



RDD(Resilient Distributed Datasets,弹性分布式数据集)是分布式内存的一个抽象概念,是一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,能横跨集群的所有结点进行并行计算,是一种基于工作集的应用抽象。
RDD底层存储原理为:其数据分布存储于多台机器上,事实上,每个RDD的数据都以Block的形式存储在多台机器上。图1-2所示是Spark的RDD存储架构图,其中每个Executor会启动一个BlockManagerSlave,并管理一部分Block;而Block的元数据由Driver结点上的BlockManagerMaster保存,BlockManagerSlave生成Block后向BlockManagerMaster注册该Block,BlockManagerMaster管理RDD与Block的关系,当RDD不再需要存储时,将向BlockManagerSlave发送指令删除相应的Block。
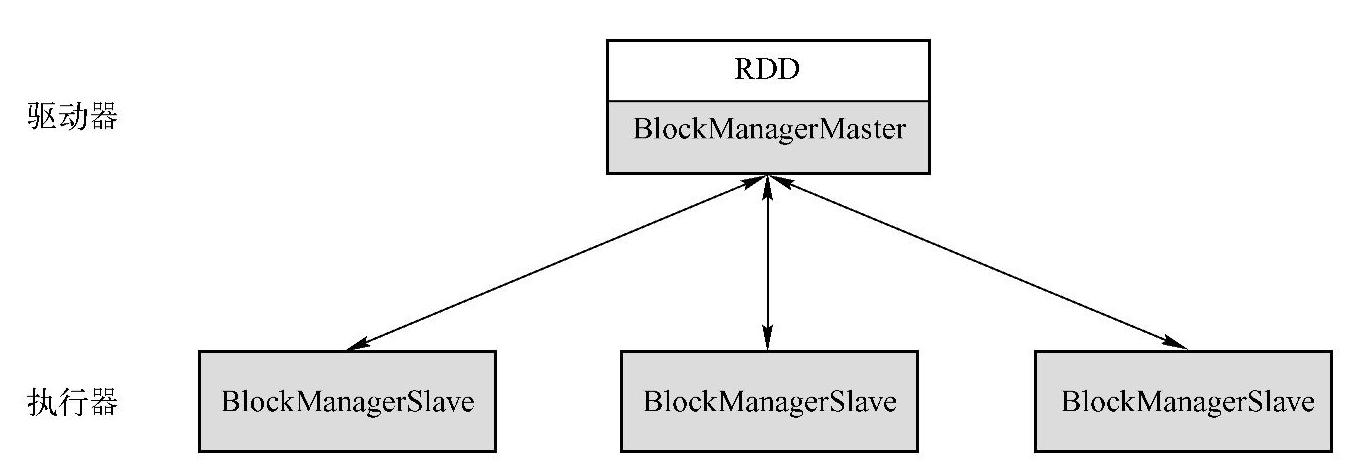
图1-2 RDD存储架构图
BlockManager管理RDD的物理分区,每个Block就是结点上对应的一个数据块,可以存储在内存或者磁盘上。而RDD中的Partition是一个逻辑数据块,对应相应的物理块Block。本质上,一个RDD在代码中相当于是数据的一个元数据结构,存储着数据分区及其逻辑结构的映射关系,存储着RDD之前的依赖转换关系。
在此需要对BlockManager进行简要的解释,BlockManager的部分源代码如下。
 (https://www.xing528.com)
(https://www.xing528.com)
BlockManagerMaster会持有整个Application的Block的位置、Block所占用的存储空间等元数据信息,在Spark的Driver的DAGScheduler中就是通过这些信息来确认数据运行的本地性的。Spark支持重分区,数据通过Spark默认的或者用户自定义的分区器来决定数据块分布在哪些结点。RDD的物理分区是由Block-Manager管理的,每个Block就是结点上对应的一个数据块,可以存储在内存或者磁盘中。而RDD中的Partition是一个逻辑数据块,对应相应的物理块Block。本质上,一个RDD在代码中相当于是数据的一个元数据结构(一个RDD就是一组分区),存储着数据分区及Block、Node等的映射关系以及其他元数据信息,存储着RDD之前的依赖转换关系。分区是一个逻辑概念,Transformation前后的新旧分区在物理上可能是同一块内存存储。
Spark通过读取外部数据创建RDD,或通过其他RDD执行确定的转换Transformation操作(如map、union和groubByKey)而创建,从而构成了线性依赖关系或者说血统关系(lin-eage),在数据分片丢失时可以从依赖关系中恢复自己独立的数据分片,对其他数据分片或计算机没有影响,基本没有检查点开销,使得实现容错的开销很低,失效时只需要重新计算那些RDD分区,就可以在不同结点上并行执行,而不需要回滚(Roll Back)整个程序。关于落后任务(即运行很慢的结点)是通过任务备份,重新调用执行进行处理的。
因为RDD本身支持基于工作集的运用,所以可以使Spark的RDD持久化(Persist)到内存中,在并行计算中高效重用。在进行多个查询时,就可以显性地将工作集中的数据缓存到内存中,为后续查询提供复用,这极大地提升了查询的速度。在Spark中,一个RDD就是一个分布式对象集合,每个RDD可分为多个片(Partitions),而分片可以在集群环境的不同结点上计算。
RDD作为泛型的抽象的数据结构(如下面源代码的第8行代码),支持两种计算操作算子:Transformation(变换)与Action(行动)。并且RDD的写操作是粗粒度的,读操作既可以是粗粒度的也可以是细粒度的。

在此需要对SparkContext做出解释:SparkContext是Spark功能的主要入口点,一个SparkContext代表一个集群连接,可以用其在集群中创建RDD、累加变量和广播变量等,在每一个可用的JVM中只有一个SparkContext,在创建一个新的SparkContext之前必须先停止该JVM中可用的SparkContext,这种限制可能最终会被修改。SparkContext被实例化时需要一个SparkConf对象去描述应用的配置信息,在这个配置对象中设置的信息会覆盖系统默认的配置。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。