



【摘要】:Spark SQL是在Spark生态系统中除了Spark Core之外最大且最受关注组件,如图1-1所示。图1-1 Spark组件Spark SQL具备以下特征:1)处理一切存储介质和各种格式的数据,同时可以方便地扩展Spark SQL的功能来支持更多类型的数据,例如Kudu。3)Spark SQL不仅是数据仓库的引擎,而且也是数据挖掘的引擎,更为重要的是Spark SQL是数据科学计算和分析引擎。4)Hive+Spark SQL+DataFrame组成了目前在国内的大数据主流技术组合:●Hive:负责低成本的数据仓库存储。
Spark SQL是在Spark生态系统中除了Spark Core之外最大且最受关注组件,如图1-1所示。
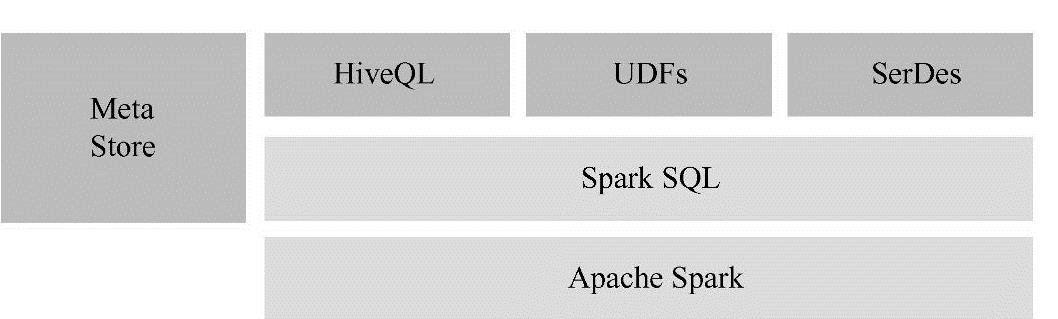
图1-1 Spark组件
Spark SQL具备以下特征:
1)处理一切存储介质和各种格式的数据,同时可以方便地扩展Spark SQL的功能来支持更多类型的数据,例如Kudu。
2)Spark SQL把数据仓库的计算能力推向了新的高度,不仅包括高效的计算速度(Spark SQL比Shark快了至少一个数量级,而Shark比Hive快了至少一个数量级,尤其是在Tungsten Project成熟以后Spark SQL会更加无可匹敌),更为重要的是Spark SQL大大提升了数据仓库的计算复杂度(Spark SQL推出的DataFrame可以让数据仓库直接使用机器学习、图计算等复杂的算法库来对数据仓库进行复杂深度数据价值的挖掘)。(https://www.xing528.com)
3)Spark SQL(DataFrame、DataSet)不仅是数据仓库的引擎,而且也是数据挖掘的引擎,更为重要的是Spark SQL是数据科学计算和分析引擎。
4)Hive+Spark SQL+DataFrame组成了目前在国内的大数据主流技术组合:
●Hive:负责低成本的数据仓库存储。
●Spark SQL:负责高速的计算。
●DataFrame:负责复杂的数据挖掘。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。