



Spark中的各个组件是通过脚本来启动部署的,下面以脚本为切入点开始分析Master的部署。
每个组件对应提供了启动的脚本,同时也会提供停止的脚本。停止脚本比较简单,可以自己查看,在此仅分析启动脚本。
1.Master部署的启动脚本解析
首先来看下Master的启动脚本./sbin/start-master.sh,内容如下。



通过脚本的简单分析,可以看出Master组件是以后台守护进程的方式启动的,对应后台守护进程的启动脚本spark-daemon.sh,在后台守护进程的启动脚本spark-daemon.sh内部,通过脚本spark-class来启动一个指定主类的JVM进程,相关的代码如下。


通过脚本的分析,可以知道最终执行的是Master类(对应的代码为前面的CLASS="org.apache.spark.deploy.master.Master"),对应的入口点则是Master伴生对象中的main方法。下面以该方法作为入口点进一步解析Master部署框架。
在部署Master组件时,最简单的方式是直接启动脚本,不带任何选项参数,命令如下。

如需设置选项参数,可以查看帮助信息,根据自己的需要进行设置。
2.Master的源代码解析
首先查看Master伴生对象中的main方法,代码如下。

和其他类,如SparkSubmit一样,Master类的入口点处也包含了对应的参数类MasterAr-guments。这里简单介绍一下该类,包括Spark属性配置相关的一些解析,对应在其他地方的属性配置部分类似。
下面首先来看一下MasterArguments类的主要代码,如下所示。


另外,MasterArguments中的printUsageAndExit方法,对应的就是命令行中的帮助信息。
在解析完Master的参数之后,调用startRpcEnvAndEndpoin方法启动RPC通信环境及Master的RPC通信终端。该方法的代码如下。


由第19和第20行代码可以看到,代码中创建了一个Master实例。首先来看一下Mater的定义。

从第7行代码可以看到,Master继承了ThreadSafeRpcEndpoint和LeaderElectable,其中继承LeaderElectable涉及Master的HA(High Availability,高可用性)机制,这里先关注ThreadSafeRpcEndpoint,继承该类后,Master作为一个RpcEndpoint,实例化后首先会调用onStart方法,方法的代码如下所示。


在启动Master组件后,会读取Master相关的一些配置信息,这些信息可以直接在Master源代码中查看。需要注意的是,由于这些配置信息是在Master中使用的,因此需要在启动Master组件之前进行配置,保证Master实例可以读取正确的配置属性;如果在启动之后修改了这些配置属性,则需要重新启动Master组件(对应其他组件的相关配置的修改与此类似)。
Master组件与YARN或Mesos类似,其主要功能是资源管理与调度,因此会维护一组提供资源的Worker信息和需要调度的应用程序信息,在Master组件中会根据一定的调度策略为这些应用程序分配资源注册上来的Worker中的资源(当前包含CPU与内存)。
下面是维护这些信息的变量定义,为了方便分析,下面会做些简单的顺序调整,代码如下。

继承ThreadSafeRpcEndpoint类之后,作为RPC的一个通信终端,Master会响应各种消息并处理,在此过程中会更新Master中维护的信息,另外,响应资源请求时进行资源调度的过程中也会更新这些信息。这里先来分析Master对资源的调度过程。调度过程在schedule方法中,具体代码如下。(https://www.xing528.com)


在为等待中的Driver分配好资源之后,开始为用户提交的应用程序调度和分配资源,具体的代码在startExecutorsOnWorkers方法中,代码如下。


从代码可知,startExecutorsOnWorkers方法包含下列3个步骤。
1)提取满足资源条件的Worker队列。
2)指定在每个可用Worker上分配的内核数。
3)根据在每个可用Worker上分配到的内核数,在各个Worker上调度和启动Executors。
指定在每个可用Worker上分配的内核数在scheduleExecutorsOnWorkers方法中实现,具体代码如下。




根据在每个可用Worker上分配到的内核数,在各个Worker调度和启动Executors,代码如下。


为了更形象地描述Master的调度机制,下面通过图3-6来介绍抽象的资源调度框架。
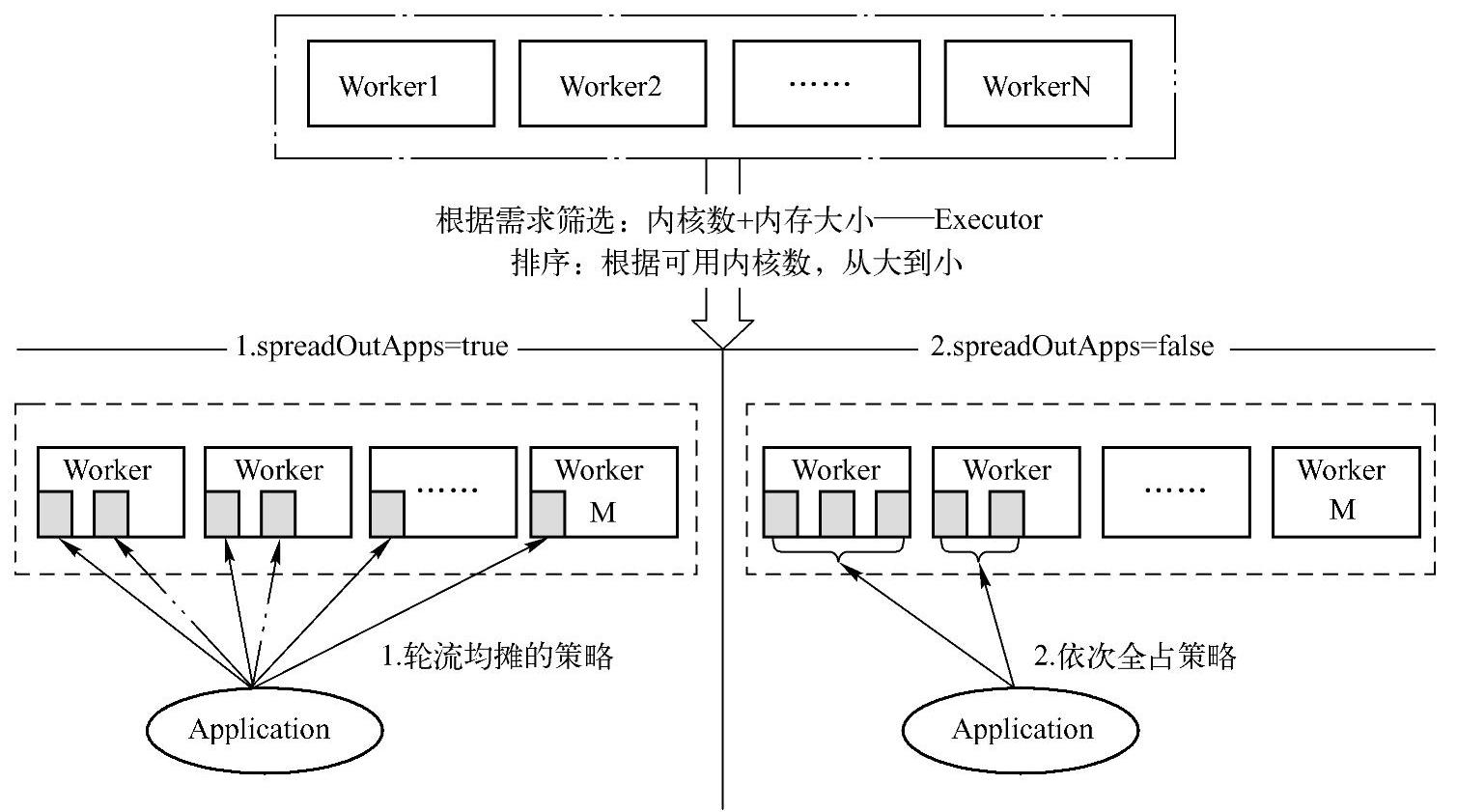
图3-6 Master中抽象的资源调度框架
其中,Worker1到WorkerN是集群中全部的Workers结点,调度时会根据应用程序请求的资源信息,从全部Workers结点中过滤出资源足够的结点,假设可以得到Worker1到WorkerM的结点。当前过滤的需求是内核数和内存大小足够启动一个Executor,这是因为Executor是集群执行应用程序的单位组件(注意:Executor和任务(Task)不是同一个概念,对应的任务是在Executor中执行的。)
选出可用Worker后,会根据内核大小进行排序,这可以理解成是一种基于可用内核排序的、简单的负载均衡策略。然后根据设置的spreadOutApps参数,对应指定两种资源分配策略。
1)当spreadOutApps=true:使用轮流均摊的策略,也就是采用圆桌(Round-Robin)算法,图3-6中的虚线表示第一次轮流摊派的资源不足以满足申请的需求,因此开始第二轮摊派,依次轮流均摊直到符合资源需求。
2)当spreadOutApps=false:使用依次全占策略,依次从可用Workers上获取该Worker上可用的全部资源,直到符合资源需求。
对应的图3-6中Worker内部的小方块,在此表示分配的资源的抽象单位,对应资源的条件,理解的关键点在于资源是分配给Executor的,因此最终启动Executor时,所占用的资源必须满足启动所需的条件。
前面描述了Workers上的资源如何分配给应用程序,之后就是正式开始为Executor分配资源、并向Worker发送启动Executor的命令了。根据申请时是否明确指定需要为每个Exec-utor分配确定的内核个数,有下列两种情况。
1)明确指定每个Executor需要分配的内核个数时:每次分配的是一个Executor所需的内核数和内存数,对应在某个Worker分配到的总的内核数可能是Executor的内核数的倍数,此时,该Worker结点上会启动多个Executor,每个Executor需要指定的内核数和内存数(注意该Worker结点上分配到的总的内存大小)。
2)未明确指定每个Executor需要分配的内核个数时:每次分配1个内核,最后所有在某Worker结点上分配到的内核都会放到一个Executor内(未明确指定内核个数,因此可以一起放入一个Executor)。因此,最终该应用程序在一个Worker上只有一个Executor(这里指的是针对一个应用程序,当该Worker结点上存在多个应用程序时,仍然会为每个应用程序分别启动相应的Executor。)。
在此强调并补充一下调度机制中使用的两个重要的配置属性。
1)内核个数的控制属性在类SparkSubmitArguments的方法printUsageAndExit中,如下所示。

2)资源分配策略:数据本地性(数据密集)与计算密集的控制属性,对应的配置属性在Master类中,代码如下。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。