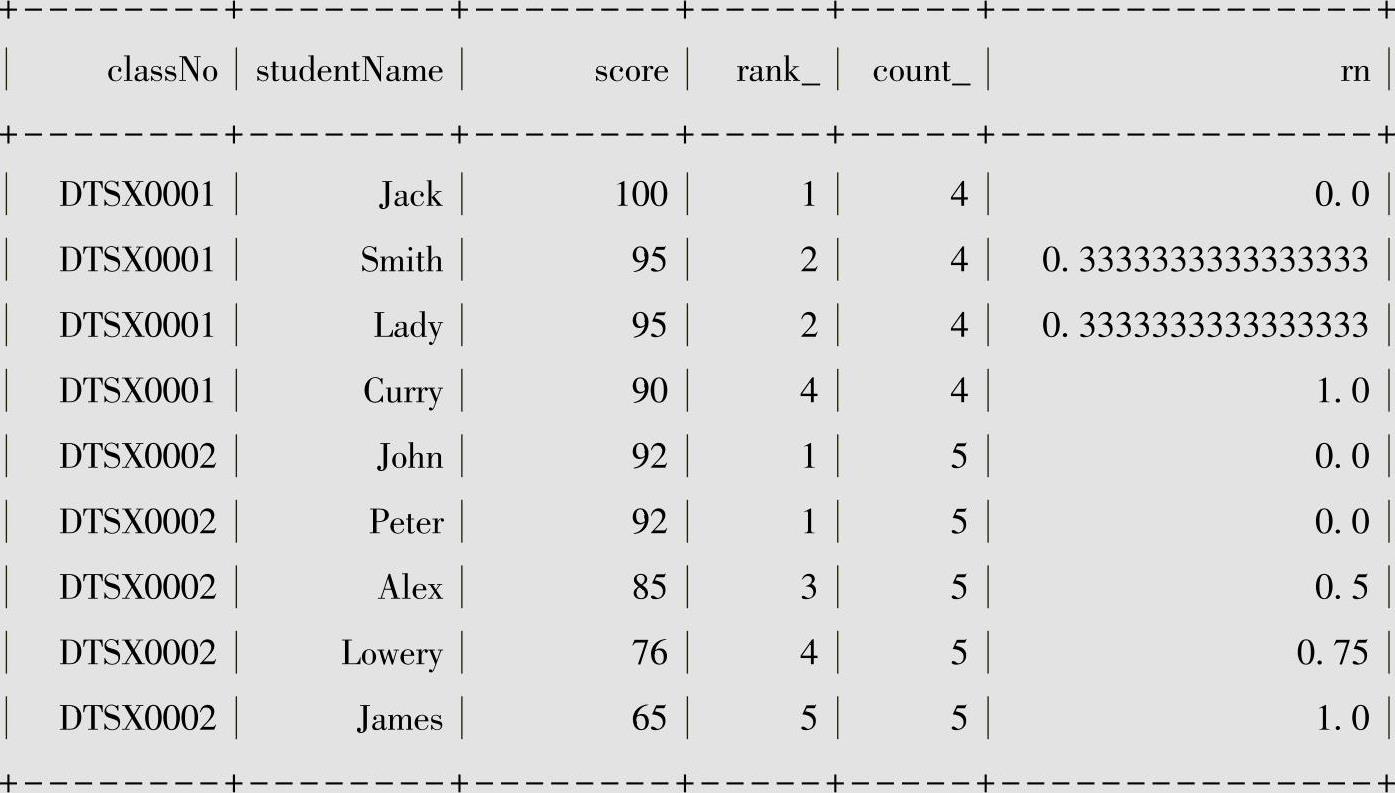
例如,DTSX0002中的Alex的percent_rank函数下值为(3-1)/(5-1)=0.5,说明Alex考试分数的排名情况,即班级DTSX002有50%(一半)学生排名在Alex之前。
(4)def ntile(n:Int):Column
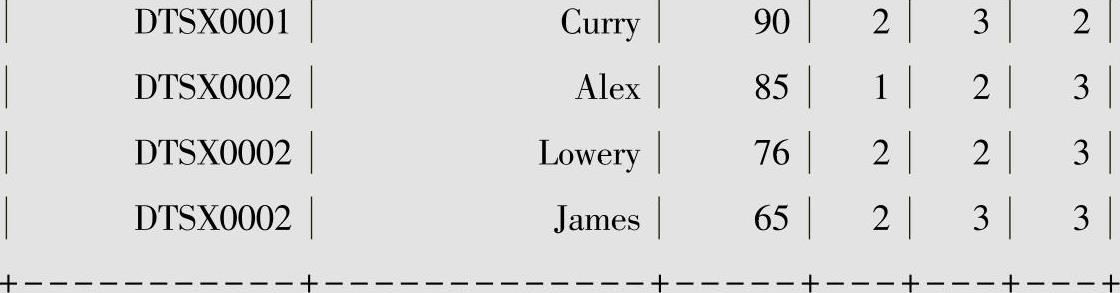
ntile函数用于将分组数据按照顺序切分成n片,返回当前所在的切片值,如果切片不均匀,则默认增加第一个切片的分布。窗口函数ntile(2)将分组内所有数据分成2片,以及按classNo分区,返回当前所在的切片值作为rn1列;窗口函数ntile(3)将分组内所有数据分成3片,以及按classNo分区,返回当前所在的切片值作为rn2列;窗口函数ntile(3)将分组内所有数据分成3片,返回当前所在的切片值作为rn3列;

执行结果如下:
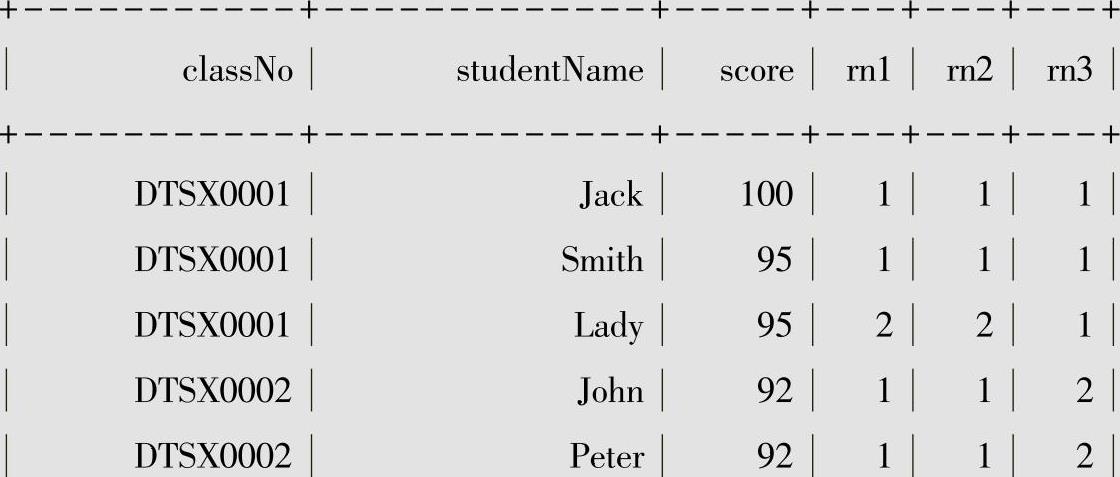
●rn1是根据班级号分组的,然后按照成绩由高到低排序后切片成2份。
●rn2是根据班级号分组的,然后按照成绩由高到低排序后切片成3份。
●rn3把所有记录作为一个组,然后按照成绩由高到低排序后切片成3份。
以列rn1为例,即以班级号为DTSX0001这一组为例,该组一共4条记录被切分成2份,这样每个分片有两条记录,所以在该组中,Jack和Smith的成绩位于第一个分片,值为1,Lady和Curry的成绩位于第二个分片,所以值为2,这是均匀切片的情况。
我们来看不均匀切片的情况,在班级号为DTSX0002这一组中总计5条记录被切片成2份,5除以2余1,这一条记录加入在第一个分片中,就变了第1个分片有3条记录,第2个分片有2条记录,所以John、Peter、Alex的成绩位于第1个分片中,分片值为1,Lowery和James位于第2个分片中,所以分片值为2。
5.def cume_dist():Column
cume_dist函数用于计算小于等于当前值的行数占分组内总行数的比例,这在实际业务场景中非常常见,比如,统计小于等于当前薪水的人数所占总人数的比例。使用窗口函数cume_dist()统计考试分数在Lowery同学分数之前的人数在总人数的占比,作为rn1列;使用窗口函数cume_dist()及使用PARTITION BY按班级分组,统计考试分数在Lowery同学分数之前的人数在班级分组人数的占比,作为rn2列。

执行结果如下:
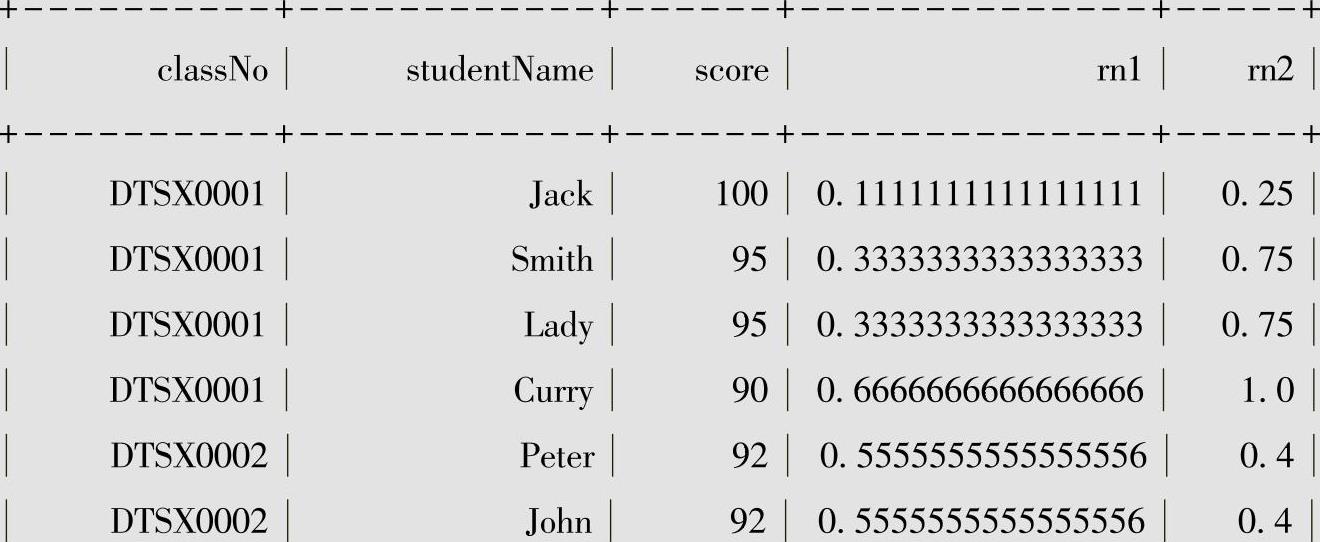

●列rn1是把当前所有记录作为一组的,按成绩由高到低来计算cume_dist的值。
●列rn2是根据班级号分组的,按成绩由高到低来计算cume_dist的值,例如班级号为DTSX0002这一组中分数按降序排列,对于Lowery而言,排在76分前之前的记录数有4条,DTSX0002的总记录条数为5条,所以该行的cume_dist值为4/5=0.8。
(6)def lag(e:Column,offset:Int,defaultValue:Any):Column
lag函数用于统计窗口内往上第n行值;第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)。使用窗口函数row_number()计算班级中每位同学考试分数的排名,作为rownum列;使用窗口函数lag(score,1)获取班级中分数在此同学分数之前1位的同学的分数,作为rn1;使用窗口函数lag(score,2)获取班级中分数在此同学分数之前2位的同学的分数,作为rn2。

执行结果如下:
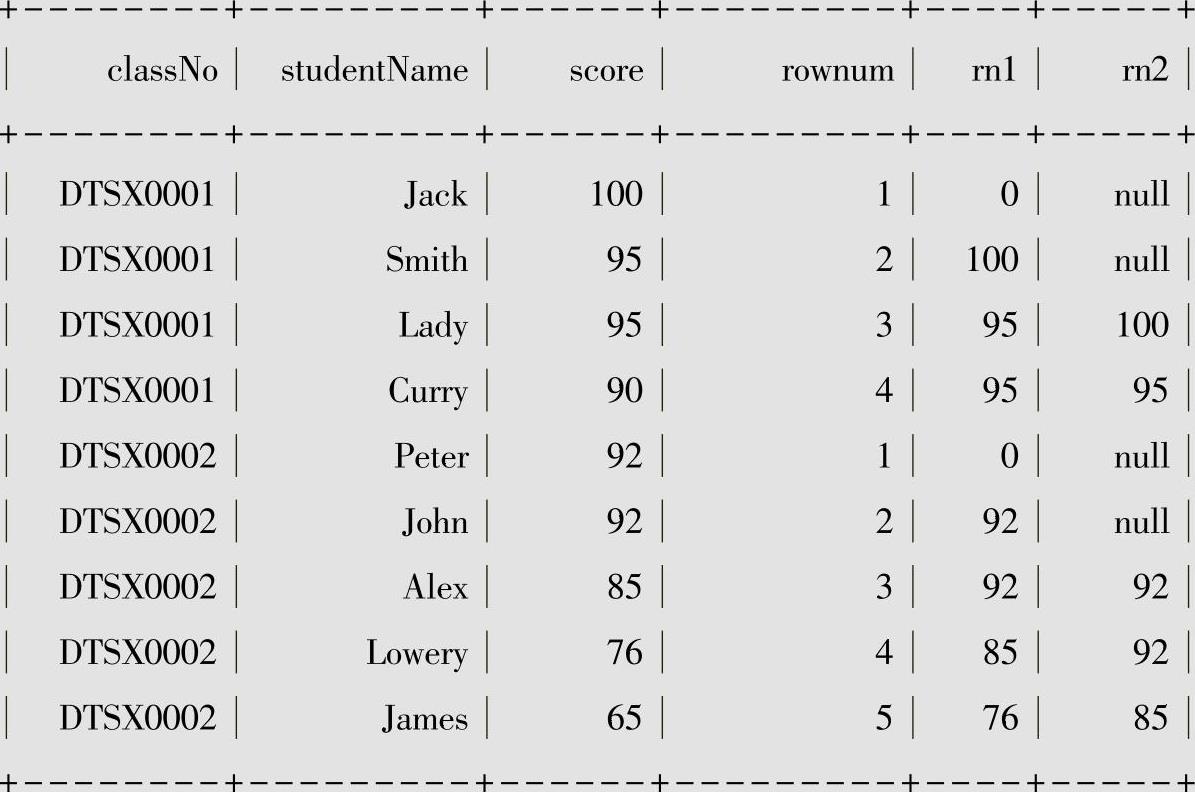
●列rn1是根据班级进行分组的,按成绩由高到低来计算lag函数的值,例如在班级号为DTSX0001这个组中对于成绩最高的Jack来说,往上1行不存在,所以此时的值为我们设置的默认值为0,对于Smith来说往上1行为Jack的记录,所以lag的值为100。
●列rn2是往上查找两条记录,比如在班级号为DTSX0002的这一组中,对于John来说,往上两行不存在,且没有设置默认值,此时为NULL,对于James来说,往上查找两行为Alex的记录,所以lag值为85。
(7)def lead(e:Column,offset:Int,defaultValue:Any):Column
lead与lag相反,该函数用于统计窗口内往下第n行值:第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如果不指定,则为NULL)。使用窗口函数row_number()计算班级中每位同学考试分数的排名,作为rownum列;使用窗口函数lead(score,1)获取班级中分数在当前的同学分数之后1位的同学的分数,作为rn1;使用窗口函数lead(score,2)获取班级中分数在当前的同学分数之后2位的同学的分数,作为rn2。

执行结果如下:
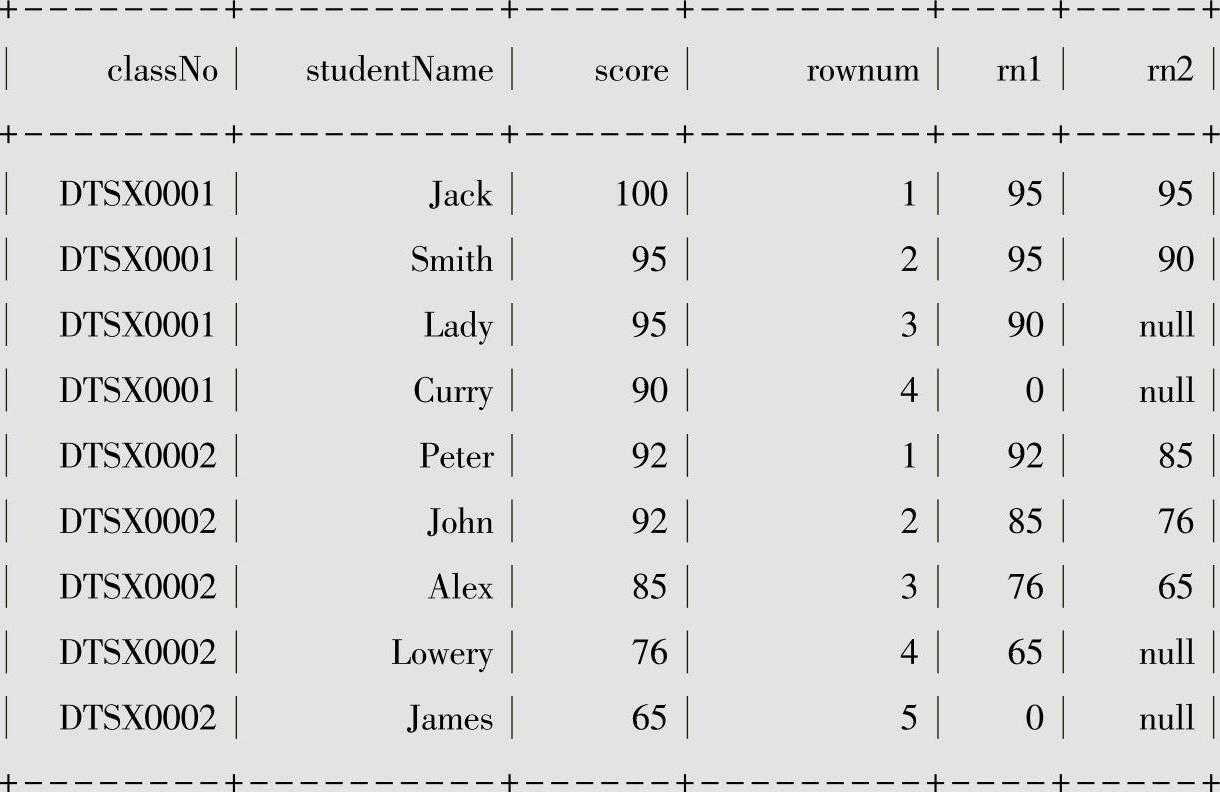
列rn1是根据班级进行分组,获取班级中分数在当前的同学分数之后1位的同学的分数,例如在班级号为DTSX0001这个组中对于成绩最高的Jack来说,往下1行为Smith的记录,所以lead的值为95;对于Curry来说往下1行不存在且有设置默认值,此时为0。
列rn2是往下查找2条记录,比如在班级号为DTSX0002的这一组中,对于Lowery来说往下2行不存在且没有设置默认值,此时为NULL,对于Alex来说往下查找2行为James的记录,所以lead值为65。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。