



窗口函数,也可以称之为开窗函数或者分析函数。窗口函数(OVER子句)为行定义一个窗口(将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。相对于窗口函数,SQL聚合函数以GROUP BY查询对一组值进行聚合(例如sum,avg,count等操作),对数据进行分组后,对每个组查询只返回一行数据,不能同时返回基础列的数据,只能得到聚合列。
一般来说,传统的关系型数据库在聚合操作之后的行数都要小于聚合前的行数,对于窗口函数而言,操作前后的行数都是相等的。例如,我们要根据不同手机品牌下的不同型号进行分类并统计其个数,比如苹果手机有5种不同型号,华为手机有4种不同的型号,采用聚合函数统计时会产生两条记录,而采用窗口函数统计则会生成9条记录,即每一行都会产生窗口函数的结果。
在窗口函数出现之前存在着很多用SQL语句很难解决的问题,往往很多复杂的查询都要通过相关子查询或者复杂的存储过程来完成。直到后来一些传统意义上的关系型数据库引入了窗口函数,使得这些复杂的查询变得尤为容易。所谓窗口就是指用户指定的一组行。窗口函数计算从窗口派生的结果集中各行的值,分别应用于每个分区,并为每个分区重新启动计算。
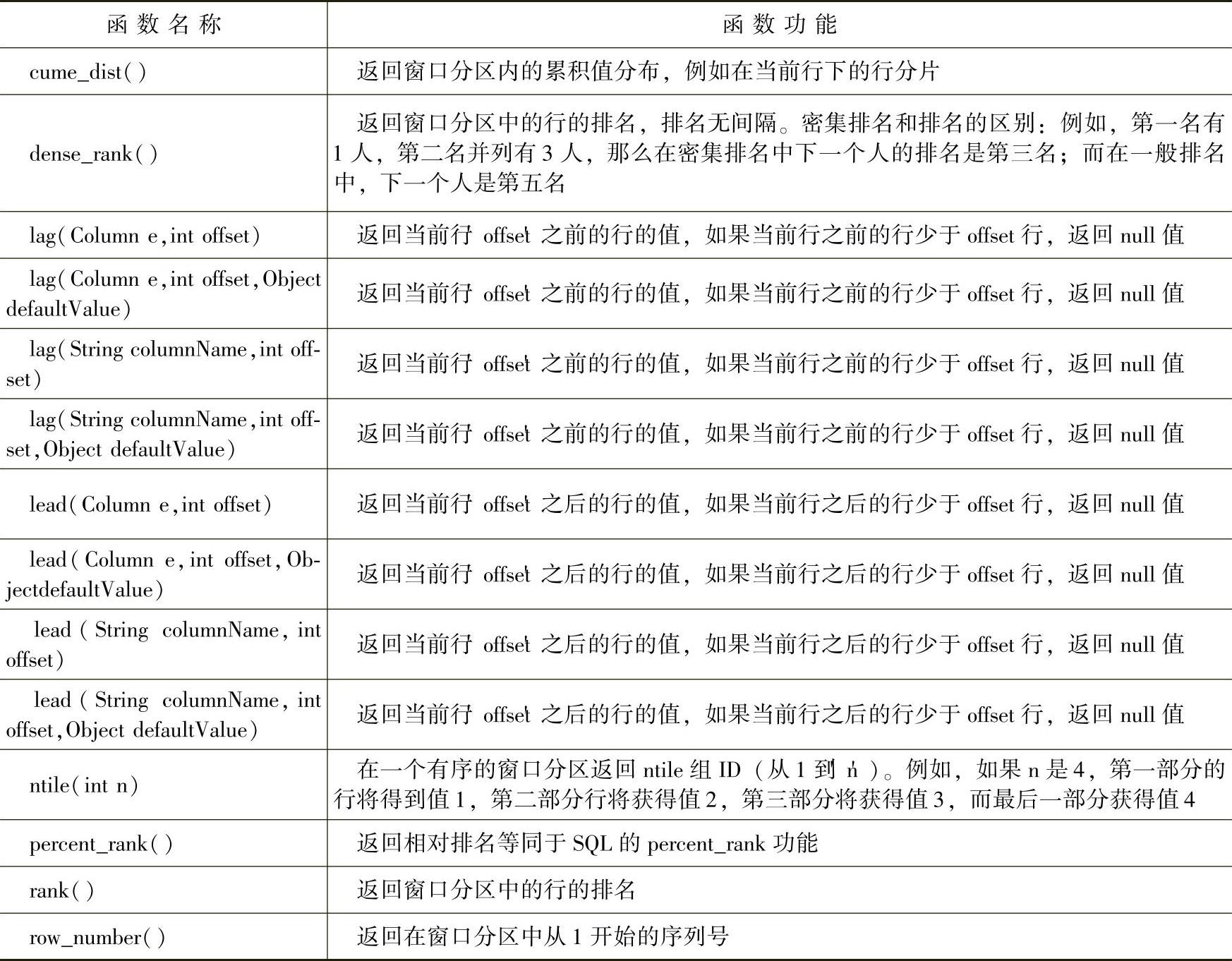
Spark SQL也为我们提供了大量的窗口函数,如表5-2所示:
表5-2 常用的窗口函数
 (https://www.xing528.com)
(https://www.xing528.com)
Spark SQL窗口函数的语法如下:
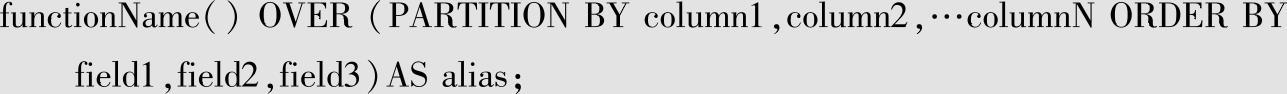
OVER关键字表示把函数当成窗口函数而不是聚合函数。对于查询结果的每一行都返回所有符合条件的行的条数。OVER关键字后的括号中还经常添加选项,用于改变进行聚合运算的窗口范围。如果OVER关键字后的括号中的选项为空,则窗口函数会对结果集中的所有行进行聚合运算。
从语法层面上来看,Spark SQL窗口函数和传统的关系型数据下的窗口函数的写法基本一致。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。