



1.Master HA部署脚本的解析
通过前面对Master启动脚本的分析,可以知道内部是使用启动守护进程的脚本spark-daemon.sh来启动Master实例。脚本spark-daemon.sh启动时会检查当前实例的pid是否已经存在,因此,如果想在单机上模拟出一个Master HA的部署集群,需要手动修改Master实例的序号,这样才能在单机上同时启动多个Master实例。原有启动Master实例的代码如下。

其中,第1行传递给脚本spark-daemon.sh的实例序号为1,如果需要单机启动第二个Master实例来模拟Master HA,需要修改该序号1为2,对应的代码修改如下。

此时再次使用脚本启动后,对应的SPARK_MASTER_WEBUI_PORT端口号由于已经被占用,因此会自动递增,即得到7078的端口号,对应新的Master的地址和之前的Master实例,在端口号上是不一样的。
2.Master HA源代码解析
这部分内容是在前面Master源代码解析的基础之上,进一步详细分析与Master HA相关的源代码。
Master除了继承ThreadSafeRpcEndpoint,可以作为RPC通信终端使用外,还继承了LeaderElectable。LeaderElectable是一个特质,代码如下。

LeaderElectable特质包含了两个接口,分别是为领导选中处理接口和废除领导层的处理接口。
在Master中,与HA相关的几个变量代码如下。

这两个变量的设置位于onStart方法中,具体代码如下。

从代码中可以看出,当前的RECOVERY_MODE有4种(包括默认的模式NONE),分别对应ZOOKEEPER、FILESYSTEM和自定义CUSTOM。每种模式下都会构建出一个对应的工厂实例,由该工厂实例负责构建最终使用的持久化引擎和领导选举代理。
对应配置恢复模式的配置属性的代码如下。
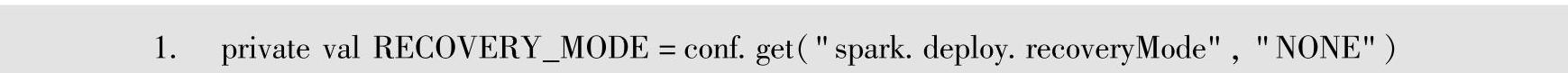
各种模式下都会持久化集群中的各种元数据信息,包含Application、Driver和Worker。下面分别针对这4种模式解析其选举机制和持久化过程。
(1)ZOOKEEPER恢复模式
ZooKeeper提供了一种领导选举的机制,通过该机制,可以保证集群中只有一个Master 处于RecoveryState.Active状态,其他的Master则处于RecoveryState.Standby状态。当处于RecoveryState.Active状态的Master结点出现故障时,ZooKeeper选举机制会保证选举出新的Master结点。
Spark并不直接使用ZooKeeper的API,而是使用在ZooKeeper上进一步封装的Curator,使用的类如下所示。

CuratorFramework提供了high-level的API,极大地简化了ZooKeeper的使用,并且在ZooKeeper上添加了很多特性,包括以下几个。
1)自动连接管理:连接到ZooKeeper的Client可能会连接中断,而Curator会处理这种情况,也就是说,对Client来说自动重连是透明的。
2)简洁的API:简化了原生态的ZooKeeper的方法、事件等,提供了更易于使用的接口。(https://www.xing528.com)
3)Recipe的实现如下。
·Leader的选择。
·共享锁。
·缓存和监控。
·分布式的队列。
·分布式的优先队列。
CuratorFrameworks通过CuratorFrameworkFactory来创建线程安全的ZooKeeper的实例。
在启动ZooKeeper的选举代理类ZooKeeperLeaderElectionAgent时,会执行start方法,在该方法中,通过CuratorFrameworkFactory.newClient方法来创建ZooKeeper的实例,可以传入不同的参数来对实例进行完全控制。获取实例后,必须通过start()来启动这个实例,在结束时,需要调用close()。
对应构建的代码封装在SparkCuratorUtil类中,代码如下。

在领导选举代理中会根据当前选举的情况来调用masterInstance:LeaderElectable的两个接口,具体代码如下。

当被选中为Leader时,masterInstance.electedLeader()接口会向Master发送ElectedLeader消息,然后在receive方法中处理该消息,具体代码如下。

其中,持久化引擎对应为ZooKeeperPersistenceEngine类,在该类中实现了将集群的元数据信息持久化/反持久化到ZooKeeper的指定路径下。
(2)FILESYSTEM恢复模式
在这种模式下,选举机制比较简单,Master启动即认为被选举为领导。对应的持久化引擎只是将持久化/反持久化的位置改成了本地文件系统,也就是将集群中的这些元数据信息保存到本地文件系统,恢复时也从本地文件系统读取。
(3)CUSTOM恢复模式
这是提供用户自定义恢复Master元数据信息的一种模式。通过前面的分析可知,当使用自定义恢复模式时,需要提供一个工厂类,相应的,该工厂类中必须提供构建持久化引擎和领导选举代理的两个接口。由前面的代码可知,自定义的工厂类名在"spark.deploy.recoveryMode.factory"配置属性中设置。
(4)NONE恢复模式
这是默认的恢复模式,这种模式下不会持久化集群的元数据信息,Master启动后即认为被选举为领导。
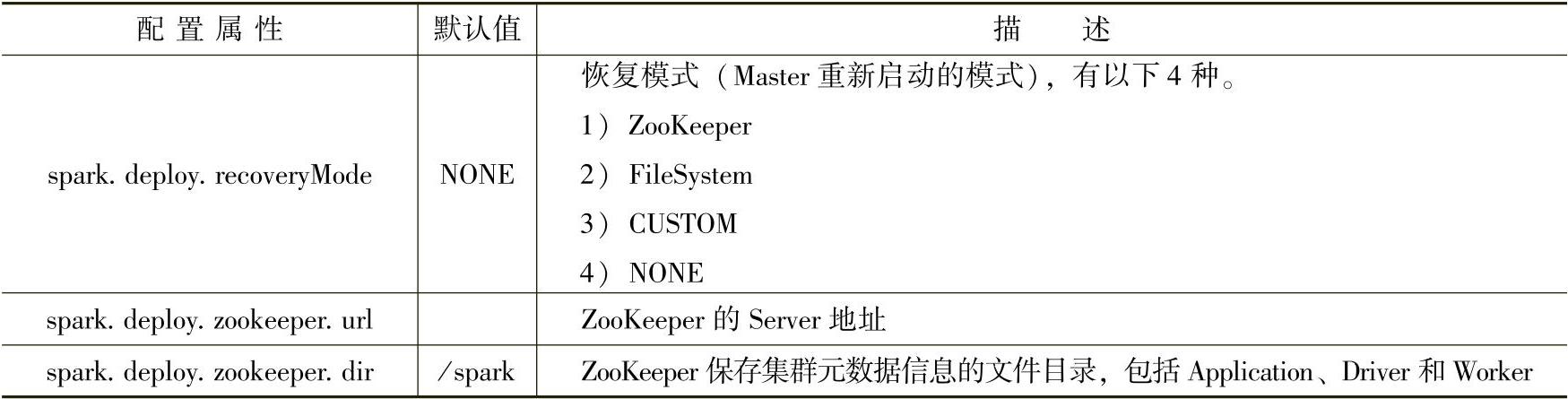
分析完4种恢复模式之后,最后给出与Master HA相关的一些配置属性,如表3-23所示。
表3-23 与Master HA相关的一些配置属性
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。