



在此详细分析在Standalone模式下ExecutorBackend和Executor的关系。在SparkDeploy-SchedulerBackend中会实例化一个AppClient。AppClient中携带了command信息,在com-mand信息中指定了要启动的ExecutorBackend的实现类。在Standalone模式下,该Executor-Backend的实现类是org.apache.spark.executor.CoarseGrainedExecutorBackend类。SparkDe-ploySchedulerBackend中实例化AppClient的源代码如下所示。
上面代码中的第2行构建了一个Command对象,该对象的第一个参数表示main-Class,即进程的主类。该类在Standalone模式下为org.apache.spark.executor.CoarseG-rainedExecutorBackend。分别得到sparkJavaopts、javaOpts、command、appUiAddress、co-resPerExecutor及appDes传入AppClient的构造函数。AppClient将会向Master发送Regis-terApplication注册请求,Master受理后通过launchExecutor方法在Worker结点启动一个ExecutorRunner对象,该对象用于管理一个Executor进程。在ExecutorRunner中将通过CommandUtil构建一个ProcessBuilder,调用ProcessBuilder的start方法将会以进程的方式启动org.apache.spark.executor.CoarseGrainedExecutorBackend。在CoarseGrainedExecotor-Backend的onStart方法中,将会向Driver端发送RegisterExecutor(executorId,self,host-Port,cores,extractLogUrls)消息请求注册,完成注册后将立即返回一个RegisteredExecu-tor(executorAddress.host)消息,CoarseGraiendExecutorBackend收到该消息,马上实例化出一个Executor。源代码如下所示。

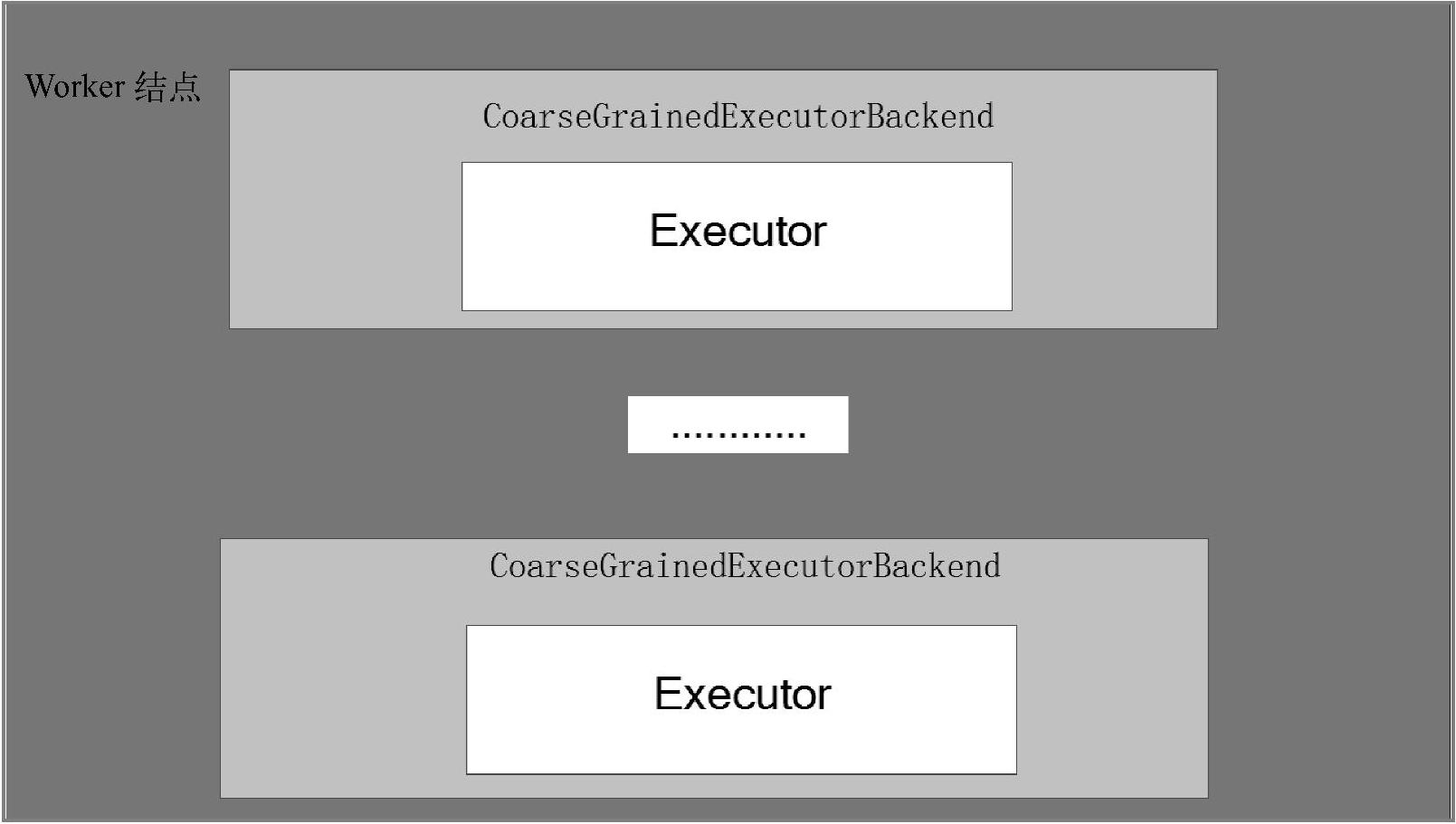
从这里可以看出,CoarseGrainedExecutorBackend比Executor先实例化。CoarseGrainedEx-ecutorBackend负责与集群通信,而Executor则专注于任务的处理,它们是一对一的关系,在集群中各司其职,其关系如图5-2所示。
 (https://www.xing528.com)
(https://www.xing528.com)
图5-2 CoarseGrainedExecutorBackend和Executor
每一个Worker结点上可以启动多个CoarseGrainedExecutorBackend进程,每一个进程对应一个Executor。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。