



就目前来说,Project Tungsten的二进制数据处理主要是用在Shuffle和SQL的aggregation(聚合)(以及其他一些操作)数据上,像为其他非JVM的本地类库(如C++类库)等提供内存访问等操作,仍然还在实现中(有兴趣的读者可以参考https://issues.apache.org/jira/ browse/SPARK-10399部分)。
本书基于Shuffle过程,解析在源代码中具体如何使用Project Tungsten来处理数据,对应其他操作的处理细节,可以参考对应issues及其设计文档(部分提供了非常详细的设计文档)。比如在聚合方面使用Project Tungsten内存模型的详细设计可以参考https:// issues.apache.org/jira/browse/SPARK-7080,对应的设计文档为https://github.com/apache/ spark/pull/5725。读者可以基于这些设计文档,然后参考本节的源代码解析过程来加深理解。
在7.5 Tungsten Sorted Based Shuffle一节写数据的源代码解析中已经提到,在写数据时会使用一个外部排序器ShuffleExternalSorter对Shuffle数据进行排序,该外部排序器中的数据处理就是建立在Project Tungsten内存模型基础之上的。因此本节继续深入解析Shuffle写数据的过程,从Project Tungsten内存模型的使用角度来结合源代码进行解析。
首先,从前面对TaskMemoryManager的源代码解析可以知道,所有内存申请与释放的请求都是通过MemoryConsumer来提交的,因此首先需要了解在Shuffle的写过程中,外部排序器ShuffleExternalSorter与内存消费者MemoryConsumer之间的关系。为了了解这一点,可以先查看ShuffleExternalSorter类的注释与类定义,具体源代码如下。

可以看到,ShuffleExternalSorter继承了MemoryConsumer,因此在数据处理时可以向TaskMemoryManager申请/释放Execution内存。
对应的,其他建立在Project Tungsten内存模型基础上的数据处理也可以通过查看Memo-ryConsumer的子类来获取,比如前面SPARK-7080提到的设计文档中的BytesToBytesMap子类。
在详细解析源代码之前,同样先给出ShuffleExternalSorter在内存处理上的流程,如图8-9所示。
步骤如下。
1)首先是插入记录,由UnsafeShuffleWriter调用ShuffleExternalSorter的insertRecord方法,向currentPage插入一条记录,即图8-9中的第1步insertRecord。(https://www.xing528.com)
2)此时,如果当前页内存未分配,或剩余空间不足以容纳记录数据,则向TaskMemo-ryManager申请内存,即图8-9中的第2步allocatePage。
3)在申请内存时,有可能由于内存压力而发出MemoryConsumer(即这里的ShuffleEx-ternalSorter)的spill操作,即图8-9中的第3步spill。
4)触发spill操作时,会获取ShuffleInMemorySorter的排序数据的迭代器,将排序后的数据spill到文件中,即图8-9中的第8步getSortedIterator;同时再会释放ShuffleExternalSorter占用的内存(通过由记录的内存页allocatedPages实现),即图8-9中的第4步freePage。
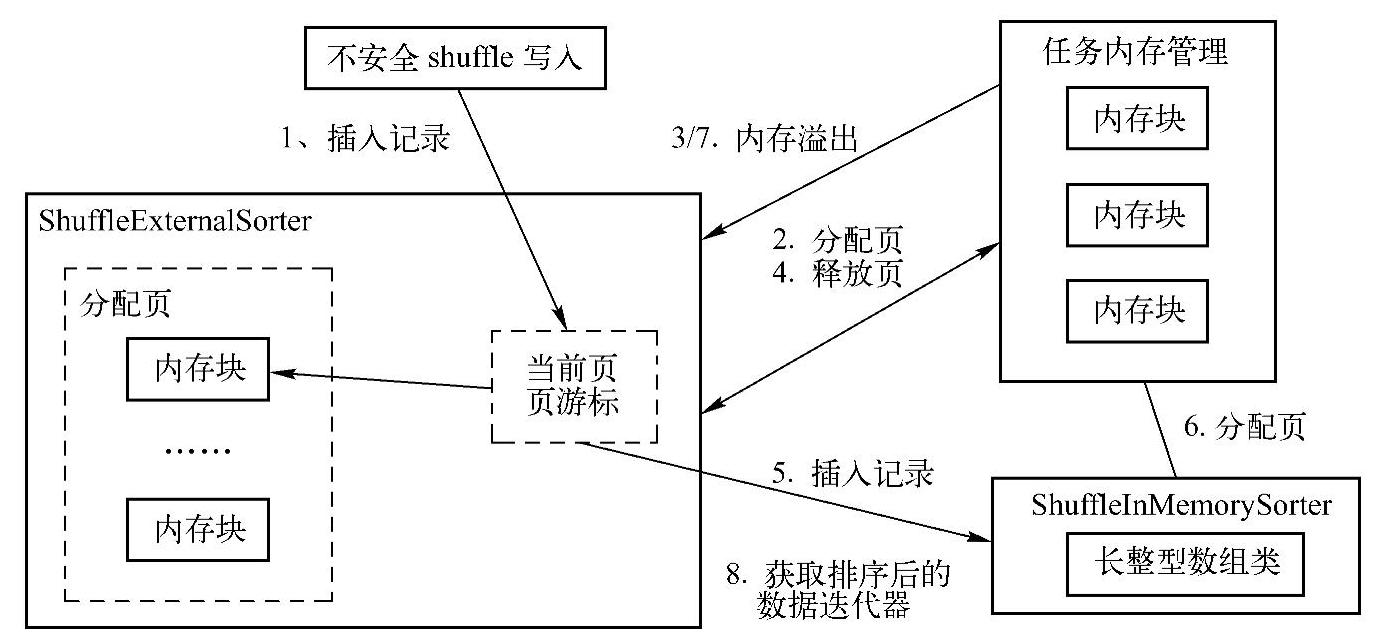
图8-9 ShuffleExternalSorter处理流程图
5)当currentPage能够容纳记录数据时,将数据插入到内存页中,同时会将记录的编码地址插入到ShuffleInMemorySorter的LongArray中,即图8-9中的第5步insertRecord。
6)插入编码的地址过程中,也可能会由于LongArray内存不足而向TaskMemoryManager申请内存,即图8-9中的第6步allocatePage。申请过程中也可能会触发spill,这和前面内存申请时描述的过程一样。
7)最后,在完成记录插入后也会调用第8步的getSortedIterator,获取在ShuffleInMemo-rySorter的LongArray中未spill到文件的内存数据,然后写入最后一个文件(所以这个文件写入的数据量不作为spill的Metric度量信息)。
在整个处理流程中,比较难以理解的是数据或地址在内存中的存储与处理(实际是用与存储相反的过程来读取数据进行处理,所以本质上还是理解数据是以何种方式存入内存页的)。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。