



Sorted Based Shuffle,即基于Sorted的Shuffle实现机制,在该Shuffle过程中,Sorted体现在输出的数据会根据目标的分区Id(即带Shuffle过程的目标RDD中各个分区的Id值)进行排序,然后写入一个单独的Map端输出文件中。相应的,各个分区内部的数据并不会再根据Key值进行排序,除非调用带排序目的的方法,在方法中指定Key值的Ordering实例,才会在分区内部根据该Ordering实例对数据进行排序。当Map端的输出数据超过内存容纳大小时,会将各个排序结果Spill到磁盘上,最后再将这些Spill的文件合并到一个最终的文件中。在Spark的各种计算算子中到处都体现了一种惰性的理念,在此也是类似,在提升性能需要时,引入根据分区Id排序的设计,同时仅在指定分区内部排序的情况下才会进行全局排序。而相比之下,Hadoop的MapReduce则带有一定的学术气息,中规中矩,严格设计Shuffle阶段中的各个步骤。
基于Hash的Shuffle实现,ShuffleManager的具体实现子类为HashShuffleManager,对应的具体实现机制如图7-6所示。
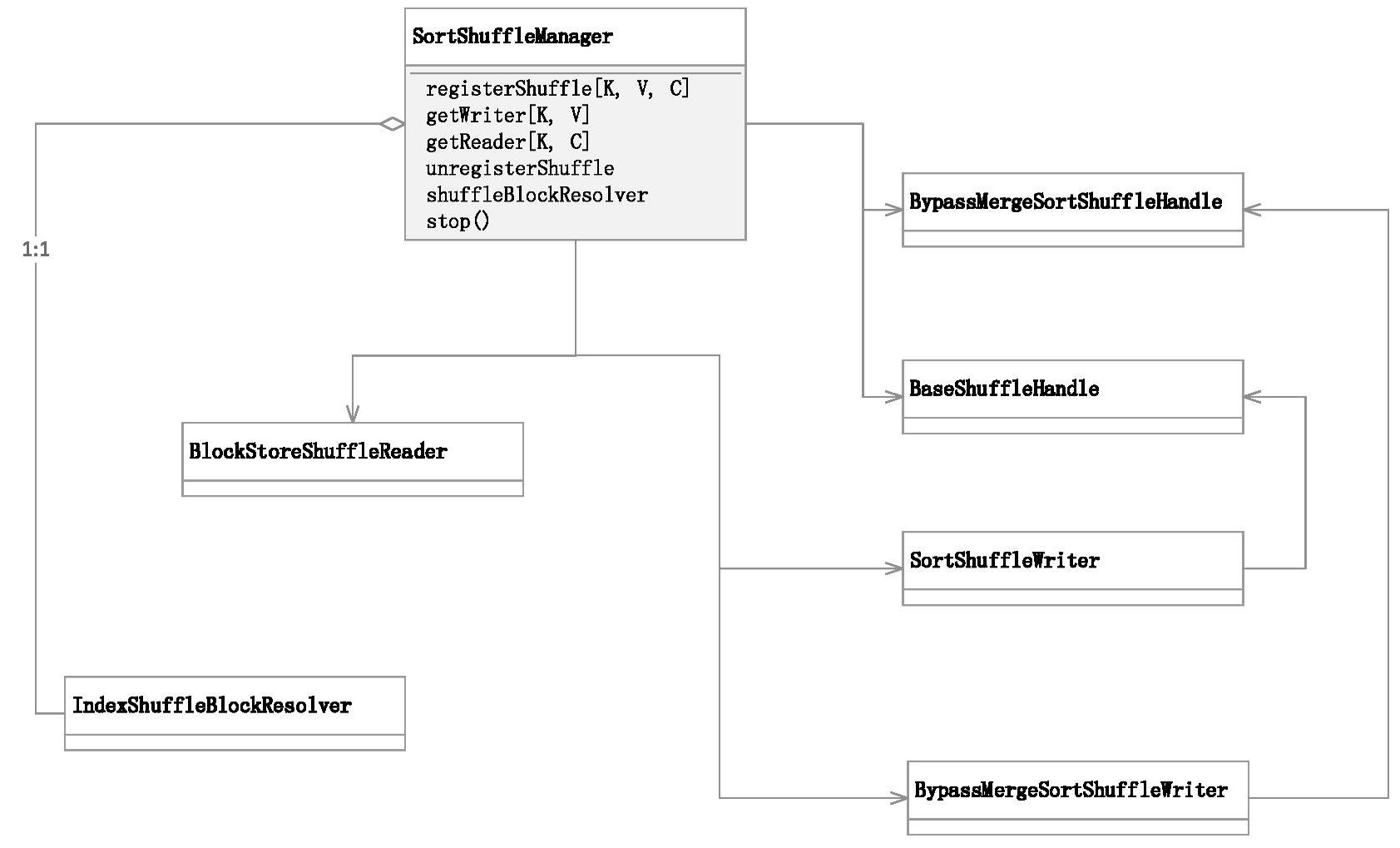
图7-6 基于Sorted的Shuffle实现机制的框架类图
在图7-6中,各个不同的ShuffleHandle与不同的具体Shuffle写入器实现子类是一一对应的,可以认为是通过注册时生成的不同ShuffleHandle设置不同的Shuffle写入器实现子类。
从ShuffleManager注册的配置属性与具体实现子类的映射关系,即前面提及的在Spark-Env中实例化的代码,可以看出"sort"与"tungsten-sort"对应的具体实现子类都是"org.apache.spark.shuffle.sort.SortShuffleManager"。也就是当前基于Sort的Shuffle实现机制与使用Tungsten项目的Shuffle实现机制都是通过SortShuffleManager类来提供接口,两种实现机制的区别在于该类中使用了不同的Shuffle数据写入器。
SortShuffleManager根据内部采用的不同实现细节,对应有两种不同的构建Map端文件输出的写方式(详细信息可以进一步参考SortShuffleManager的类注释),分别为序列化排序模式与反序列化排序模式。(https://www.xing528.com)
1)序列化排序(Serialized sorting)模式:这种方式对应新引入的基于Tungsten项目的方式。
2)反序列化排序(Deserialized sorting)模式:这种方式对应除了前面这种方式之外的其他方式。
基于Sort的Shuffle实现机制采用的是反序列化排序(Deserialized sorting)模式,下面分析该实现机制下的数据写入器的实现细节。
在图7-6中可以看到,基于Sort的Shuffle实现机制,具体的写入器的选择与注册得到的ShuffleHandle类型有关,参考SortShuffleManager类的registerShuffle方法,相关代码如下。


免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。