



【摘要】:Spark SQL加载数据是通过load函数实现的,下面就通过具体案例动手实践load函数的用法。实验的前提是启动HDFS、Spark集群,并且以集群的方式运行Spark-Shell命令行。通过在Web控制台输入URL:http://Master:50070/explorer.html#/,或者直接输入Mas- ter的IP地址,如:http://xxx.xxx.xxx.xxx:50070/explorer.html#/,即可进入HDFS的Web控制台界面,如图3-1所示。图3-1 HDFS Web控制台界面3.文件传入确认目录创建好之后,将Spark系统中自带的examples\src\main\resource中的peo-ple.json文件上传到HDFS的examples目录下。
Spark SQL加载数据是通过load函数实现的,下面就通过具体案例动手实践load函数的用法。实验的前提是启动HDFS、Spark集群,并且以集群的方式运行Spark-Shell命令行。
1.创建目录
首先,在HDFS文件系统中创建examples目录,操作如下:

2.目录查询与确认
第一步的目录创建完成之后,可以通过HDFS的Web控制台界面,来查询新建目录是否已经创建成功。
通过在Web控制台输入URL:http://Master:50070/explorer.html#/,或者直接输入Mas- ter的IP地址,如:http://xxx.xxx.xxx.xxx:50070/explorer.html#/,即可进入HDFS的Web控制台界面,如图3-1所示。由此可以确认上一步中新建的目录examples已经创建成功。
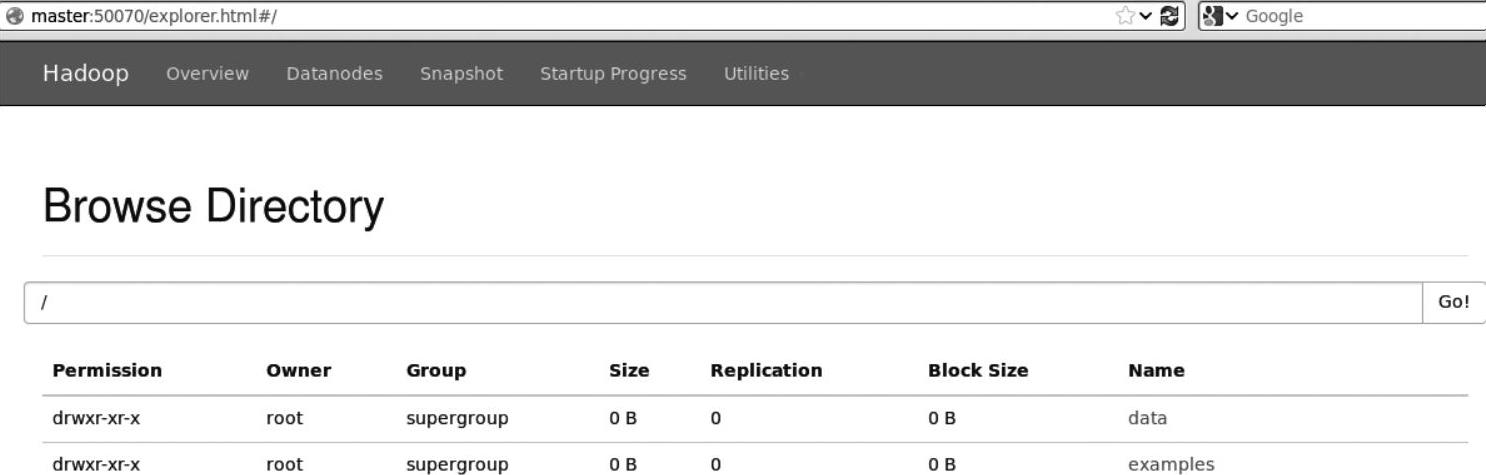
图3-1 HDFS Web控制台界面
3.文件传入(https://www.xing528.com)
确认目录创建好之后,将Spark系统中自带的examples\src\main\resource中的peo-ple.json文件上传到HDFS的examples目录下。具体操作如下:
[root@Master resources]#hdfs dfs-put people.json/examples
4.文件读取
将文件传至新目录examples下后,可以通过以下操作读取HDFS目录下的examples中的people.json文件。

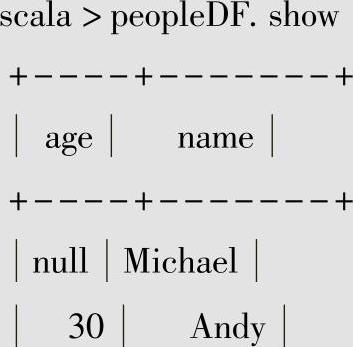
5.数据显示
读取文件之后,可以使用show命令将文件中的数据显示出来。具体实现如下:

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。