



【摘要】:数据准备包含下面两部分内容:●创建数据文件。people.json文件包含了员工的相关信息,每一列分别对应:员工姓名、工号、年龄、性别、部门ID及薪资。newPeople.json对应新入职员工的信息,数据结构与员工信息一致。还可以通过Web控制台的方式查看HDFS上的文件,打开网址http://Master:50070,即可进入Hadoop的Web控制台,如图2-2所示。
数据准备包含下面两部分内容:
●创建数据文件。
●将数据文件上传到HDFS存储系统上。
1.创建数据文件
首先,在本地文件目录中,分别创建下面的数据文件:
●员工信息:people.json。
●新增员工:newPeople.json。
●部门信息:department.json。
1)创建员工信息文件(people.json)。

people.json文件包含了员工的相关信息,每一列分别对应:
员工姓名、工号、年龄、性别、部门ID及薪资。
2)创建新增员工信息文件(newPeople.json)。
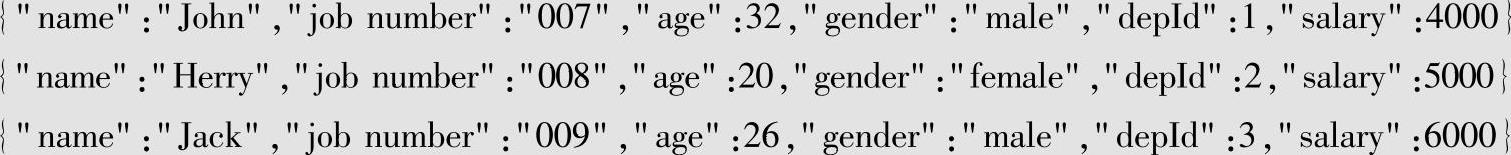
newPeople.json对应新入职员工的信息,数据结构与员工信息一致。
3)创建部门信息文件(department.json)。(https://www.xing528.com)

department.json是部门信息,包含两列:部门名称和部门ID。
其中,部门ID对应员工信息中的部门ID,即员工信息文件中的depID列。
2.将数据文件上传到HDFS存储系统上
1)将这3个数据文件上传到Hadoop集群中,命令如下:

需要预先在HDFS上创建好/library/SparkSQL/Data文件夹。
2)通过HDFS命令查看上传结果。
通过Hadoop的命令行,来查看上传文件是否成功。

可以看到,3个文件已经上传到HDFS存储系统上。
3)通过Hadoop的Web控制台查看上传结果。
还可以通过Web控制台的方式查看HDFS上的文件,打开网址http://Master:50070,即可进入Hadoop的Web控制台,如图2-2所示。
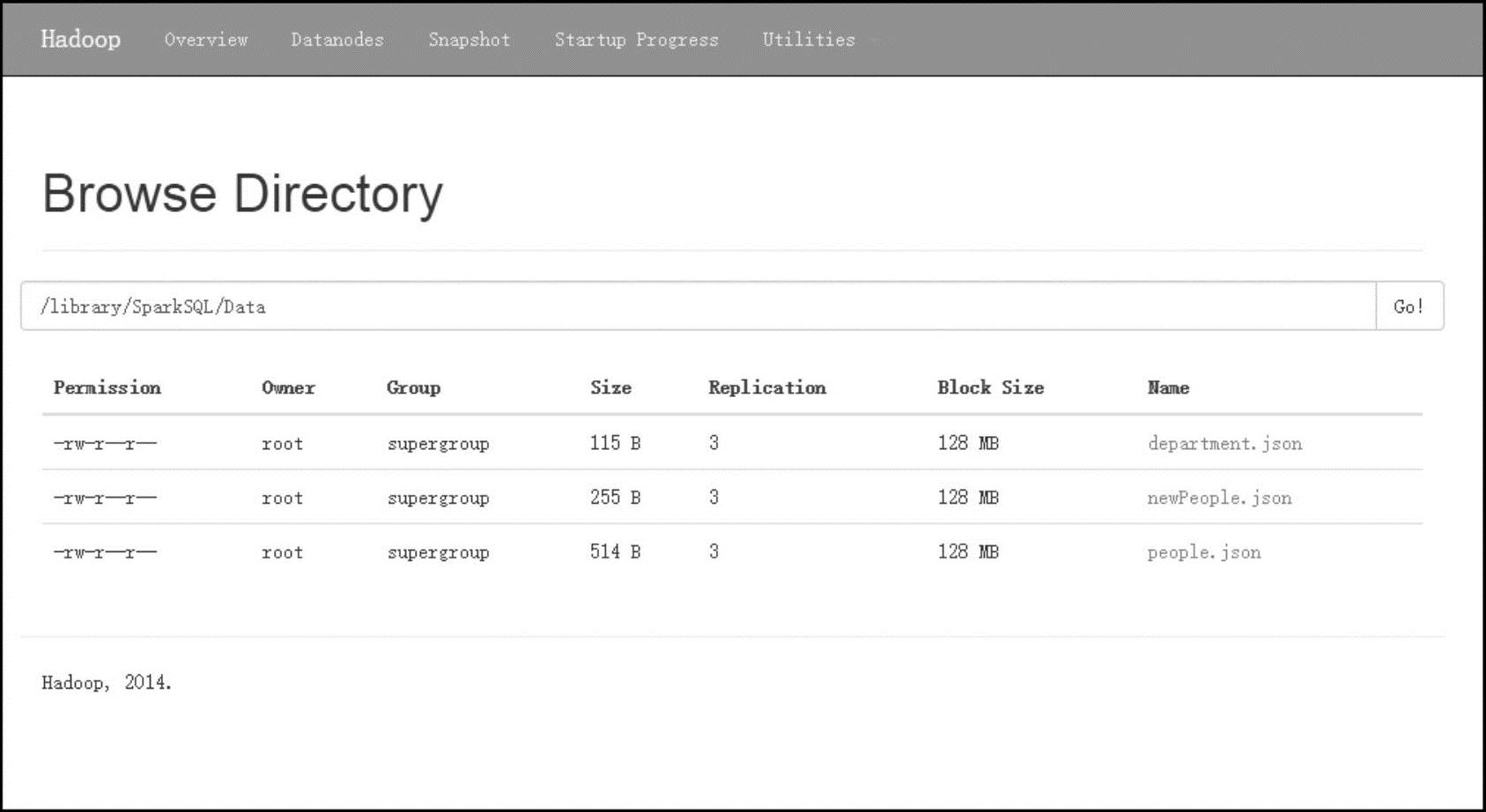
图2-2 Hadoop Web控制台
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。