



1.基于Hash的Shuffle实现机制的内核框架
基于Hash的Shuffle实现,ShuffleManager的具体实现子类为HashShuffleManager,对应的具体实现机制如图7-3所示。
其中HashShuffleManager是ShuffleManager的基于Hash实现方式的具体实现子类。数据块的读写分别由BlockStoreShuffleReader与HashShuffleWriter实现;数据块的文件解析器则由具体子类FileShuffleBlockResolver实现;BaseShuffleHandle是ShuffleHandle接口的基本实现,保存Shuffle注册的信息。
HashShuffleManager继承自ShuffleManager,对应实现了各个抽象接口,基于Hash的Shuffle内部使用的各组件的具体子类如下。
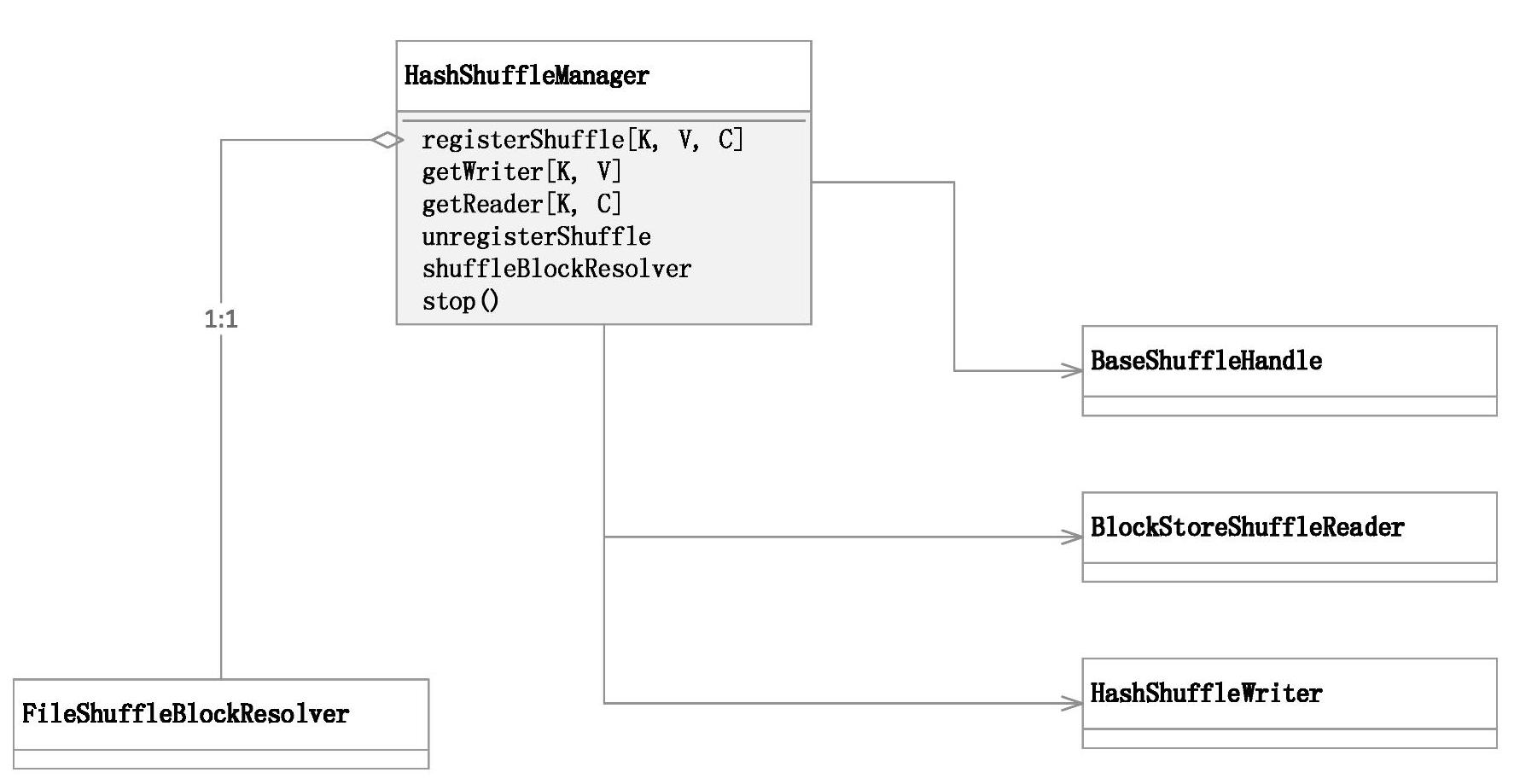
图7-3 基于Hash的Shuffle实现机制的内核框架
1)BaseShuffleHandle:携带了Shuffle最基本的元数据信息,包括shuffleId、numMaps和dependency。
2)BlockStoreShuffleReader:负责写入的Shuffle数据块的读操作。
3)FileShuffleBlockResolver:负责管理为Shuffle任务分配基于磁盘的块数据的Writer。每个Shuffle任务为每个Reduce分配一个文件。
4)HashShuffleWriter:负责Shuffle数据块的写操作。
在此与解析整个Shuffle过程一样,以HashShuffleManager类作为入口进行解析。
首先来看一下HashShuffleManager具体子类的注释,代码如下。

2.基于Hash的Shuffle实现方式一
为了避免Hadoop中基于Sort方式的Shuffle所带来的不必要的排序开销,Spark在开始时采用了基于Hash的Shuffle方式。但这种方式存在很多缺陷,这些缺陷大部分是由于基于Hash的Shuffle实现过程中创建了太多的文件所造成的。在这种方式下,每个Mapper端的Task运行时都会为每个Reduce端的Task生成一个文件,具体如图7-4所示。
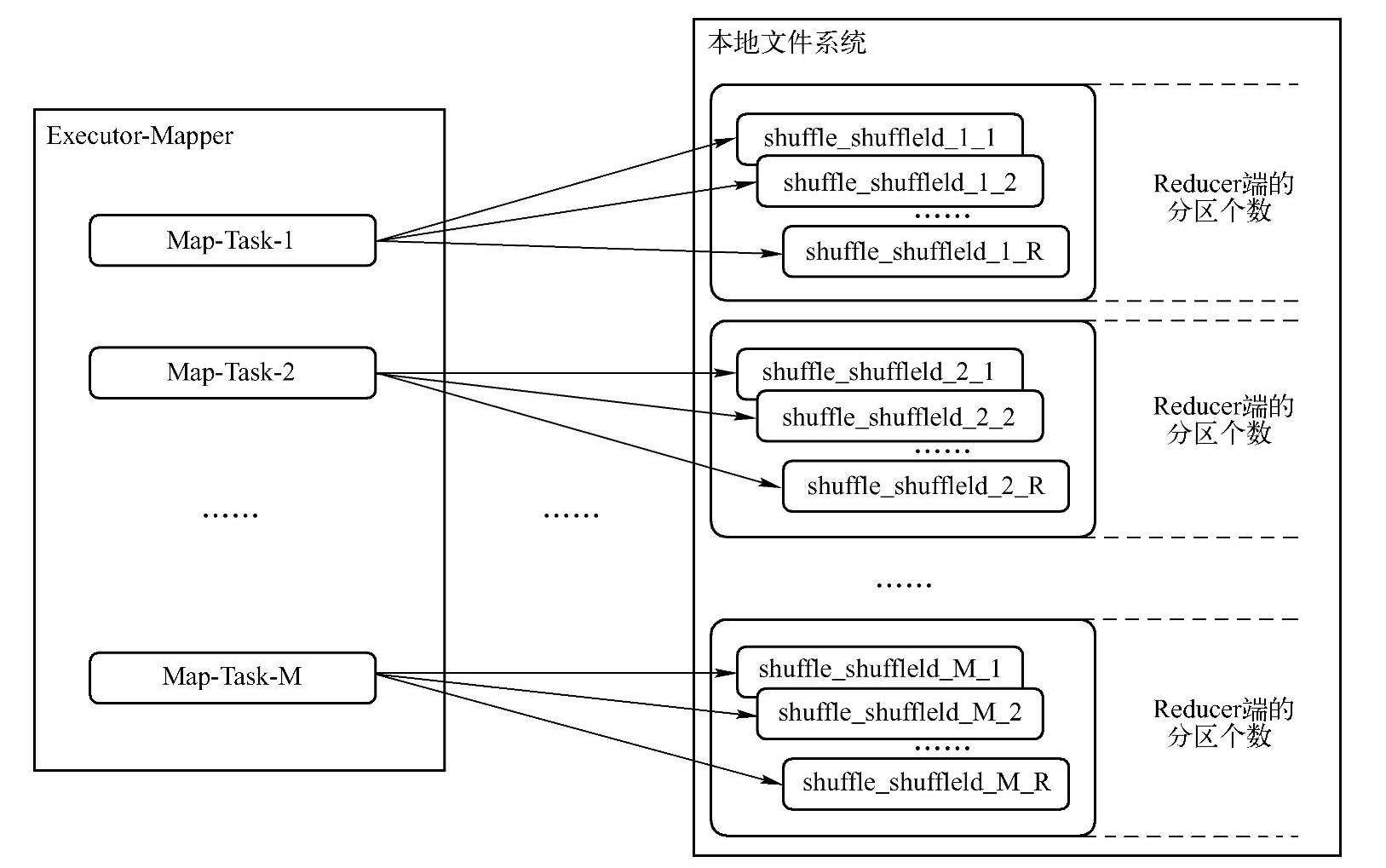
图7-4 基于Hash的Shuffle实现方式一文件的输出细节图
图7-4中,Executor-Mapper表示执行Mapper端的Task的工作点,可以分布到集群中的多台机器结点上,并且可以以不同的形式出现,比如以Spark Standalone部署模式中的Ex-ecutor出现,也可以以Spark On Yarn部署模式中的容器形式出现,关键是它代表了实际执行Mapper端的Tasks的工作点的抽象概念。其中,M表示Mapper端的Task的个数,R表示Reduce端的Task的个数。
对应在右侧的本地文件系统是在该工作点上所生成的文件,其中R表示Reduce端的分区个数。生成的文件名格式为:“shuffle_shuffleId_mapId_reduceId”,例如,其中的“shuffle_ shuffleId_1_1”表示mapId为1,同时reduceId也为1。
在Mapper端,每个分区对应启动一个Task,而每个Task会为每个Reduer端的Task生成一个文件,因此最终生成的文件个数为M×R。(https://www.xing528.com)
由于这种实现方式下,对应生成文件的个数仅仅与Mapper端和Reduce端各自的分区数有关,因此图7-4中将Mapper端的全部M个Task抽象到一个Executor-Mapper中,实际场景中通常是分布到集群中的各个工作点中。
生成的各个文件位于本地文件系统的指定目录中,该目录地址由配置属性“spark.local.dir”设置。
说明:分区数与Task数一个是静态的数据分块个数,一个是数据分块对应执行的动态任务个数的描述,因此在特定的描述个数的场景下,两者是一样的。
3.基于Hash的Shuffle实现方式二
为了减少图7-4中所生成的文件个数,对基于Hash的Shuffle实现方式进行了优化,引入了文件合并的机制,该机制设置的开关为配置属性“spark.shuffle.consolidateFiles”。在引入文件合并的机制之后,当设置配置属性为true,即启动文件合并时,在Mapper端的输出文件会进行合并,在一定程度上可以大量减少文件的生成,降低不必要的开销。文件合并的实现方式可以参考图7-5。

图7-5 基于Hash的Shuffle的合并文件机制的输出细节图
图7-5中,Executor-Mapper表示集群中分配的某个工作点,其中,C表示在该工作点上所分配到的内核(Core)个数,T表示在该工作点上为每个Task所分配的的内核个数。C/T表示在该工作点上调度时最大的Task并行个数。
对应在右侧的本地文件系统是在该工作点上所生成的文件,其中R表示Reduce端的分区个数。生成的文件名格式为:“merged_shuffle_shuffleId_bucketId_fileId”,其中的“merged_shuffle_shuffleId_1_1”表示bucketId为1,同时fileId也为1。
在Mapper端,Task会复用文件组,由于最大并行个数为C/T,因此文件组最多分配C/ T个,当某个Task运行结束后会释放该文件组,之后调度的Task则复用前一个Task所释放的文件组,因此会复用同一个文件。最终在该工作点上生成的文件总数为C/T×R,如果设工作点个数为E,则总的文件数为E×C/T×R。
4.基于Hash的Shuffle机制的优缺点
1)优点如下。
·可以省略不必要的排序开销。
·避免了排序所需的内存开销。
2)缺点如下。
·生成的文件数过多,会对文件系统造成压力。
·大量小文件的随机读写会带来一定的磁盘开销。
·数据块写入时所需的缓存空间也会随之增加,会对内存造成压力。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。