



Shuffle也称为“洗牌”,从字面含义上理解,就是对数据进行重组。在Master调度机制的实现源代码中,也可以看到Shuffle在数据重组上的一个应用场景,代码如下。

其中第4行代码就是使用了随机洗牌的方式对数据进行重组,重新整理数据的顺序来实现调度均衡的需求。此处的数据重组仅仅是顺序上的,而对应在MR框架中,本质上是将不同的数据重新组织到拆分的小数据块中(所以在某些场景下(协同分区),如果可以避免数据重组,或避免在迭代中多次不必要的数据重组,在构建RDD时,可以避免使用宽依赖来进行优化),只是重组数据的过程往往伴随着磁盘I/O与网络I/O等开销。
对应在Hadoop MapReduce框架或Spark框架中,Shuffle阶段本质上也是对数据进行重组,只是由于分布式计算的特性和要求,在实现的细节上会更加复杂。
在MapReduce框架中,Shuffle阶段是连接Map和Reduce之间的桥梁,Map阶段通过Shuffle过程将数据输出到Reduce阶段中。由于Shuffle涉及磁盘的读写和网络I/O,因此Shuffle性能的高低直接影响整个程序的性能。Spark本质上也是一种MapReduce框架,因此也会有自己的Shuffle过程实现。
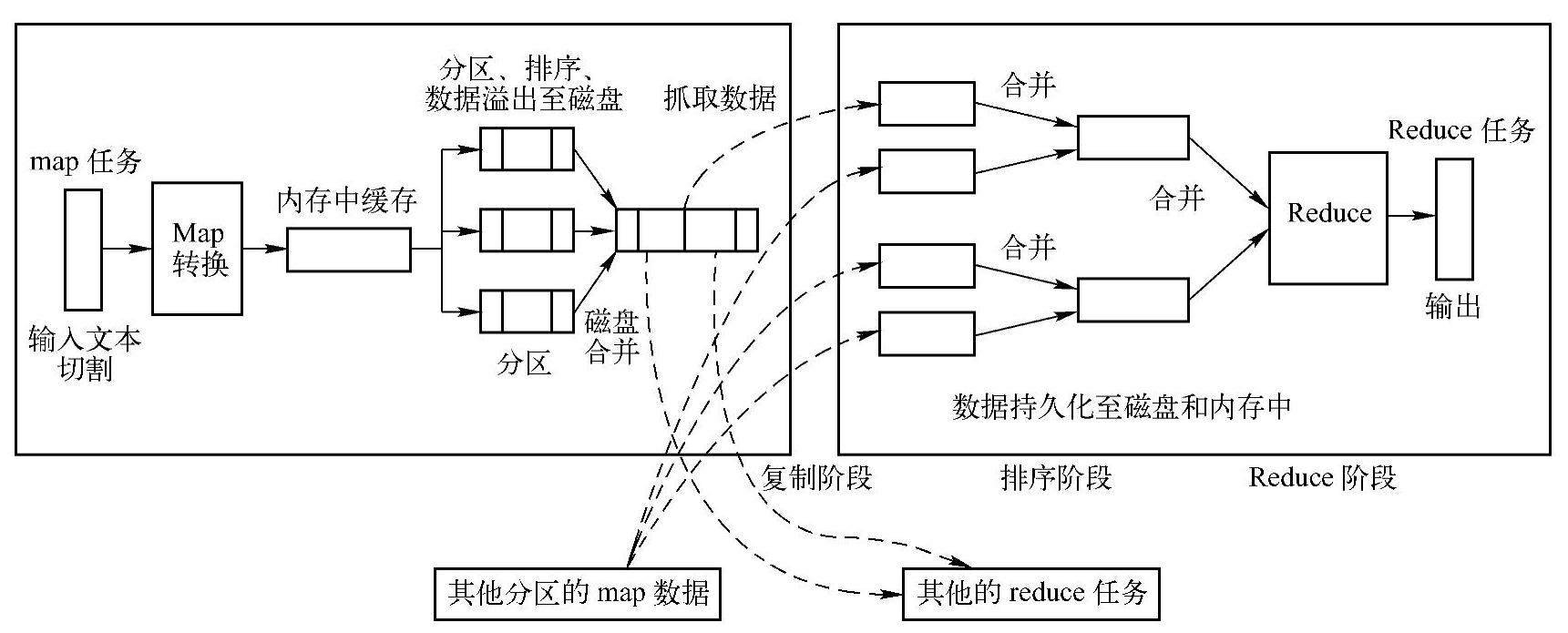
在学习Shuffle的过程中,通常都会引用Hadoop MapReduce框架中的Shuffle过程作为入门或比较,同时也会引用Hadoop MapReduce框架的Shuffle过程中常用的术语,下面参考网络上描述该过程经典的框架图,如图7-1所示。
 (https://www.xing528.com)
(https://www.xing528.com)
图7-1 Hadoop MapReduce框架中的Shuffle框架
其中,Shuffle是MapReduce框架中的一个特定阶段,介于Map阶段和Reduce阶段之间。Map阶段负责准备数据,Reduce阶段则读取Map阶段所准备的数据,然后进一步对数据进行处理。即Map阶段实现Shuffle过程中的数据持久化(即数据写入),而Reduce阶段实现Shuffle过程中的数据读取。
在图7-1中,Mapper端与Reduce端之间的数据交互通常都伴随着一定的网络I/O,因此对应数据的序列化与压缩等技术也是Shuffle中必不可少的一部分。可以根据特定场景选取合适的序列化方式与压缩算法进行调优,在此仅给出相关的配置属性的简单描述,具体如表7-1所示。
表7-1 Shuffle序列化方式与压缩算法的配置属性

可以基于图7-1所示的框架,抽象地理解Shuffle阶段的实现过程,但在具体的实现上,不同的Shuffle设计会有不同的实现细节。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。