



本节主要通过一个简单计数案例,从中讲解DAG具体生成的流程和关系。示例代码如下。

在程序正式运行前,Spark的DAG调度器会将整个流程设定为一个Stage,此Stage包含3个操作和4个RDD,分别为MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flat-Map操作)、MapPartitionRDD(map操作)、MapPartitionRDD(reduceByKey的local段的操作)和ShuffleRDD(reduceByKeyshuffle操作)。
1)回溯整个流程,在shuffleRDD与MapPartitionRDD(reduceByKey的local段的操作)中存在Shuffle操作,整个RDD先在此切开,形成两个Stage。
2)继续向前回溯,MapPartitionRDD(reduceByKey的local段的操作)与MapParti-tionRDD(map操作)中间不存在Shuffle操作(即两个RDD的依赖关系为窄依赖),归为同一个Stage。
3)继续回溯,发现之前的所有RDD之间都不存在Shuffle,应归为同一个stage。
4)回溯完成,形成DAG,由两个Stage构成。(https://www.xing528.com)
·第一个Stage由MapPartitionRDD(读取文件数据时)、MapPartitionRDD(flatMap操作)、MapPartitionRDD(map操作)和MapPartitionRDD(reduceByKey的local段的操作构成,如图2-4所示。
·第二个Stage由ShuffleRDD(reduceByKey shuffle操作)构成,如图2-5所示。
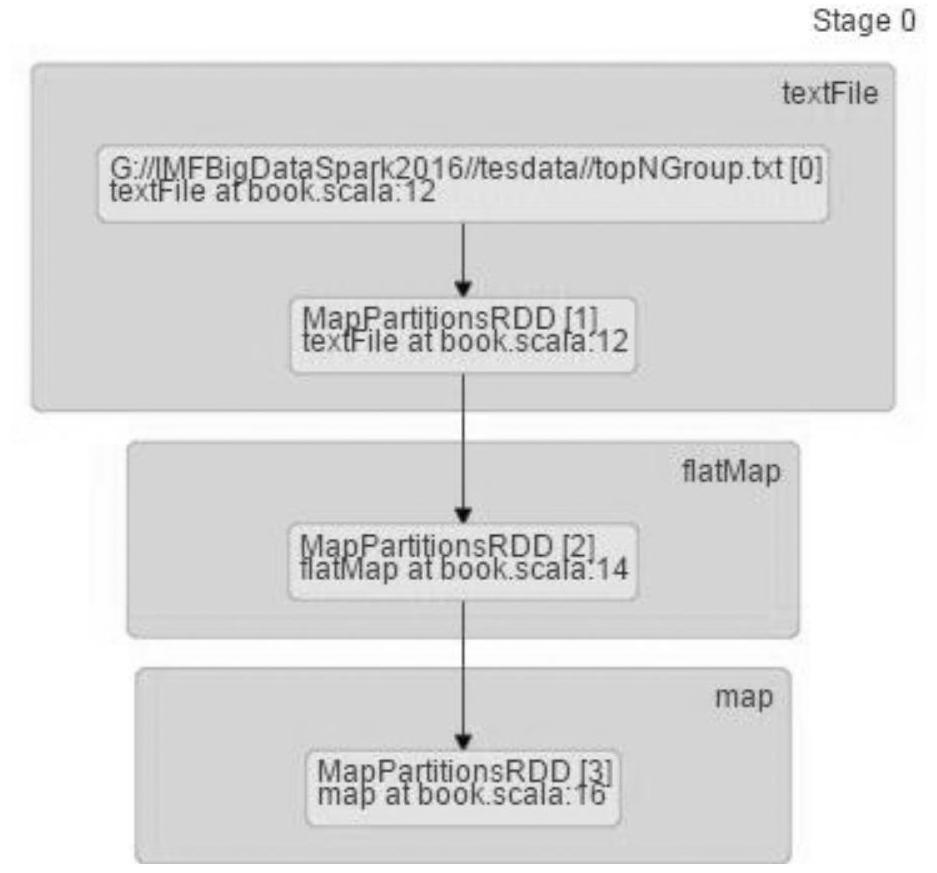
图2-4 Stage0的构成
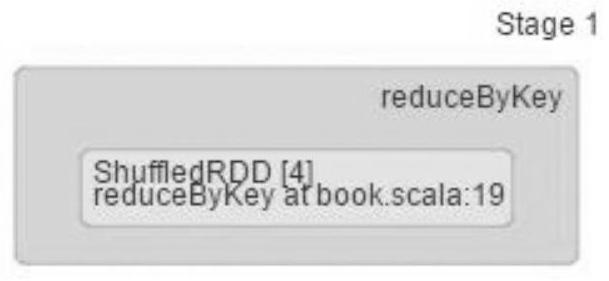
图2-5 Stage1的构成
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。