



在视频领域,国际上有两大制定视频编码标准的组织,它们是ITU-T(国际电信联盟电信标准化部门)与ISO/IEC(国际标准化组织/国际电工委员会)。
ITU-T制定的标准包括H.261、H.263、H.264,主要应用于实时视频通信领域,如会议电视;MPEG系列标准是由ISO/IEC制定的,主要应用于视频存储(VCD、DVD)、广播电视、Internet或无线网上的流媒体等。2001年12月在泰国由ITU-T和ISO两个国际标准化组织的有关视频编码的视频联合工作组(Joint Video Team,JVT)联合制定了一个性能超过MPEG-4和H.263的视频编码标准。它提供了比当时已有视频图像标准更高的压缩比、高图像质量,以及良好的网络适应性。新标准被加上“Advanced Video Coding”的标题。该标准被ITU-T接纳,称为H.264标准;该标准也被ISO接纳,称为MPEG-4的第十部分。
H.264不仅具有高压缩效率,在大多数码率情况下,最多可以节约50%的码率,而且对网络传输具有更好的支持功能。它引入了面向IP包的编码机制,有利于网络中的分组传输,支持网络中视频的流媒体传输。
H.264具有较强的抗误码特性,可适应丢包率高、干扰严重的无线信道中的视频传输。H.264支持不同网络资源下的分级编码传输,从而获得平稳的图像质量。H.264还能适应于不同网络中的视频传输,网络亲和性好。
1.H.264的编码器和解码器
H.264编码器框图如图1-23所示。它包括两条数据流的路径,一条“正向”路径和一条“重建”路径。
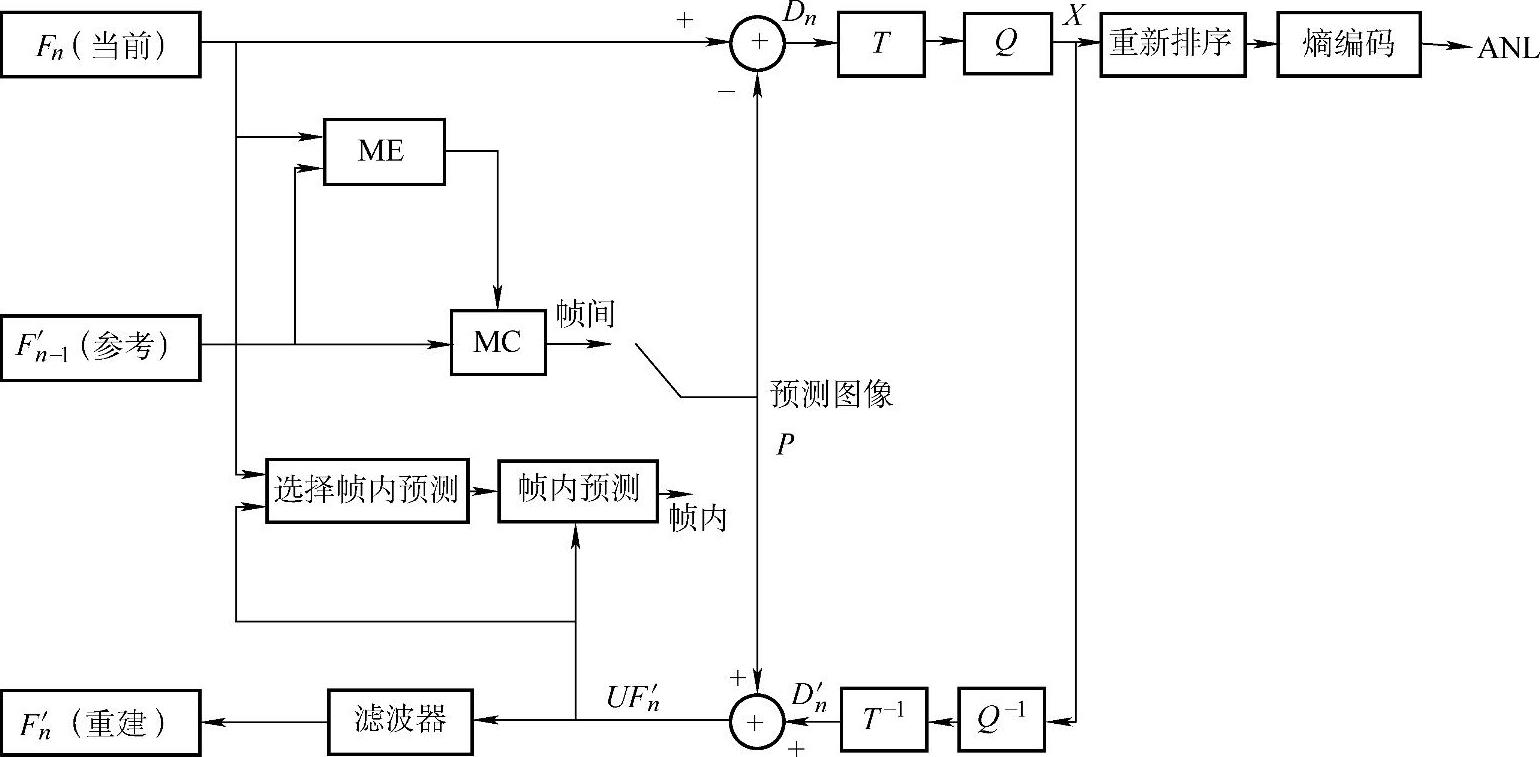
图1-23 H.264编码器框图
T—变换编码 Q—量化 MC—运动补偿 ME—运动估计 T-1—反变换 Q-1—反量化
(1)编码器的正向路径:如图1-23所示,在编码器中,一个输入帧或输入场Fn被划分为以宏块为单位,进行大部分的实际编码处理。每个宏块做帧间编码或帧内编码。宏块中的各个块基于重建图像采样形成一个预测,图1-23中用P表示。在帧内模式中,采用空间预测,参考相邻块的重建图像的采样,图中的UF′n代表用于预测的未加滤波的采样。在帧间模式中,预测来自两组参考图像中选出的一个或两个参考图像的运动补偿预测。图中参考图像表示为前面的编码图像F′n-1,但各个宏块分隔的预测参考可以从过去或将来的已经编码、重建和滤波的图像中选择。将当前块值减去预测值,对残差值块Dn做变换,经量化得出一组量化变换系数X,再经重新排序和熵编码。熵编码系数,以及为宏块中各个块解码所需的伴随信息(如预测模式,量化参数,运动矢量等信息),一起形成压缩码流传输到网络抽象层(Network Abstraction Layer,NAL),用来传输或存储。
(2)编码器的重建路径:编码器中的解码重建为预测提供参考。系数X经反量化(Q-1)及反变换(T-1)产生差值块D′n。预测块加到D′n表示产生一个重建块UF′n,即原始块的解码形式,U表示它未经滤波。滤波器用来减小块效应。重建参考图像从序列F′n中产生。
(3)解码器:H.264解码器框图如图1-24所示。解码器从NAL(网络抽象层)接收压缩的码流。经熵解码,排序产生一组量化系数X。通过逆量化、逆变换给出D′n。从码流中还解出伴随信息。解码器可产生一个预测块,预测块加到D′n产生重建块F′n。
从编码器和解码器的功能块看,H.264与MPEG-1,MPEG-2等没有多大区别,但是各个功能块的细节有很多改变。
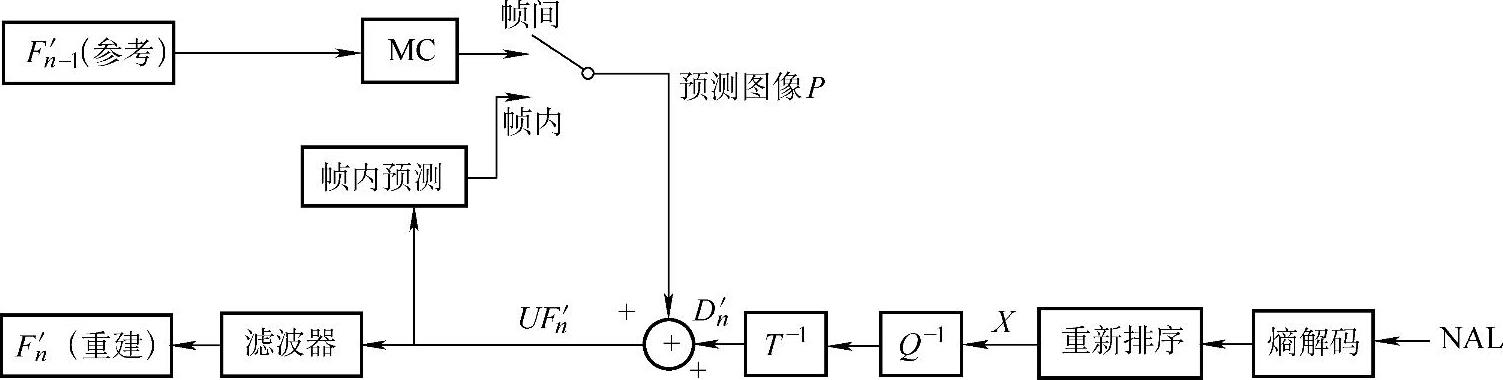
图1-24 H.264解码器框图
2.H.264的先进技术
(1)分层设计:H.264的算法在概念上可以分为两层:视频编码层(Video Coding Lay-er,VCL)负责高效的视频内容表示,NAL层负责以网络所要求的恰当的方式对数据进行打包和传输。在VCL和NAL之间定义了一个基于分组方式的接口,打包和相应的信令属于NAL的一部分。这样,高编码效率和网络友好性的任务分别由VCL和NAL来完成。
VCL层包括基于块的运动补偿混合编码和一些新特性。与前面的视频编码标准一样,H.264没有把前处理和后处理等功能包括在草案中,这样可以增加标准的灵活性。
NAL负责使用下层网络的分段格式来封装数据,包括组帧、逻辑信道的信令、定时信息的利用或序列结束信号等。例如,NAL支持视频在电路交换信道上的传输格式,支持视频在Internet上利用RTP/UDP/IP传输的格式。NAL包括自己的头部信息、段结构信息和实际载荷信息,即上层的VCL数据。
(2)多种更好的运动估计,主要有以下4点。
1)高精度估计:在MPEG-2中采用半像素估计。在H.264中则进一步采用1/4像素的运动估计,即真正的运动矢量的位移可能是以1/4甚至1/8像素为基本单位的。显然,运动矢量位移的精度越高,则帧间剩余误差越小,传输码率越低,即压缩比越高。
在H.264中采用6阶FIR滤波器的内插获得1/2像素位置的值。当1/2像素值获得后,1/4像素值可通过线性内插获得。
对于4∶1∶1的视频格式,亮度信号的1/4像素精度对应于色度部分的1/8像素的运动矢量,因此需要对色度信号进行1/8像素的内插运算。
理论上,如果将运动补偿的精度提高1倍(例如从整像素精度提高到1/2像素精度),则可有0.5bit/采样的编码增益。但实际验证发现,在运动矢量精度超过1/8像素后,系统基本上就没有明显增益了。在H.264中,只采用了1/4像素精度的运动矢量模式。
2)树形结构的运动补偿:在H.264的预测模式中采用了树形构造的运动补偿。AVC编码支持从4×4~16×16尺寸的运动补偿块,在这个范围中亮度样本可有多种选择。每个图像宏块亮度组件可以按16×16、16×8、8×16和8×84种模式分开,如图1-25所示。每一个被分的子区是宏块的一部分,称为子宏块。如果选择了8×8的子宏块,每一个8×8子宏块按8×8、8×4、4×8和4×4等4种模式再分成多个子块,称之为子宏块子块,如图1-26所示。这种子宏块和子宏块子块在每个宏块产生大量的组合。这种划分宏块为各种尺寸的动态子模块的方法称之为树形运动补偿。
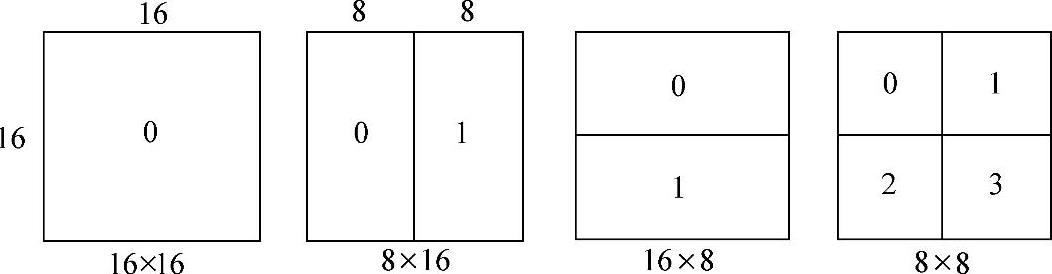
图1-25 宏块分割为4种模式
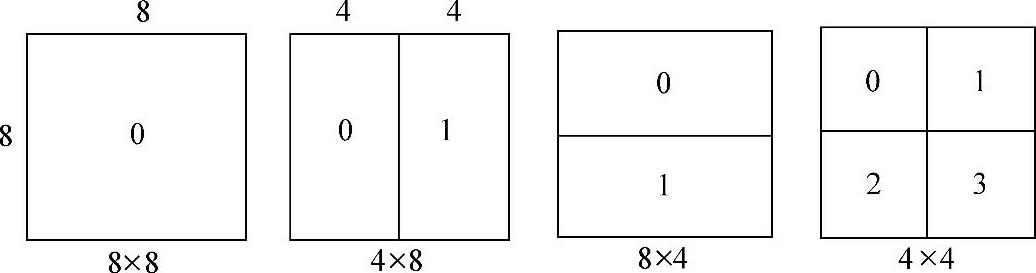
图1-26 子宏块分割为4种模式
要求每一个子宏块和子宏块子块有各自的运动矢量描述,每一个运动矢量都要被编码和发送。除此之外,所选的分区需在压缩的比特流中编码。选择了大的分区意味着用少量的比特数据去描述运动矢量和区域类型。但经过补偿后的运动画面如还有大量的运动细节,则要用较多的比特进行编码。选择小的区域划分会在使用运动补偿后需要少量的比特编码。因此,选择分区的尺寸大小具有显著的意义。总之,大的分区适合均匀的区域,小的分区适合描述细节。
3)多参考帧估计:对于任何给定的像素块,VCL在预测中使用以前的5幅不同的参考帧图像去寻找匹配像素块,即在编码器的缓存器中存有多个编码参考帧,编码器从其中选择一个能给出更好编码效果的作为参考帧,并指出是哪个帧被用于预测,给出相应的运动矢量指示编码和解码的参考像素块。与以前只使用一幅参考帧的编码方法相比,这样可以更有效地提高视频质量和实现更好的码流误码恢复。同时,降低比特率。当然,采用这种方法要求系统对编/解码器提供更高的处理能力并增加额外的延时和存储容量。
4)引入SP帧和SI帧:H.264除了支持其他的视频标准通常使用的I帧、P帧和B帧以外,VCL还支持一种新的码流间可转换帧——SP帧和SI帧。
如图1-27所示,如果一个正在解码流A的解码器要切换到码流B,并解B2、B3、…,如果码流B中都是P帧,那么解码器要重建B2就缺少必要的解码参考帧。一个解决办法是将B2作I帧编码,必须隔一定间隔插入I帧,作为“切换点”,这时在切换点处需要的比特数就比较多。
为了能切换但又不依靠引入I帧,在切换点使用了SP帧,如图1-28所示。(https://www.xing528.com)
切换的关键是SP AB2,它的产生即编码过程如图1-29所示。
首先对要切换到的帧B2做变换,再从被切换的帧A1形成的运动补偿预测。图1-29中的MC块是以解码图像A1作为参考帧,使B2的每个宏块尽量找到最佳匹配。对运动补偿预测做变换,然后与B2的变换相减,将得到的差值进行量化后传输。
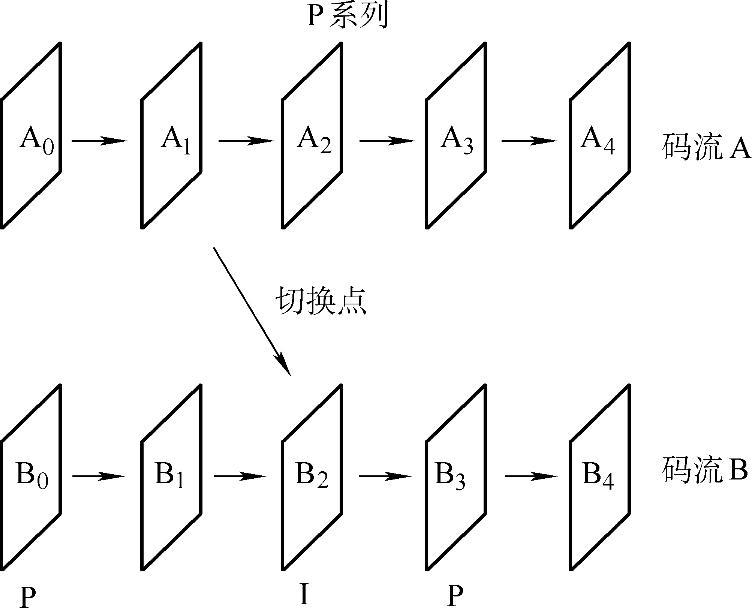
图1-27 利用I帧切换
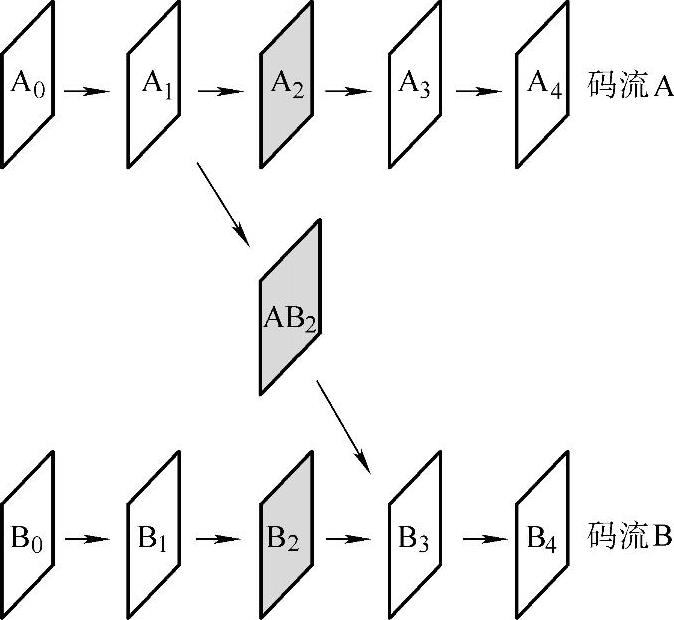
图1-28 用SP帧切换码流
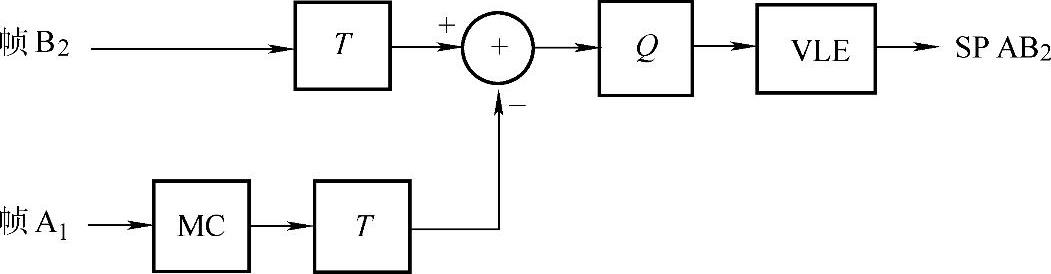
图1-29 SP AB2的编码过程
解码时,解码器先解出A1,再对SP AB2解出B2,如图1-30所示。
所以通过使用一个比特流中的SP帧(同理也可以用SI帧),VCL可以在那些有类似内容但有不同码率的码流之间快速切换,并同时支持随机访问和快速回放模式。
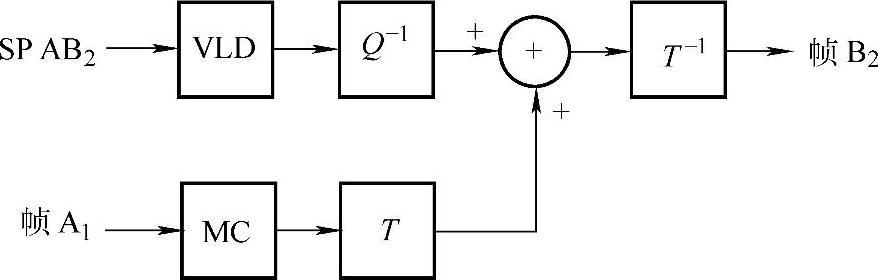
图1-30 SP AB2的解码过程
(3)采用帧内预测编码:I帧内编码利用视频图像中的空间冗余来提高编码效率。与基于16×16像素宏块的MPEG-4帧内预测编码技术所不同的是,VCL的帧内预测技术利用相邻像素块的相关性,先将QCIF(176×144)格式的图像分成99个16×16宏块,然后分成4×4像素块执行预测编码。对每个4×4像素块,总共有9种4×4相邻亮度块的模式。如图1-31所示为4×4块中的像素做空间预测时所参考的周边像素。图1-32所示为各种预测模式,箭头表示预测的指向。其中,模式2是直流(DC)预测模式,模式3~8中,预测采样值是将A~M的采样加权求得的。有了预测值,将它和当前值相减,求得的差值做变换。
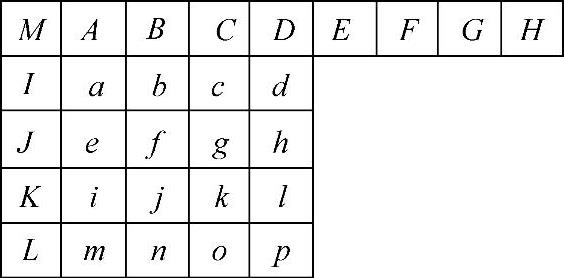
图1-31 预测4×4像素块 所参考的周边像素
(4)整数变换:虽然VCL采用的变换类似于DCT的变换,但是它使用的是4×4的整数块,而DCT使用的是8×8的浮点块。这样,由于前者使用的是以整数为基础的空间变换,因此其反变换不存在取舍误差的问题,同时能够解决编码器和使用反变换的解码器之间的误匹配问题。此外,采用小的形状块有助于降低块效应和明显的人工处理痕迹。
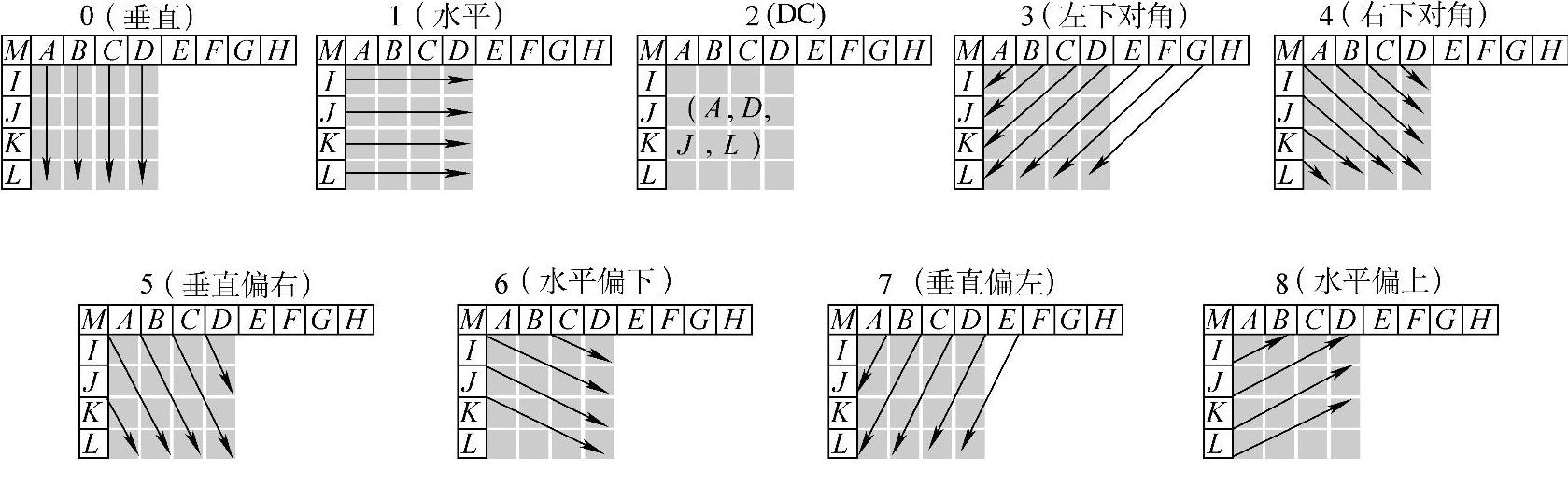
图1-32 4×4亮度预测模式
(5)量化处理:量化步长是对宏块数据进行压缩的一个重要组成部分。类似于H.263使用31个不同的量化步长,VCL提供了32个不同的量化步长。此外,VCL使用非固定宽度的尺度量化方法对变换系数进行量化,这些步长按12.5%的混合速率增加,通过使用精确的量化步长,更能改进色度部分的精度。
量化变换的系数对应不同的频率:一个对应DC值,其余的分别对应不同的频率值。VCL将所有的变换系数放在一个数组中,通过“之字形”(Zig-Zag)扫描和双扫描对数组中的数据进行读取。双扫描只用于使用较小量化级的块内,它有助于提高小量化步长时的编码效率。
(6)去块效应滤波:在对图像进行编码处理的过程中,为了减少运算量,要对图像进行分割,分割后对每小块进行相对独立的处理。常用的分割方法是,将图像分成方形的像素块。这种分割后相对独立处理的方法容易引起块与块的边缘部分衔接不好。例如,采用变换编码时,块内的高频分量损失,会引起块与块的边缘部分无法平滑过滤,解码后就会产生块效应。块效应有时会非常明显,而且令人讨厌,对图像质量有很大的影响。
在一些新的编码方法中,采用去块效应滤波器解决块效应问题。经滤波之后的图像才被用于运动估计。去块效应滤波器是自适应滤波器,它的滤波强度与宏块模式、量化参数、运动矢量、帧/场判决和像素值相关。在量化级很小的时候,它会自动关闭。
去块效应滤波示意图如图1-33所示。对相邻块解码值p0和q0,如果
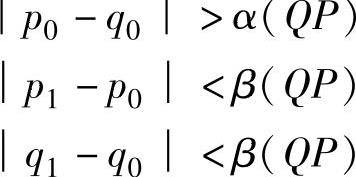
则对p0和q0作滤波平滑。其中α(QP)和β(QP)为设定参数,α(QP)比β(QP)要大得多。如果还满足
│p2-p0│<β(QP)
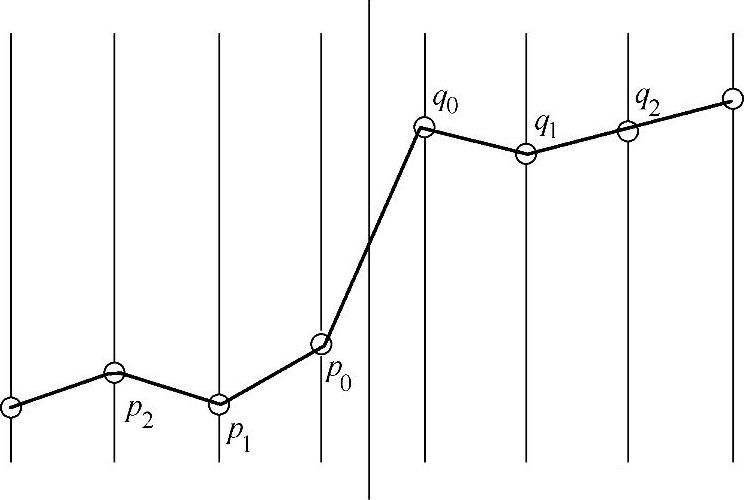
图1-33 去块效应滤波示意图
或者
│q2-q0│<β(QP)
则对p1和q1也作滤波平滑。
(7)熵编码:H.264标准采用的熵编码方法有3种。第1种是Exp-Golomb(Exponential Golomb)码,它适用于除变换系数之外的所有其他系数。第2种是基于上下文的自适应变长编码(CAVLC,Context-based Adaptive Variable Length Coding),它适用于变换系数。第3种是基于上下文的自适应二进制算术编码(CABAC,Context-based Adaptive Binary Arithmetic Coding)。CAVLC与CABAC根据相邻块的情况进行当前块的编码,以达到更好的编码效率。CABAC比CAVLC压缩效率高,但要复杂一些。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。