



Tachyon(意为超光速粒子)是以内存为中心的分布式文件系统(2016年2月更名为Alluxio),拥有高性能和容错能力,能够为集群框架(如Spark、MapReduce等)提供可靠的内存级速度的文件共享服务。从软件栈的层次来看,Tachyon是位于现有大数据计算框架和大数据存储系统之间的独立的一层。它利用底层文件系统作为备份,对于上层应用来说,Tachyon就是一个分布式文件系统。
Tachyon诞生于UC Berkeley的AMPLab,其最初出现是为了解决如下问题。
·大数据分析流水线中,数据共享通过基于磁盘文件系统(HDFS等)性能比较缓慢。
·大数据计算引擎的处理进程(如Spark的Executor,MapReduce的Child JVM等)崩溃出错后,缓存的数据也会全部丢失。
·基于内存的系统存储数据冗余,对象太多会导致Java GC时间过长。
Tachyon在大数据分析软件栈(Berkeley Data Analytics Stack)中的所属层次如图6-5所示。(https://www.xing528.com)
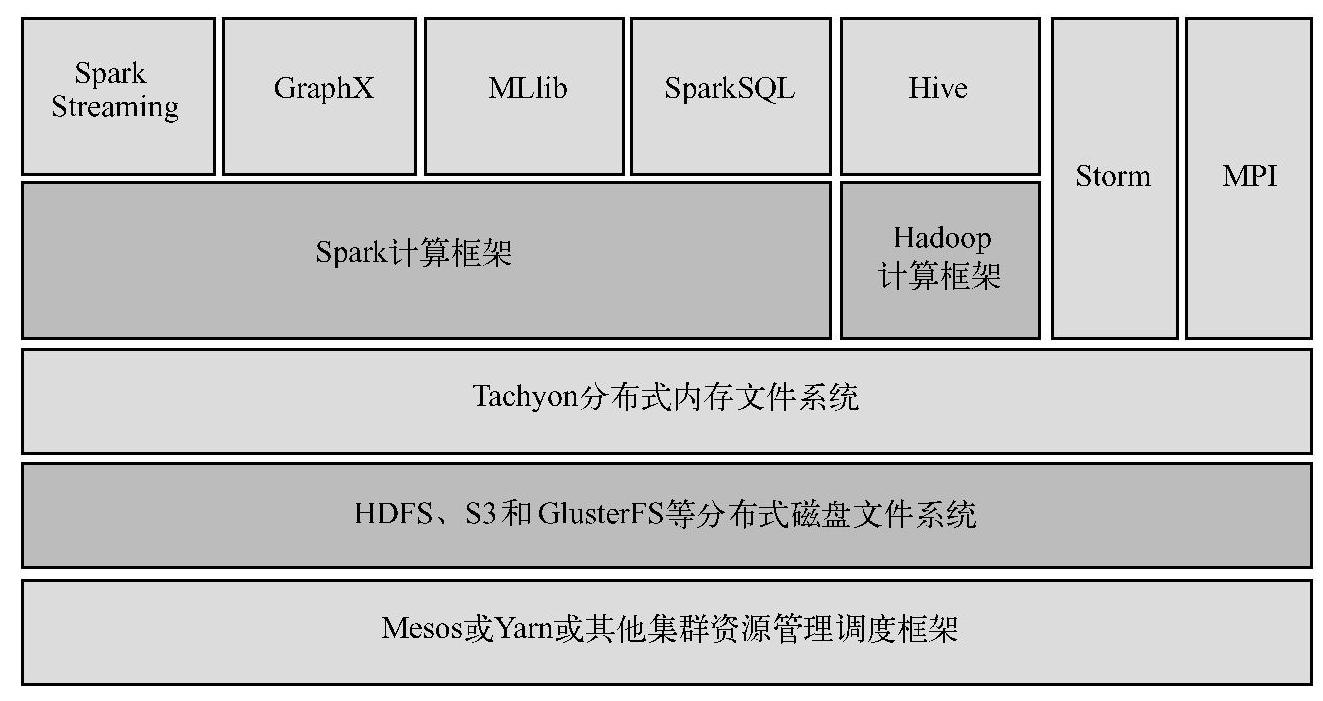
图6-5 Tachyon在大数据软件栈中的地位
从图6-5中可见,Tachyon是架构在最底层的分布式文件存储和上层的各种计算框架之间的一种中间件,主要职责是将那些不需要落地到磁盘里的文件落地到分布式内存文件系统中,以共享内存,从而提高效率。同时可以减少内存冗余、GC时间等。
Tachyon的架构是传统的Master—Slave架构,为了防止单点故障,可以使用Zookeeper做HA。Tachyon中使用RamDisk(内存磁盘)技术来提高对文件的访问速度,Tachyon中Master和Worker直接的通信协议是Thrift。
Tachyon技术在业界引起了广泛的关注,其开源社区也越来越活跃。在本节中,将以Tach-yon最新版本0.8.2来讲解,因为在Spark 1.6.∗中,Tachyon采用的就是0.8.2版本。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。