



数学模型可以用来理解和描述食品加工或保藏过程中的各种因素与食品质量指标之间的内在关系,进而预测过程与结果的相关性和相互影响,最终用于采取有效的控制策略,实现食品加工与保藏的目的。建立这样的数学模型,不仅需要掌握食品科学和营养学的相关知识,还需要数学建模的知识。
数学模型是运用数理逻辑方法和数学语言建构的科学或工程模型。数学语言可以用来描述客观世界,可以让我们对客观现象做出精准的描述。数学建模就是针对现实世界的实际问题及数据,运用数学语言,如符号、方程、公式等,在一定的假设及适当简化实际问题的情况下,将现实问题抽象为数学模型,并进行分析求解,进而解决实际问题的过程。数学模型最重要的作用是反映现实问题,但由于它只是一个模型,不可能考虑到现实中的全部因素,因此在建模过程中需要忽略一些次要因素或对这些因素进行简化,从而使模型更加集中地反映现实问题的数学规律。
建立数学模型需要获取必要的数据,因此,首先通过有限的实验或者通过文献检索获得充分的数据,再运用数学工具来建立模型。需要特别指出的是,建模的目的和建模的方法同样十分重要。建模的一般步骤如下:
1.模型的准备
各行各业都可能遇到需要建立模型的问题,那么在建立数学模型之前我们首先要对该行业的背景知识有一定的了解,可以通过查阅、学习等方法先对问题有一个初步的印象。此外,要明确建立数学模型的目的,清楚所要研究的对象的特征,必要时请教相关方面的专家,为模型建立作准备。
2.模型的假设
要将现实问题简化为数学语言,就需要根据建模的目的,在分析问题的基础上对问题进行必要地、合理地简化,并使用精确的语言作出假设。在假设时,不可能把所有问题都考虑到,需要抓住问题的主要因素,去除次要因素。假设的问题及假设的合理性也会影响建模的成功与否,因此模型假设时既要进行简化,又要保持模型与实际问题足够贴合。
3.模型的建立
根据了解到的问题背景以及所建立的假设,利用适当的数学工具表示相关量与元素的关系,建立数学结构,如不等式、方程、表格、图形等。建模时尽量采取简单的数学工具,以方便更多的人能够了解和使用该模型。
4.模型的求解
模型建立完成后需要进行求解,包括解方程组、画图表、逻辑运算等,一般运用软件和计算机技术进行求解。这些软件可以为求解数学模型提供快捷方便的方法,Mathematica和Maple作模型解析研究,LAPACK、BLAS、Sundials作数值求解中具体代数方程、偏微分方程与常微分方程的求解。
5.模型的分析
这一步是要对模型进行数学分析,尤其是误差分析和数据稳定性分析。
6.模型的检验
既然建立数学模型的目的在于解决实际问题,那么对于建立好的模型,其一需要检验该数学模型是否可以作为解决实际问题可以使用的模型。其二需要检验数学模型是否在逻辑上说得通,是否存在自相矛盾的地方。除此之外,模型是否容易求解也是判断数学模型优劣的一个重要指标,过于烦琐的求解过程不利于模型的普遍应用。如果结果不够理想,应该进行修改、补充假设或者重新建模,有的模型需要经过几次的重复,不断完善。
7.模型的应用
所建立的模型必须能够应用到实际过程中,并在应用中不断改进和完善该模型。
数学模型涉及很多学科,也会应用到不同的数学工具,因此它的分类并不是绝对的,按照不同的标准来划分可以分为不同类别:
①按照模型中的变量情况:可以分为离散性模型或连续性模型,确定性模型或随机性模型等;
②按照模型的应用领域:可以分为生物数学模型、医学数学模型、地质数学模型、数量经济学模型、数学社会学模型等;
③按照建立模型的数学方法:可以分为几何模型、微分方程模型、图论模型、规划论模型等;
④按照是否考虑时间的变化:可以分为静态模型和动态模型。
除此之外,还有许多不同的分类方式,不一一赘述。
动力学模型(Kinetics Modeling)是食品工程中最常用的数学模型之一,在第二章将详细介绍。除此之外,如响应面模型(Response Surface Models)和多元统计工具(Multivariate Statistical Tools)也十分重要。
食品过程工程本质上是多尺度、多系统、多参数互作的动态过程,是一项多学科交叉融合的技术,因此具有高度的复杂性。在解决问题的过程中往往数据量过于庞杂,而且数据之间存在复杂的相互关联性,如何去分析这些数据,找到其中的关系是难点。这就取决于合理运用数学工具,通过不同数学计算工具的处理,从海量数据中抽丝剥茧,探究其中蕴含的信息,更快更好地解决问题。
(一)数据分析:绘图和拟合方程
1.变量和函数
(1)变量(Variable)是指能评估某个值的量,变量的符号是不定的,任何字母都能代表一个变量,但是通常字母表中靠前的字母代表常数(Constant),靠后的字母代表变量。如表达式y=ax+b,其中a和b代表常数,x和y代表变量。
(2)函数(Function)是表示变量之间关系的表达式,利用这个工具可以便于研究人员探究不同变量的变化情况和关系。如放在烘箱里加热的固体温度,可以表达为加热时间和固体温度的函数关系表达式y=f(x,t)。
(3)变量又可分为因变量(Dependent Variable)和自变量(Independent Variable),两者是可交换的。如表达式y=f(x)中,y是因变量,x是自变量,但如果将表达式改写为x=g(y),则因变量是x,自变量是y。在实验设计中,固定的变量是自变量,而需要测量得到的是因变量。例如,测定罐头食品中抗坏血酸的损失时,时间是自变量,抗坏血酸的含量是因变量。另外,如果是采集某个样品,测定样品的水分含量和水分活度,那么可以将其中任意一个设定为因变量和自变量。
2.作图
每个实验得到的数据都是一组数据点组成的,每个数据点是代表一对因变量和自变量的值的数字。如果一个因变量的值仅对应一个自变量的值(单变量),即表现为一个数据对。反之,如果一个因变量的值对应多个自变量的值(多变量),即表现为数据表或图表。以单变量对应的数据点作图是二维的,以多变量对应的数据表作图是多维的。
数据点的一对数字是指该点在图上的坐标,因变量绘制在水平轴或“横坐标”(Abscissa)上,自变量绘制在垂直轴或“纵坐标”(Ordinate)上。数据点的值代表该点分别在横坐标和纵坐标上距离原点的距离,通过合理的缩放,使数据点落在图的中间。相类似地,笛卡尔坐标系(Cartesian Coordinate System)扩展了横坐标和纵坐标,将图分为四个象限,左半边的横坐标代表因变量的负值,下半边的纵坐标代表自变量的负值。
(1)线性图(Lineargraph)如果包含变量x和y的实验数据满足下述方程:
式中 a——直线的斜率;
b——y轴的截距。
那么作图时,这些数据将落在一条直线上。
(2)单对数坐标图(Bode Plot)如果包含变量x和y的实验数据满足下述方程:
式中,a和b为常数,对等式两边以10为底取对数,则有:
因此,如果用lgy对x作图,则得到一条直线,其斜率为b,在y轴上的截距是lga。这时,更方便的方法是使用单对数坐标图纸,这种图纸的一个坐标是线性的,另一个坐标是lg坐标,将y放在lg坐标上,x放在线性坐标上直接描点,即可得一条直线。
(3)双对数坐标图(Log-Log)如果包含变量x和y的实验数据满足下述方程:
式中,a和b是常数,对等式两边取对数,则有:
因此,如果使用双对数坐标图,用y对x作图则得到一条直线,其斜率为b,a是x=1时y的值。
3.方程(Equation)
方程是一个恒等式的陈述,利用方程可以很方便地通过一个或多个变量的值得知另一个变量的值,因此如何通过实验数据拟合出接近真实情况的方程是十分重要的。可以通过以下方法拟合到方程中:
(1)线性回归和多项式回归 线性回归(Linear Regression)是指选取大量的样本数据,根据数据的发展趋势,选择假设函数,基于最小二乘法(Least Square Method)得到函数极小值,代入假设函数中就可以得到较为符合的方程。多项式回归(Polynomial Regression)则是在样本数据更为复杂的情况下,运用类似的原理,通过假设和代入得到相符合的方程。
(2)线性、数据转换和线性回归 线性方程是一种便于计算和分析的方程,因此多数情况下都希望将方程化为线性方程,当数据关系是非线性时,可以通过数据转换(Data Conversion)将其转换为线性数据,线性回归确定线性方程的系数。
(3)作图 原始数据点或是变化后的数据点,多个点可以绘制成一条直线,并且从斜率和截距中确定方程中变量的系数。
(二)方程的解法
1.方程的根(Solution)
方程的根代表变量的值,且符合函数方程式的关系。多项式的根和多项式数量一样多,以下介绍几种方法确定方程的根。
(1)变量的最高次数为2的方程称为二次方程,可以通过求根公式得解:
能得到根:
(2)还可以通过分解因式得解:
能得到根: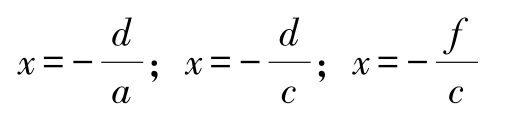
这三个解都满足方程f(x)=0。
(3)迭代法(Iterative Method)上述分析解能够快速得到方程的解,但对方程的表达形式有严格的要求。实际问题中,多数方程不可能获得根的分析表达式;数值求解是最常用的解析解替代方法。以牛顿迭代法(Newton-Raphson Method)为例来解释说明。初始化变量x的值x=x0,然后通过以下式子计算下一步的变量值x1,
通用地,
如此迭代,直到停止判别式f(xn)<ε或者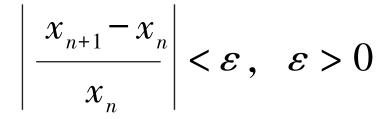 得到满足。其中,f′(x)|x=xn为变量x=xn时的一阶导数。
得到满足。其中,f′(x)|x=xn为变量x=xn时的一阶导数。
除牛顿迭代法之外,还有其他被广泛应用的迭代法,如二分法(Bisection Method)、弦截法(Secant Method)等;由于内容关系,不作具体展开。
2.图解积分
有些情况,实验结果难以用可以积分的方程式形式表达,此时可以使用图解积分法。图解积分法是通过有限差分法评估微分方程的值。以下举例三种求解方法:
(1)矩形法(Rectangle Method)如图1-2(1)所示,将定义域分为一系列矩形,矩形的厚度表示x的增量。设置矩形的高度使得曲线内部的阴影区域等于曲线外部的条形区域。增量可以不相等,图1-2(1)中使用0.5个单位的相等增量。
图1-2 矩形(1)和梯形(2)的图形积分
对于A1、A2、A3和A4,矩形的高度分别为6.5、12.5、20和28。面积之和为0.5×(6.5+12.5+20+28)=33.5。
(2)梯形法 如图1-2(2)所示,将定义域分为一系列梯形,梯形的面积是宽度乘以高度的算术平均值。对于函数y=4x2,当x=1、1.5、2、2.5和3时,函数值(高度)分别为4、9、16、25和36。梯形A1、A2、A3和A4的面积分别为0.5×(4+9)÷2、0.5×(9+16)÷2、0.5×(16+25)÷2和0.5×(25+36)÷2。总和为3.25+6.25+10.25+15.25=35。
若采用矩阵实验室(MATLAB)计算,可直接调用trapz(x,y)函数,以梯形法的方式计算积分。
(3)辛普森积分法(Simpson's Rule)梯形法又可以理解成以一次多项式的方式逼近积分原函数。下面介绍以二次多项式(Quadratic Polynomical)的方式逼近原函数的辛普森法则。(https://www.xing528.com)
假定函数积分区间[a,b],被偶数均匀地分成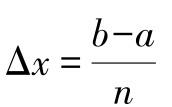 个片段。在偶区间[x0=a,x2=a+2Δx]内,采用二次多项式g(x)=a0+a1x+a2x2来近似原函数:
个片段。在偶区间[x0=a,x2=a+2Δx]内,采用二次多项式g(x)=a0+a1x+a2x2来近似原函数:
通过三个坐标点[x0,f(x0)]、[x1,f(x1)]、[x2,f(x2)]联立多项式的代数方程,可求出a0、a1、a2的值。然后代入[a0,a1,a2]值到式(1-11)中得出,
其中,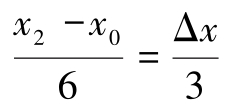 。由此类推,积分面积时所有如此偶区间片段积分数值的加和:
。由此类推,积分面积时所有如此偶区间片段积分数值的加和:
所以积分面积A
此外,辛普森积分法还可以用三次多项式进行拟合,这里不作介绍。
我国是一个人口众多的国家,每天都有大量的食品被消费,这些食品可能经过研磨、干燥、腌制、冷冻等不同的加工过程,这些加工过程会涉及食品营养成分的损失、质构的变化、添加剂的使用、微生物的生长繁殖等。现代生产工艺需要灵活多样,出于多种因素限制,通过反复试验达到质量标准似乎不再是最好的方法。更系统的方法是使用建模,实际上,可以将建模过程想象为在虚拟实验室中使用定量模型进行模拟。数学模型的目的是基于对现象和可用度量的现有理论帮助理解、预测、控制复杂对象或过程的相关特征。目前的工业应用通常依赖于极其简化的静态模型,无法对工厂性能、质量和安全条件以及环境影响的瞬态效应进行真实的评估。建模和模拟的研究工作应针对主要的现象学方面,结合不同的因素,如热量、质量、动量、种群平衡与生物化学反应。下面以食品常用的数学模型为例,方便读者理解数学模型的应用。
(一)食品热物性的数学模型
食品的热物性(包括密度、导热系数、比热容等)在传热过程中会发生很大的变化。例如,食品冻结的过程中,水在食品组分中所占比例很大,且冻结过程中会发生相变,而水的热物性与冰的热物性差别很大,在0℃水的密度为997kg/m3,冰的密度为917kg/m3;水的导热系数为0.567W/(m·K),冰的导热系数为2.24W/(m·K),因此水的相变会影响食品的密度、导热系数。除此之外,冻结时食品的比热容除了实际比热容外还要考虑相变放热,冰在0℃时的融化潜热为333.2kJ/kg,数值很大,因此冻结食品的比热容也会发生很大变化。
在选择食品冻结设备以及生产工艺时,常常需要利用食品的热物性来计算热负荷,过去选用人工查表计算的方法,既烦琐又不精确,随着电子计算机技术的发展,利用数学模型的自编软件进行计算能节约时间并满足精度的要求。其次,研究中经常需要对食品的传热过程进行分析与数值模拟,这一过程也需要用到食品的热物性数据。而利用数学模型能较好地描述食品热物性的变化规律,保证分析和模拟结果的准确性。在Fluent软件中,可以采用分段多项式数学模型来描述材料物性的变化规律。
首先了解食品热物性学的经验公式:
1.食品冻结水含量的经验公式
式中 xice——冻结过程中食品内冰的质量分数;
xwo——未冻结时食品内水的质量分数;
tf——食品的初始冻结温度,℃;
t——食品内部的温度,℃。
2.食品密度的经验公式
式中 ρ——食品的密度;
ε——食品材料的多孔率;
xi——食品中各种组分的质量分数;
ρi——食品中各种组分的密度。
3.食品热导率的经验公式
Chio和Okos提出的根据组分体积分数和导热系数计算食品材料在各温度下的热导率的经验公式:
其中,xvi是食品材料各组分体积分数,计算公式如下:
式中 xi——食品中各组分的质量分数;
ρi——食品中各组分的密度;
ki——食品中各组分的导热系数。
将式(1-18)代入到式(1-17)可得到:
4.食品比热容经验公式
式中 cu——未冻结食品的比热容;
ci——食品中各组分的比热容。
当食品的温度在冻结点以下时,必须同时考虑温度改变的显热和水变成冰的潜热。采用Chen(1985)对Schwartzberg(1981)的经验公式的改进,简化形式如下:
式中 ca——表观比热容;
xs——食品中不可溶固体的质量分数;
xb——食品中结合水的质量分数;
Lo——水的凝固潜热(333.2kJ/kg)。
根据上述经验公式,从水、冰、蛋白质、脂肪、碳水化合物和灰分等构成食品的单组分物质的热物理性质出发来确定食品材料的热物理性质,通过查找各组分的计算公式代入上述经验公式得到食品材料热物性的数学模型。为得到简单的分段多项式模型,采用C语言编写程序,利用程序计算出一系列的离散点,并绘制热物性随温度变化的曲线图,再利用分析软件对离散点进行回归分析,得出多项式数学模型。最后再与文献中热物性随温度变化的趋势图进行比较,验证模型的正确性。
(二)食品挤压膨化过程数学模型
挤压膨化过程包括5个阶段:物料从有序到无序的转变、气泡成核、模口膨胀、气泡生长和气泡塌陷。从有序到无序的转变主要是指淀粉糊化和降解、蛋白质变性等,使粒状或粉状物料转变成具有黏弹性的熔融体。成核和气泡生长是影响膨胀的关键阶段,后期的气泡塌陷则降低膨胀度。模口膨胀主要对径向膨胀产生影响。挤压膨化涉及的模型主要有成核速率模型、气泡生长模型、模口膨胀模型,这里主要介绍一下成核速率模型。
熔融体排出模口后由于压力突然降低,形成热力不稳定的小气泡,称作“泡种”,“泡种”达到临界值时气泡才能够生长,如果直径过小,表面张力过大导致气泡不能生长,当“泡种”直径达到临界值时成为“气核”。
若成核方式为均匀成核,成核速率如式(1-22):
式中 A——气体分子成核的频率因子;
kB——玻尔兹曼常数(Boltzman),J/K;
T——热力学温度,K;
c0——发泡剂浓度,kg/m3;
ΔG——成核所需的吉布斯自由能(Gibbs),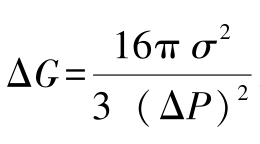 ,σ为气泡—熔融体间的界面张力,ΔP为模头压力降。
,σ为气泡—熔融体间的界面张力,ΔP为模头压力降。
另一种成核方式为非均匀成核,其主要由杂质引起,其速度比均匀成核快得多。食品挤压过程中的成核方式主要为非均匀成核。其成核数量主要由实验确定。
(三)食品贮藏品质数学模型
食品贮藏品质与食品的种类、加工工艺、贮藏条件等有关,不同食品贮藏过程的品质变化规律和品质特征指标往往有差别。在一定的贮藏过程中,食品的品质是贮藏时间的函数,品质随时间的变化可用Ni=fi(t)来表示,Ni为第i种品质指标(i=1,2,3……,n,如N1为总菌数,N2为色泽等);fi(t)为第i种品质指标的时变函数,通常受原料特性、贮藏条件及初始状态等因素的影响;t为贮藏时间。fi(t)可以为理论模型、经验公式、半理论半经验模型等。其中常用的理论模型有描述生物生长的米切利斯(Mitscherlich)、冈珀茨(Gompertz)、罗杰斯蒂(Logistic)、理查兹(Richards)等模型,描述酶反应特性的米氏方程,描述生化反应的一级化学反应动力学模型和阿伦尼乌斯方程(Arrhenius Equation)等。
(四)食品包装材料数学模型
塑料包装广泛用于食品包装中,用于阻止氧气、水蒸气、二氧化碳的渗透,减缓原始成分和营养的损失,方便贮藏等。但有些不合格的塑料包装材料,由于内部残留的添加剂、加工助剂、聚合物单体、低聚体等化学物质扩散进入食品中,会导致食品安全事件的发生。若通过实验手段研究塑料包装材料内组分的迁移,耗时耗力、检测困难且花费昂贵。采用建立数学模型的方法研究塑料包装材料中化学物质向食品的迁移,既便于研究又能降低成本。目前,包装材料向食品迁移的数学模型大都基于菲克(Fick)扩散定律:
式中 D——扩散系数,m2/s;
C——扩散物质的体积浓度,kg/m3;
J——扩散通量,kg/(m2·s)。
式(1-28)描述了一种稳态扩散,即污染物浓度不随时间而变化。大多数扩散过程为非稳态扩散,即材料中某一点的浓度随时间而变化。因此需要考虑Fick第二定律:
通常认为迁移仅发生在垂直于包装材料的平面上,因此用上述一维的二阶偏微分方程来描述。当扩散系数D与浓度无关时,式(1-24)简化为:
[例1-1] 一种奶油蛋卷类产品中的真菌生长预测模型(Ifigeneia M,2018)。
真菌污染是烘焙产品中的主要食品安全问题,烘焙产品的pH和水分活度(Aw)适宜霉菌的生长,且通常这些产品会直接放在货架上进行售卖,更增加了感染真菌的风险。因此建立一个能够预测真菌生长的数学模型是十分有价值的,以下以一种奶油蛋卷产品为例。
首先从烘焙商家中获得一些奶油蛋卷类产品的基础数据,包括产品类别、Aw、pH、防腐剂和包装气体。根据这些产品的特点,设定条件:Aw为0.99(真菌生长最适值)和0.82(奶油蛋卷类产品值);pH=6.0;温度为25℃和37℃(夏季温度)有氧培养,并每天测定菌落生长直径。
根据菌落生长直径和贮藏时间的关系绘制生长曲线,然后将实验数据通过一级线性模型巴拉尼—罗伯茨(Baranyi-Roberts)方程拟合估计生长动力学参数(生长速率,rmax,cm/d;延滞期,λ,d)。而温度(T)和Aw则通过二级模型罗索—罗宾逊(Rosso-Robinson)方程拟合确定(Tmin、Tmax、Topt、Awmin、Awmax、Awopt)。为了便于建模,使用逆延滞期1/λ,稳定rmax和λ之间的方差,较高的Aw假设为1.0(对应纯水)。
为了模拟外在条件(T、CO2)和内在参数(Aw、丙酸钙)对rmax和λ的影响,选用Gamma模型,建立两个模型分别描述上述因素对生长速率(rmax)和逆延迟期(1/λ)的影响,模型的一般形式如下:
其中,x是环境变量,即T和Aw;pmin、popt和pmax分别是各个变量的理论最小值、最适值和最大值;n是形状参数;CM包括rmax和1/λ。
在培养基上进行验证时,根据烘焙产品的日常记录数据,由于贮藏条件的波动以及含奶油填充的面团持水能力的变化,T和Aw是最易发生变化的。因此将T和Aw设计为变量,而CO2max和丙酸钙的最小抑制浓度(Minimum Inhibitory Concentrations,MIC)查阅自文献,设定为100%和0.25%。为了使模型包含各种环境因素的影响(如防腐剂和包装气体),增加接近生长边界的模型的稳健性,使用两个Aw参考条件计算rmax和1/λ的参考值(rref和1/λref)。这两个Aw的参考条件,其一是低水平(0.84),这与经过充分烘焙的奶油蛋卷的Aw值接近(0.82);其二是高水平(0.90),这可能在不太理想的产品中出现。预计这两种条件都有利于真菌生长,因此可在此参考条件下进行模型模拟,此时的模型中不包含CO2和丙酸钙作为变量[式(1-27)]。
在原位(奶油蛋卷)验证中,使用完整的Gamma模型[式(1-28)],其中包括丙酸钙和CO2,以此得到rmax和1/λ的预测值。
其中,ξ是描述测试变量与rmax和1/λ之间定量关系的特定术语。[PAU]指未解离丙酸钙的浓度,MICu指最小抑制浓度理论值。
培养基接种真菌的径向生长变化可以通过以下线性模型预测:
其中,D0和Dt分别是实验开始时(t=0)和贮藏期间任何时间t的真菌直径(cm),λ是延滞时间。D0是接种孢子悬浮液滴的直径(0.5cm)。
在经过多项实验验证后,证明该模型在预测烘焙产品中真菌生长的应用潜力。模型的稳健性还需要进一步的实验测试完善,直到能够应用于行业中,作为决策工具,便于在产品配方、货架期、物流管理中使用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。