



Spark Application里面可以产生1个或者多个Job,例如spark-shell默认启动的时候内部就没有Job,只是作为资源的分配程序,可以在spark-shell里面写代码产生若干个Job,普通程序中一般而言可以有不同的Action,每一个Action一般也会触发一个Job。
有了Job的逻辑执行图,如何生成物理执行图,也就是给定这样一个复杂数据依赖图,如何合理划分Stage,并确定Task的类型和个数?
一个直观的方法是将前后关联的RDD组成一个Stage,每个Stage生成一个Task。这样虽然可以解决问题,但显然效率不高。除了效率问题,这个方法还有一个更严重的问题:大量中间数据需要存储。对于Task来说,其执行结果要么要存到磁盘,要么存到内存,或者两者皆有。如果每个箭头都是Task的话,每个RDD里面的数据都需要存起来,占用空间可想而知。
仔细观察一下逻辑执行图会发现:在每个RDD中,每个Partition是独立的,也就是说在RDD内部,每个Partition的数据依赖各自不会相互干扰。因此,一个大胆的想法是将整个流程图看成一个Stage,为最后一个finalRDD中的每个Partition分配一个Task。即Pipeline思想:数据用的时候再算,而且数据是流到要计算的位置的。
Spark算法构造和物理执行时最最基本的核心:最大化Pipeline!基于Pipeline的思想,数据被使用的时候才开始计算,从数据流动的视角来说,是数据流动到计算的位置。实质上从逻辑的角度来看,是算子在数据上流动!从算法构建的角度而言:肯定是算子作用于数据,所以是算子在数据上流动;方便算法的构建!
从Job物理执行的角度而言:是数据流动到计算的位置,方便系统最为高效的运行。对于Pipeline而言,数据计算的位置就是每个Stage中最后的RDD。也就是说:每个Stage中除了最后一个RDD算子是真实的以外,前面的算子都是“假”的!由于计算的Lazy特性,计算是从后往前回溯,形成Computing Chain,结果需要首先计算出具体一个Stage内部左侧的RDD中本次计算依赖的Partition。如图4-4所示:
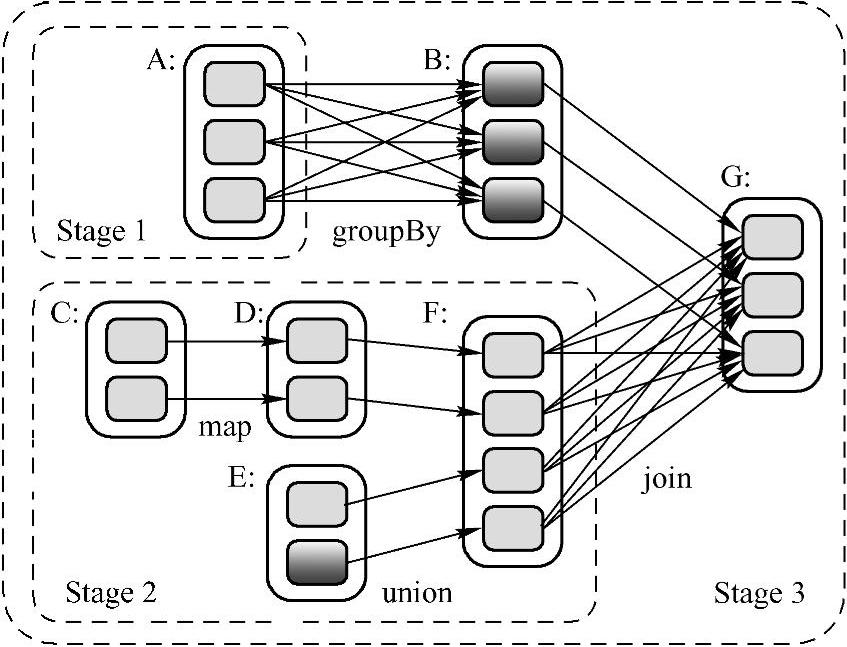
图4-4 RDD算子计算过程
来将parent RDD中的Record一个个“拿”(fetch)过来。
例如,collect前面的RDD是transformation级别的,不会立即执行。从后往前推,回溯时如果是窄依赖则在内存中迭代,否则把中间结果写出到磁盘暂存给后面的计算使用。
依赖分为窄依赖和宽依赖。例如现实生活中,工作依赖一个对象,是窄依赖,依赖很多对象,是宽依赖。窄依赖除了一对一外,还有range级别的依赖,依赖固定的个数,随着数据的规模扩大而改变。
如果是宽依赖,DAGScheduler会划分成不同的stage,stage内部是基于内存迭代的,也可以基于磁盘迭代,stage内部计算的逻辑是完全一样的,只是计算的数据不同而已。具体的任务就是计算一个数据分片,一个partition的大小是128Mb。一个partition不是完全精准的等于一个block的大小,一般最后一条记录跨两个block。
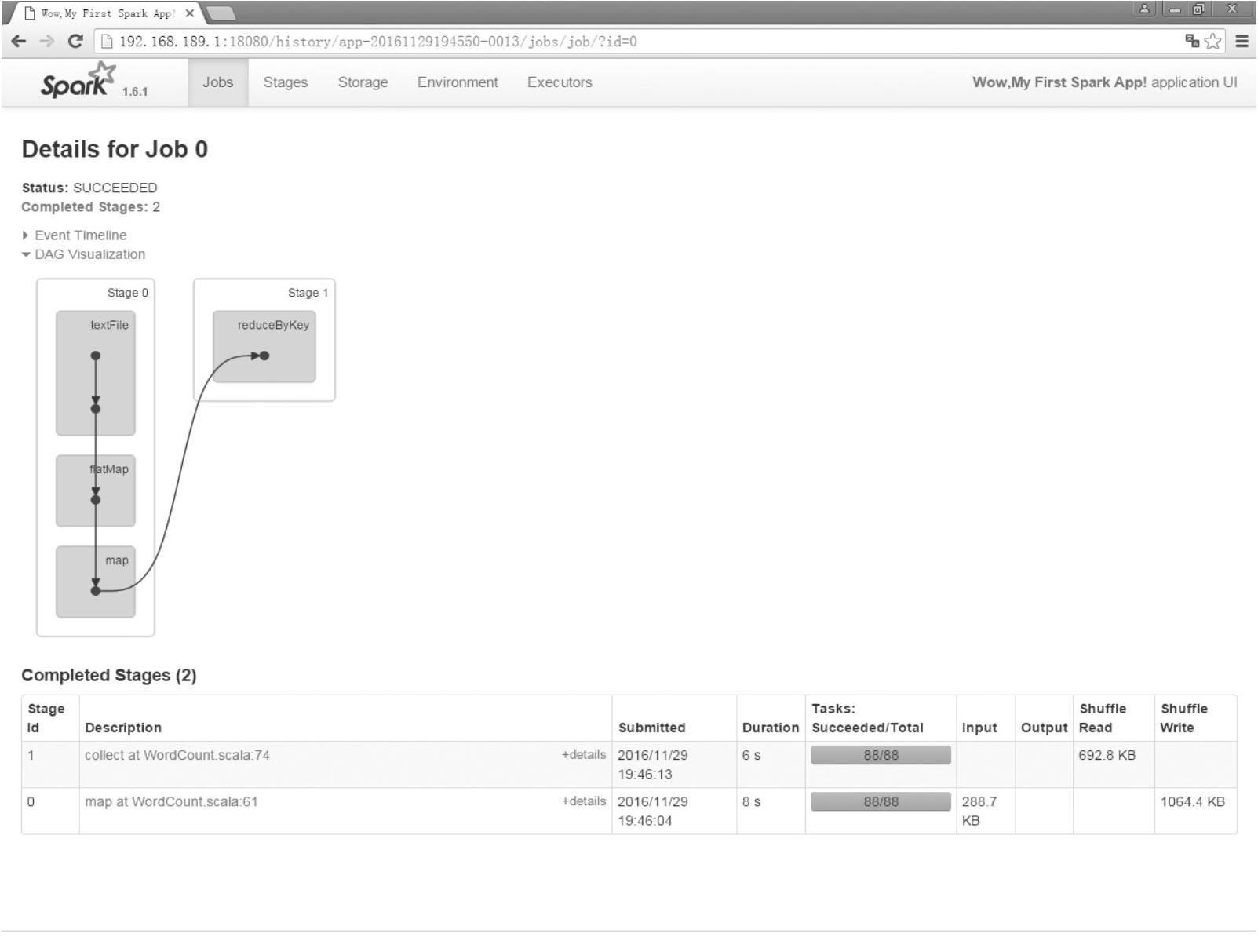
如图4-5所示,因为reduceByKey会产生shuffle(宽依赖),所以这里有两个Stage。因为collect操作是一个action,所以会触发Job。从后往前推,每个stage内部都有一系列的任务,下面来看第一个Stage。Stage 0内部的textFile、flatMap、map默认基于内存迭代,如果内存不够会基于磁盘迭代。
 (https://www.xing528.com)
(https://www.xing528.com)
图4-5 Job 0的所有Stage视图
如图4-6所示,Stage 0总共有88个任务,图中方框内清楚地告诉用于运行了哪些代码。在具体运行时,stage内部没有SparkContext和SparkConf。因为它们属于核心Driver层面。
如图4-7所示,任务都是运行在Executor中。默认每台机器为当前的程序分配一个Ex-ecutor,这里有4个Worker,所以有4个Executor。可以看到每个Executor上的任务运行情况。Worker本身就是管理Executor的。
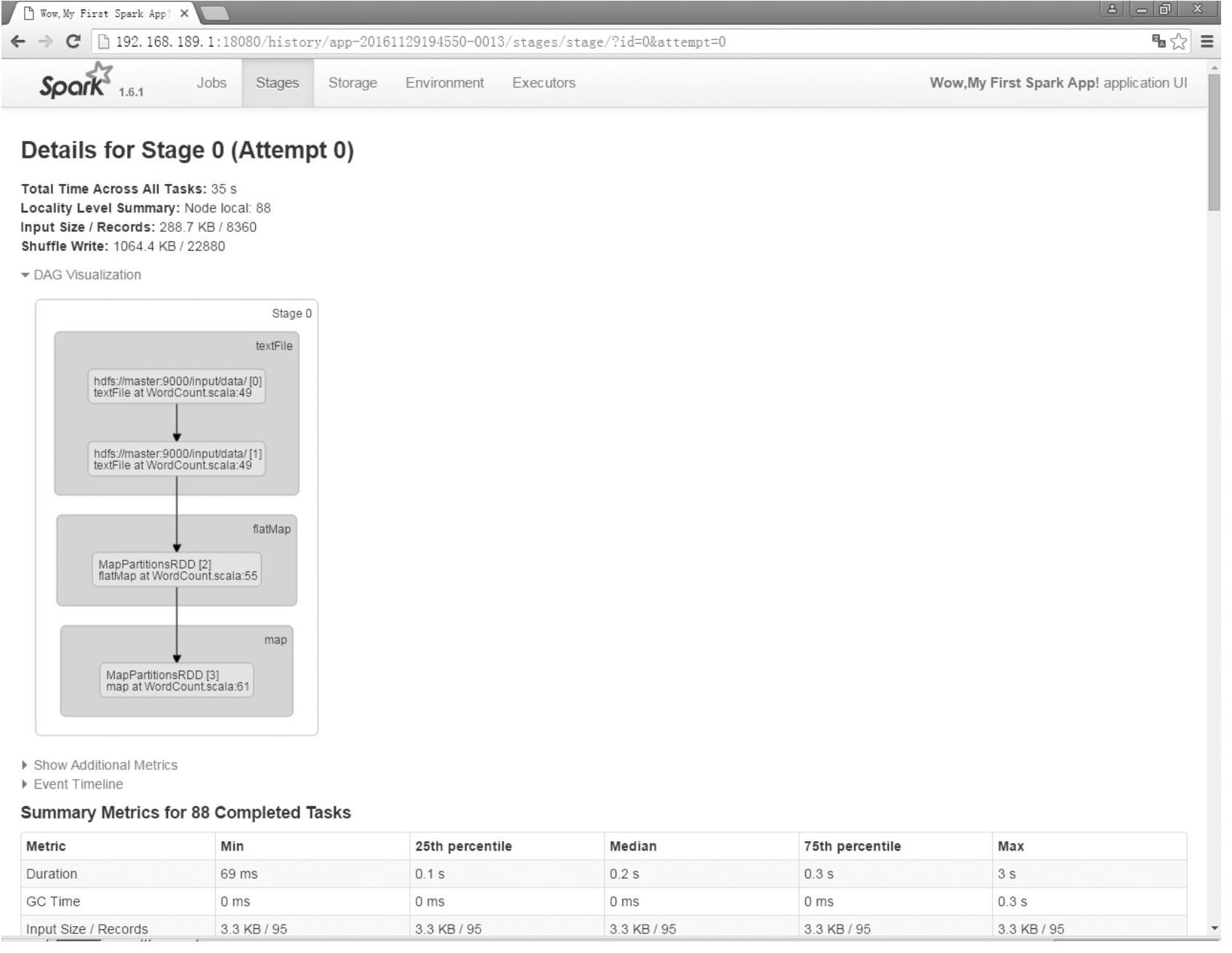
图4-6 Stage 0视图

图4-7 Worker中的Executor级别的任务运行视图
如图4-8所示,Tasks运行在不同的机器上。
Spark程序的运行有两种部署方式:Client和Cluster。
默认情况下建议使用Client模式,此模式下可以看到更多的交互性信息及运行过程的信息。此时要专门使用一台机器来提交Spark程序,配置和普通的Worker配置一样,而且要和Cluster Manager在同样的网络环境中,因为要指挥所有的Worker去工作,Worker里的线程要和Driver不断地交互。由于Driver要驱动整个集群,频繁地与所有为当前程序分配的Executor去交互,频繁地进行网络通信,所以必须在同样的网络中。
也可以指定部署方式为Cluster,这样Driver会由Master决定在Worker中的某一台机器。Master为用户分配的第一个Executor就是Driver级别的Executor。不推荐学习和开发时使用Cluster,因为Cluster无法直接看到一些日志信息,所以建议使用Client方式。
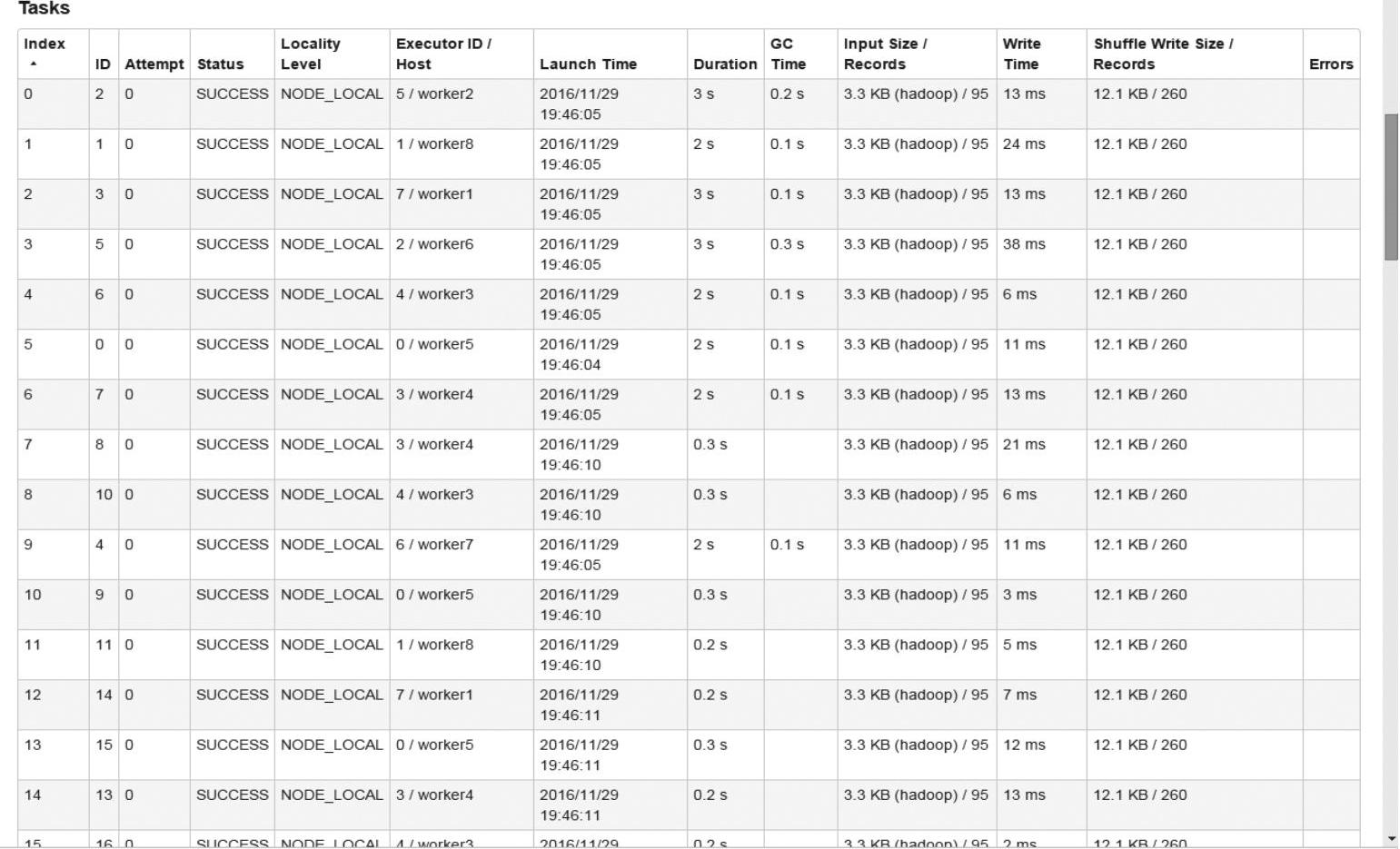
图4-8 Task级别的运行视图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。