



在目前企业级Spark大数据开发中,大多数情况下都是采用Hive来作为数据仓库的。Spark提供了对Hive的支持,Spark通过HiveContext可以直接操作Hive中的数据。基于HiveContext,我们可以使用sql/hql两种方式来编写SQL语句对Hive进行操作,包括:创建表、删除表、往表中导入数据,以及对表中的数据进行CRUD(增、删、改、查)操作。下面就开始动手实战。
本案例使用Scala语言开发,在Spark中使用Hive数据库,通过HiveContext使用Join基于Hive中的两张表(人员信息表、人员分数表)进行关联,查询大于90分的人的姓名、分数、年龄。演示了对Hive的常用操作(例如删除表、新建表、加载表数据、保存表数据),然后打包递交到Spark集群中运行。具体实现如下:
1.准备数据
在/home/Document/resource目录下,创建两个文件:people.txt和peoplescores.txt,peo-ple.txt文件是人员信息表,包括人员姓名和年龄信息;Peoplescores.txt是人员分数表,包括人员姓名和分数信息。
Michael 29
Andy 30
Justin 19
Peoplescorees.txt的文件内容如下:
Michael 99
Andy 97
Justin 68
2.代码实现
以下代码实现在Hive中新建表以及加载表数据,使用Join将人员信息表、人员分数表进行关联,查询大于90分的人的姓名、分数、年龄。

通过saveAsTable创建一张Hive Managed Table,表(peopleinformationresult),peoplein-formationresult表数据的元数据和数据即将放的位置都是由Hive数据仓库进行管理的,当删除该表的时候,数据也会一起被删除(磁盘上的数据不再存在)。

3.打成JAR包
之前我们在Eclipse中进行了编码,在本地运行通过后,需要将代码打成JAR包,然后将JAR包上传到Spark集群中运行。
单击鼠标右键,选择export命令,选择JAR file,然后点击Next按钮,如图3-3所示。
选择Browse按钮指定JAR导出的路径,如图3-4所示。(https://www.xing528.com)
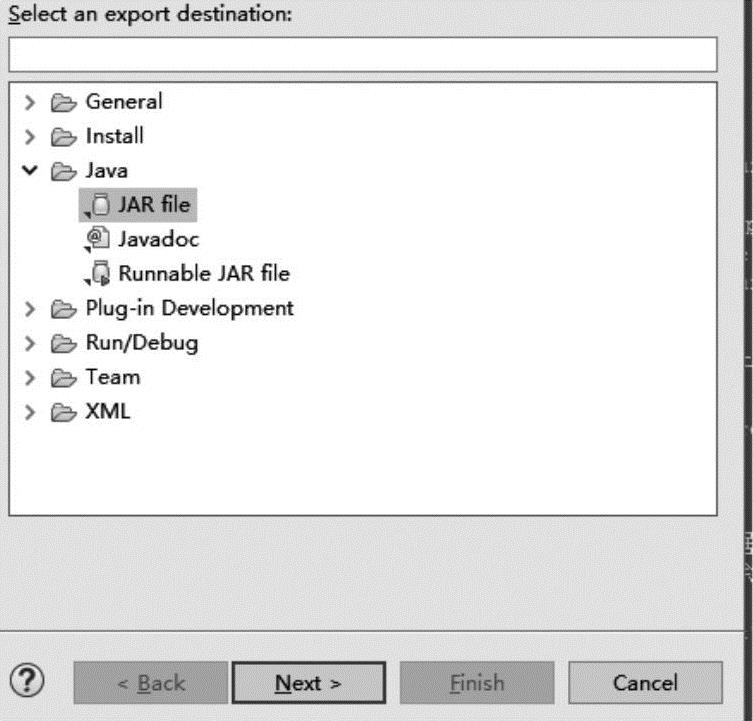
图3-3 选择JAR file
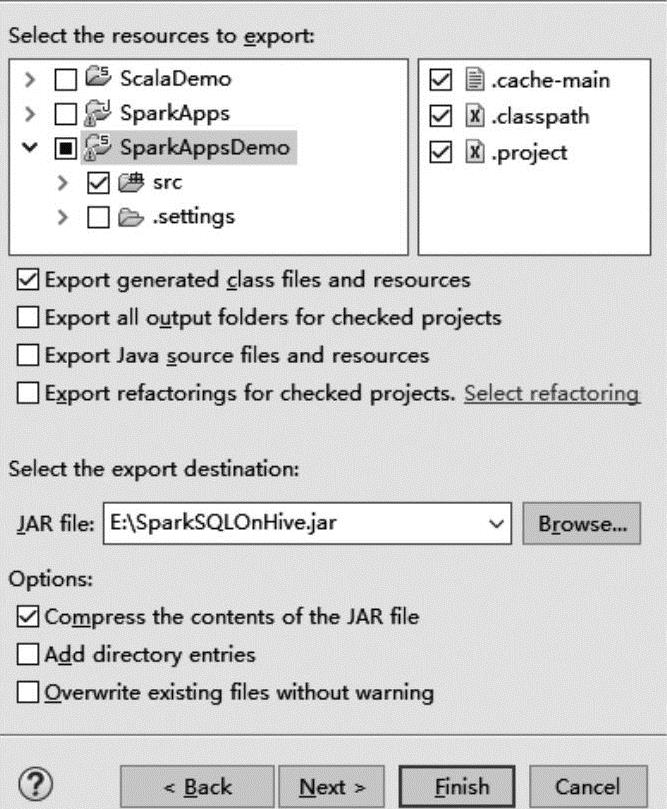
图3-4 指定JAR文件导出的路径
将SparkSQL OnHive.JAR包复制到/Home/Document/SparkApps/目录下,如图3-5所示。
图3-5 复制JAR文件
4.编辑脚本并运行代码
在Linux系统中运行Spark-Submit时,如果不编写脚本,每次都要在Linux提示符中输入Spark-Submit运行的参数及相应的JAR包,调测不是很方便。因此,我们编写脚本文件,将Spark-Submit的相关内容编写在wordcount.sh脚本文件中,wordcount.sh脚本可以放在Linux自定义的目录下(例如/usr/local/wordcount/),并且通过chmod u+x wordcount.sh赋予word-count.sh可执行权限。这样运行Spark应用程序,每次只要运行wordcount.sh就可以了。
编辑wordcount.sh脚本如下:

启动Hive的metastore步骤如下:

运行上述编辑过的脚本,命令行如下:
[root@Master SparkApps]#./wordcount.sh
输出结果如下:

5.查询执行结果
上述代码执行之后,可以在Hive中查询执行结果。各类查询命令行及结果如下:

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。