



ExecutorBackend是一个和集群交互的接口,该接口在不同的调度模式下有不同的实现。图5-3所示是ExecutorBackend及其实现的关系类图。
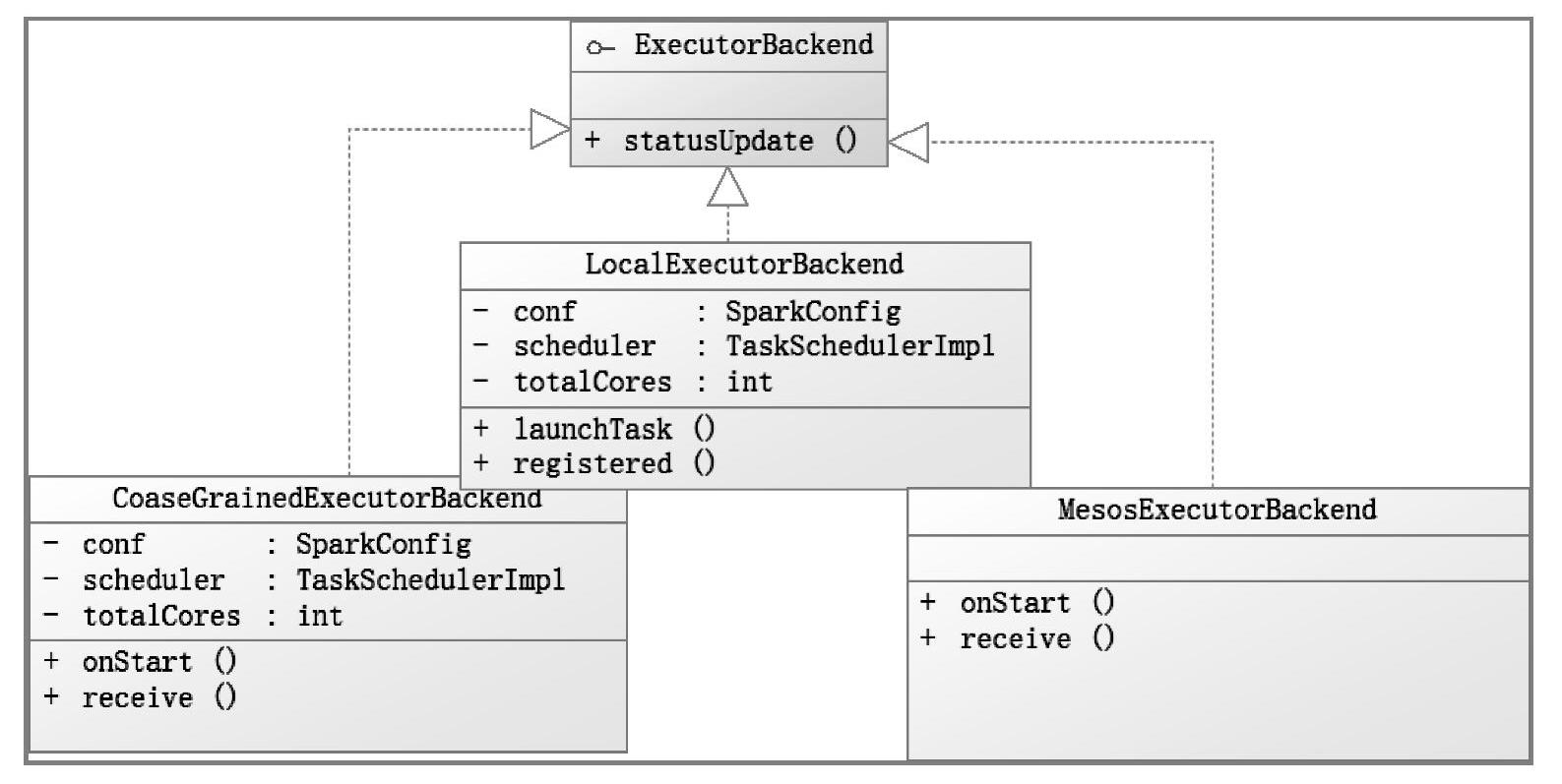
图5-3 ExecutorBackend的不同实现
不同模式下,ExecutorRunner启动的进程是不一样的。在Standalone模式下,启动的是org.apache.spark.executor.CoarseGrainedExecutorBackend进程;在Local模式下启动的是org.apache.spark.executor.LocalExecutorBackend进程;在Mesos模式下启动的是org.apache. spark.executor.MesosExecutorBackend进程。
下面来看一下Standalone模式下CoarseGrainedExecutorBackend的启动。在Standalone模式下,会启动org.apache.spark.deloy.Client类,该类将向Master发送RequestSubmitDriver(driverDescription)消息,Master中匹配到RequestSubmitDriver(driverDescription)后,将会调用schedule()方法。该调用源代码如下所示。

 (https://www.xing528.com)
(https://www.xing528.com)

上面代码中,RecoveryState若不为ALIVE,则直接返回,否则使用Random.shuffle将Worker集合打乱生成新的集合shuffledWorkers,这样会尽量考虑到选择Driver的负载均衡。在for语句中遍历shuffledWorkers,首先,若Worker的WorkerStage为ALIVE,则遍历wait-ingDrivers队列,判断Worker剩余内存和剩余物理核是否满足Driver需求,如满足则调用launchDriver(worker,driver)方法在选中的Worker上启动Driver进程。
Driver在Worker结点上启动起来之后,会实例化SparkContext,在SparkContext中将实例化出DAGScheduler和SparkDeloySchedulerBackend。在SparkDeploySchedulerBackend中将会new一个AppClient,AppClient中有一个ClientEndpoint,在其onStart方法中将向Master发送RegisterApplication请求注册application,注册好application之后Master又会调用schedule方法。在满足条件的Worker上为application启动Executor,首先会启动ExecutorRunner,在Ex-ecutorRunner中启动CoarseGrainedExecutorBackend,启动后将会实例化出Executor。为什么在Standalone模式下会启动CoarseGrainedExecutorBackend呢?是在什么地方设置要启动Coar-seGrainedExecutorBackend进程的呢?其实在实例化AppClient时,就已经传入了,源代码如下所示。

上面代码中的第2行设置了Command对象,Command对象的第一个参数是启动进程的mainClass。因此在ExecutorRunner中启动进程时,启动的即是org.apache.spark.executor. CoarseGrainedExecutorBackend。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。