



【摘要】:典型的Job逻辑执行图如下图4-3所示,经过下面四个步骤可以得到最终执行结果:图4-3 Job逻辑执行图1)从数据源读取数据,创建最初的RDD;2)对RDD进行一系列的transformation()操作,每一个transformation()会产生一个或多个包含不同类型T的RDD[T]。但如果是(K,V),K不能是Array等复杂类型;3)对最后的final RDD进行action()操作,每个Partition计算后产生结果Result。RDD中的Partition个数不固定,通常由用户设定。在每个Stage中,每个RDD中的compute()调用parentRDD.iter()
典型的Job逻辑执行图如下图4-3所示,经过下面四个步骤可以得到最终执行结果:
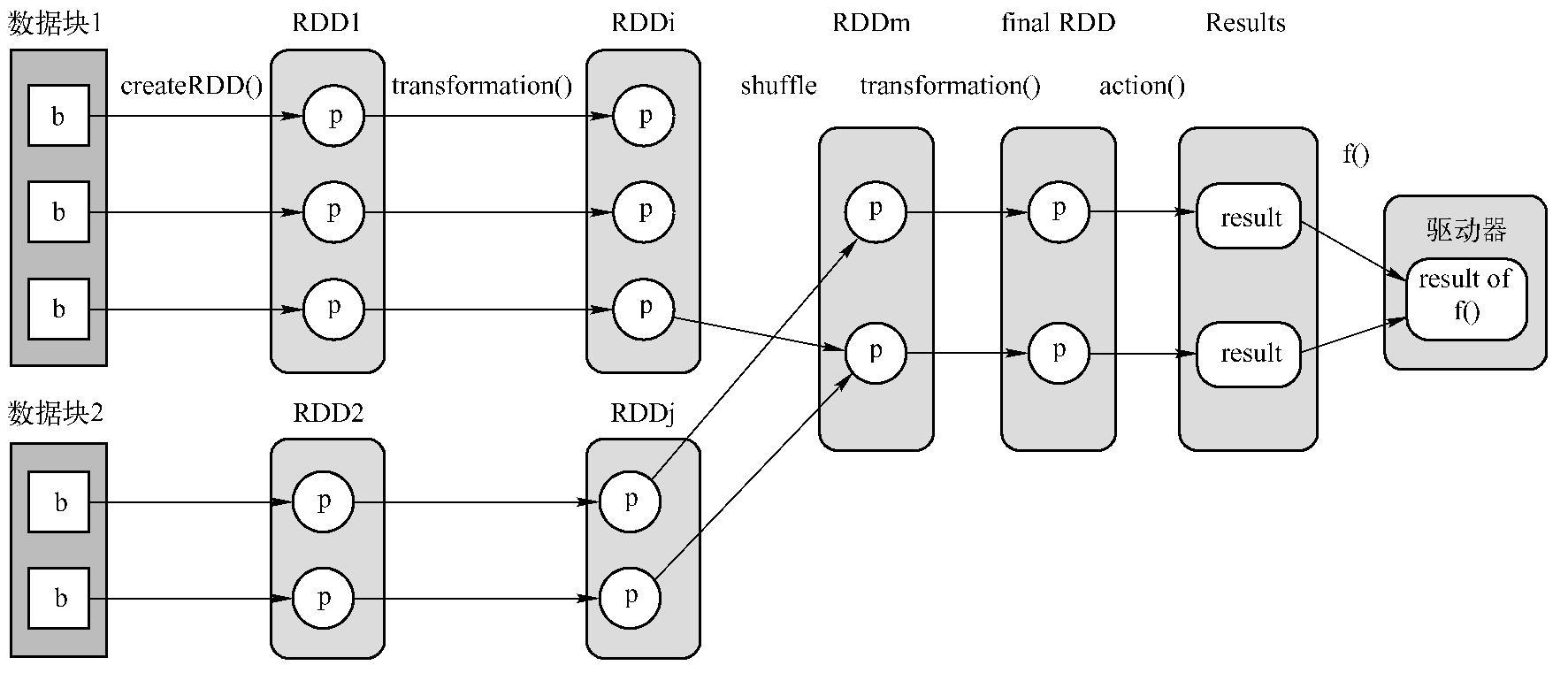
图4-3 Job逻辑执行图
1)从数据源(数据源可以是本地File、内存数据结构、HDFS、HBase等)读取数据,创建最初的RDD(createRDD());
2)对RDD进行一系列的transformation()操作,每一个transformation()会产生一个或多个包含不同类型T的RDD[T]。T可以是Scala里面的基本类型或数据结构,不限于(K,V)。但如果是(K,V),K不能是Array等复杂类型(因为难以在复杂类型上定义partition函数);(https://www.xing528.com)
3)对最后的final RDD进行action()操作,每个Partition计算后产生结果Result。
4)将Result回送到Driver端,进行最后的f(list[result])计算。例子中的count()实际包含了action()和sum()两步计算。RDD可以被Cache到内存或者Checkpoint到磁盘上。RDD中的Partition个数不固定,通常由用户设定。RDD和RDD之间Partition的依赖关系可以不是1对1,如图4-3所示,既有1对1关系,也有多对多的关系。
总结一下这个过程:整个Computing Chain根据数据依赖关系自后向前建立,遇到Shuf-fleDependency后形成Stage。在每个Stage中,每个RDD中的compute()调用parentRDD.iter()
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。