



本章默认讲解的内容都是基于Spark的Standalone部署模式。在Standalone部署模式下,Spark比在YARN和Mesos更容易使用,因为不需要其他的东西。如果是基于Spark来处理数据,基本上一个Spark框架就可以了,无须使用YARN或者Mesos等(如果掌握了Standa-lone模式,掌握Yarn或者Mesos是没有问题的,因为它们80%的原理都是类似的)。
如图4-1所示,SparkContext在创建DAGScheduler、TaskScheduler、SchedulerBackend的同时还会向Master注册程序。如果注册没有问题的话,Master通过Cluster Manager会给这个程序分配资源,然后根据Action触发Job。Job里面有一系列RDD,DAGScheduler从后往前推若发现是宽依赖的话,就划分不同的Stage。Stage划分完成之后,Stage提交给底层的调度器TaskScheduler,TaskScheduler拿到这个Task的集合。因为一个Stage内部都是计算逻辑完全一样的任务,只不过是计算的数据不同。TaskScheduler就会根据数据的本地性,将任务分配到Executor上去执行。Executor在任务运行结束或者出状况时,肯定要向Driver汇报。最后运行完毕之后,关闭SparkContext,同时其创建的那些对象也要关闭掉。
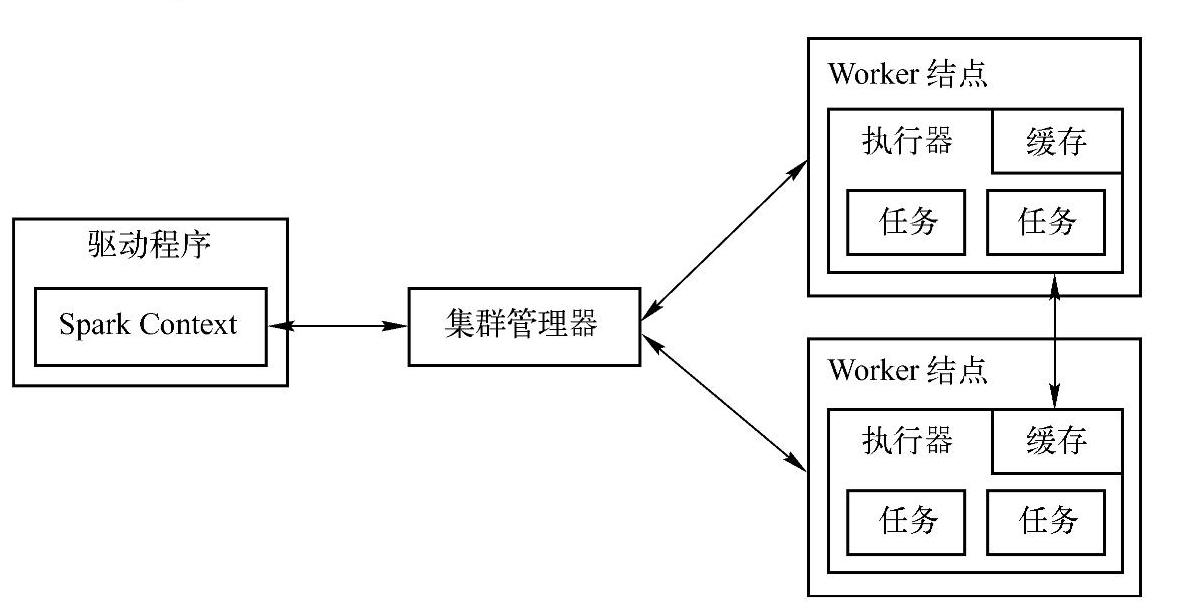
图4-1 Spark运行框架图
第3章已经介绍了对Driver、Worker和Executor等Spark运行框架的主要组件的基本概念,下面分别对这些组件的基本运行原理给予更为详细的阐述。(https://www.xing528.com)
Driver是应用程序运行时的核心,它负责整个作业的调度,同时会向Master申请资源完成具体作业的工作过程。所谓应用程序,就是用户编写的Spark代码打包后的jar包和相关的依赖,其中包括Driver功能的代码和分布在集群中多个结点的Executor代码。Driver是驱动Executor去工作,Executor内部是线程池并发地去处理数据分片的。Driver部分的代码就是Sparkconf和SparkContext部分。SparkContext在创建时包含很多内容,包括DAGScheduler、TaskScheduler、Schedulerbackend和Spark-Env等(一个程序默认有一个DAGScheduler)。所以一个Spark Application通常包含:Driver端的代码和分布在集群中多个结点上的Executor 的代码。如textFile、flatMap和map等可以产生很多RDD的方法是具体的业务实现,也就是Executor中具体要执行的代码。所有的业务逻辑都是在具体的集群Worker上的Executor上执行的(前提是代码要发送到集群上)。
Cluster Manager是集群中获取资源的Web服务。在Spark的最初阶段并没有YARN模式,也没有Standalone模式,资源管理服务是Mesos,后来增加了YARN,后来为了推广普及产生了Standalone。最重要的特征是:Spark的Application的运行不依赖于Cluster Manag-er。也就是说Spark的Application注册给Master,如果注册成功,Master提前给Application分配好了资源,运行过程中根本不需要Cluster Manager的参与。Cluster Manager是可插拔的。这种资源的分配方式是粗粒度的。集群中的具体工作,除了Cluster Manager、Master和资源分配器外,这些都是处于主结点上。
Executor是运行在Worker结点上的为当前应用程序开启进程里的处理对象。这个对象负责具体的Task运行,是通过线程池并发运行和线程复用的方式。Spark在一个结点上为当前的程序开启一个JVM进程,JVM进程是线程池的方式,通过线程处理具体的Task任务。Executor是进程里的对象。一个Worker默认为当前的应用程序开启一个Executor(可以配置多个)。Executor靠线程池中的线程运行Task时,肯定会去磁盘或者内存中读写数据。每个Application都有自己独立的一批Executor。
Worker是集群中任何可以运行Application具体的textFile、flatMap、map、filter和redu-ceByKey等这些操作代码的结点。Worker上是不会运行程序代码的,Worker是管理当前结点CPU、内存等资源的使用状态,它会接收Master分配资源(即Executor)的指令,会通过ExecutorRunner启动一个新进程,进程里面有Executor。为了便于理解,可以把Cluster Man-ager看成是项目经理,Worker是工长,项目经理(Cluster Manager)会管理很多工长(Worker),工长下面有很多工人(Executor)。所以,Worker管理当前结点的计算资源(主要是CPU和内存),并接收Master的指令,来分配具体的计算资源(在新的进程中分配)。要分配一个新的进程做计算时,ExecutorRunner相当于一个代理,管理具体新分配的进程,也监控具体的Executor所在进程运行的状况。其实就是在ExecutorRunner中远程创建出新的进程的。Woker是一个进程,不会向Master汇报当前机器的CPU和内存等信息。Worker发送心跳汇报的信息只有Workerid。应用程序注册成功时,Master会给应用程序分配资源,分配时都会记录资源。如果中间Executor有丢失的情况,Worker要向Master汇报,然后动态地调整资源。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。