



【摘要】:RDD的宽依赖是一种会导致计算时产生Shuffle操作的RDD操作,用来表示一个父RDD的Partition都会被多个子RDD的Partition所使用,如图2-2中的groupByKey所示,父RDD有3个Partition,每个Partition中的数据会被子RDD中的两个Partition使用。图2-2 宽依赖关系图有关宽依赖的源代码位于Dependency.scala文件的Shuffle Dependency方法,第3行产生了新的ShuffleId,表明了宽依赖过程需要涉及Shuffle操作;途中后续的代码表示宽依赖进行时的Shuffle操作需要向shuffleManager注册信息。
RDD的宽依赖是一种会导致计算时产生Shuffle操作的RDD操作,用来表示一个父RDD的Partition都会被多个子RDD的Partition所使用,如图2-2中的groupByKey所示,父RDD有3个Partition,每个Partition中的数据会被子RDD中的两个Partition使用。
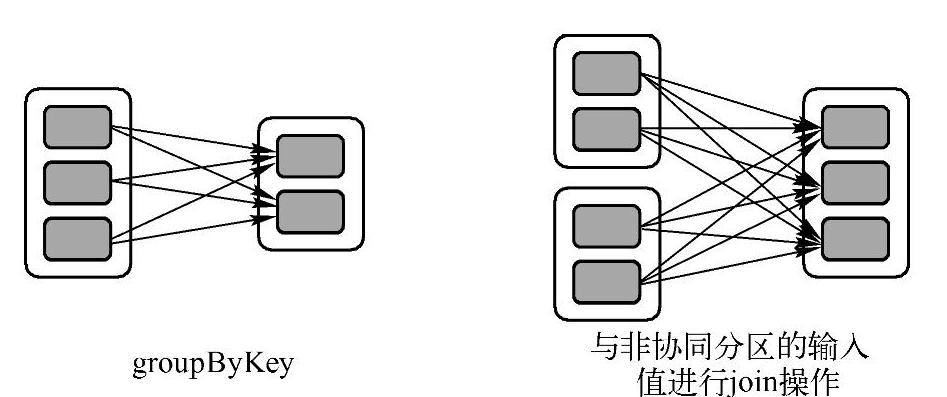
图2-2 宽依赖关系图
有关宽依赖的源代码位于Dependency.scala文件的Shuffle Dependency方法,第3行产生了新的ShuffleId,表明了宽依赖过程需要涉及Shuffle操作;途中后续的代码表示宽依赖进行时的Shuffle操作需要向shuffleManager注册信息。

Spark中,宽依赖关系很常见,其中较为经典的操作为GroupByKey(将输入的key-value 类型的数据进行分组,对于相同Key的value值进行合并,生成一个Tuple2数组,如图2-3所示),具体代码和操作结果如下所示,这里输入5个Tuple2类型的数据,通过运行产生3个Tuple2数据。(https://www.xing528.com)

操作结果如图2-3所示。

图2-3 GroupByKey结果
本节内容主要讲解关于RDD依赖关系的基本定义,并从源代码层面讲解依赖关系的真正实现方式,但是由于整个Spark计算都是基于RDD的计算,对于RDD之间的依赖关系的深刻理解是很重要的一部分,希望读者可以仔细阅读Dependency.scala类下的源代码,并且多做几个具体的案例(推荐在Spark-Shell中进行),以加深对依赖关系的理解。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。