



1.列式存储
列式存储指数据是按列存储的,每一列数据单独存放,列式存储以流的方式在列中存储所有的数据,主要适合批量数据处理和即席查询。
下面看一个行式存储及列式存储的示意图,如图4-1所示。
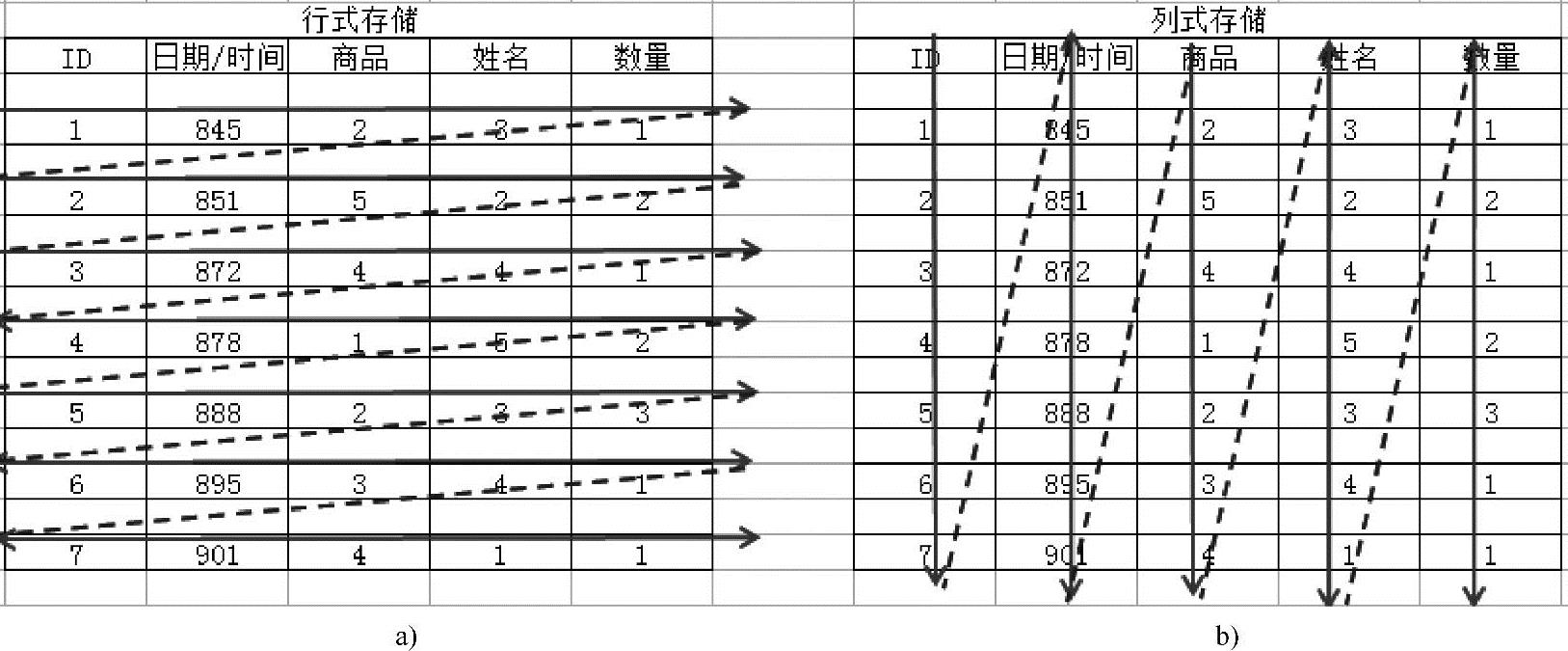
图4-1 行式存储及列式存储示意图
a)行式存储 b)列式存储
图4-1中左侧的表格基于行式的存储,如表4-1所示。
表4-1 行式存储

图4-1 中右侧的表格基于列式的存储,如表4-2所示。
表4-2 列式存储

从图4-1可以看出,基于行式的存储,依次存储每一行的数据,一张表的数据存放在一起。但列式存储的数据是按照列存储的,每一列单独存放,数据即是索引。如数据查询时只访问查询涉及的列,大大降低了系统I/O,而且由于数据类型一致,方便压缩。(https://www.xing528.com)
Parquet是一种支持嵌套数据的列式存储格式。Parquet元数据使用Apache Thrift进行编码。Parquet-format项目包含创建Parquet文件的readers及writers所需的所有Thrift定义。Parquet为Hadoop生态系统中的任何项目提供可压缩的列式数据表达、Parquet使用“record shredding and assembly algorithm”(基于Dremel的论文)算法来表示复杂的嵌套数据类型,通过列式压缩和编码技术降低了存储空间,提高了I/O效率。
2.Parquet的3个核心组成部分
1)Storage Format(存储格式):定义了Parquet内部的数据类型和存储格式。
2)Object Model Converters(对象模型转换器):负责数据对象和数据类型之间的映射。这部分功能由parquet-mr项目来实现,主要完成外部对象模型与Parquet内部数据类型的映射,映射完成后Parquet会进行自己的Column Encoding,然后存储Parquet格式文件。
3)Object Models(对象模型):在Parquet中具有自己的Object Model定义的存储格式,例如,Avro具有自己的Object Model,但是Parquet在处理相关格式的数据时会使用自己的Object Model来完成具体数据的存储。Avro是Hadoop中的一个子项目,是一个基于二进制数据传输高性能的中间件,是一个数据序列化的系统。Avro可以将数据结构或对象转化成便于存储或传输的格式,适合远程或本地大规模数据的存储和交换。
3.大数据分析技术栈中数据流水线处理的三种方式
业界对大数据分析技术栈的数据管道一般分为以下三种方式:
1)数据源→HDFS→MR/Hive/Spark(相当于ETL)→HDFS Parquet→Spark SQL/Impala→ResultService(可以放在DB中,也有可能被通过JDBC/ODBC来作为数据服务使用)。
2)数据源→实时更新数据到HBase/DB→导出为Parquet格式数据→Spark SQL/Impala→ResultService(可以放在DB中,也有可能被通过JDBC/ODBC来作为数据服务使用)。
上述第二种方式可以通过Kafka+Spark Streaming+Spark SQL(强烈建议采用Parquet的方式来存储数据)方式取代。业界最期待的数据管道方式为下述第三种方式:
3)数据源→Kafka→Spark Streaming→Parquet→Spark SQL(ML、GraphX等)→Par- quet→其它各种Data Mining等。
由此可见,Parquet格式数据在整个大数据分析过程中在数据管道中起着承上启下,数据格式转换的作用,处于数据管道的中间环节,其地位相当重要。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。