



Hadoop的MapReduce是一种基于数据集的工作模式,这种模式的工作方式是:从物理存储上加载数据,然后操作数据,最后写入物理存储设备。
基于数据集操作的系统对两种应用的处理并不高效:一是迭代式的算法,这在图应用和机器学习领域很常见,二是交互式数据挖掘工具(反复查询一个数据子集)。这两种情况下,将数据保存在内存中能够极大地提高性能。基于数据集的方式不能够复用曾经的计算结果或中间计算结果,Hadoop每次作业都从磁盘上读写数据,而且第二次作业运行时会再次从磁盘上读写数据,不能基于内存共享数据,这种数据集系统对通用的应用的操作处理并不高效,因为通用的处理一般都是用迭代的(如机器学习和图计算),另外假设要对处理的结果进行复用的话,例如,想要复用图1-1中Job#1的结果,这时候必须在磁盘上重读,不能基于内存复用,只能再次执行Job#1,不会从内存中复用上次的结果。基于数据
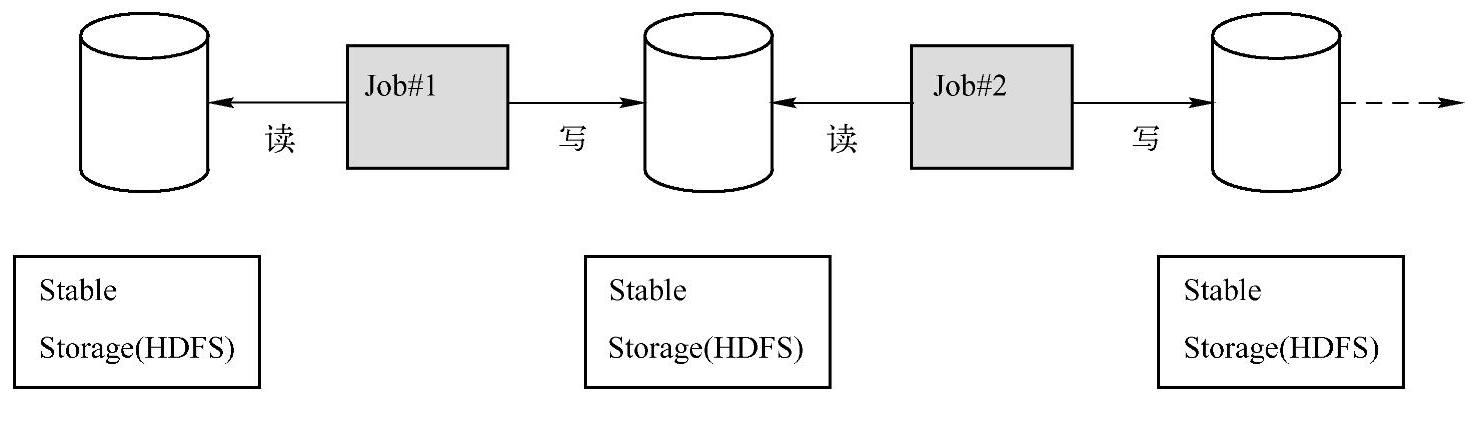
图1-1 工作模型图
集的系统对交互式数据挖掘工具也不太适用。如果能将数据保存到内存中,其性能将会得到大大提升。(https://www.xing528.com)
数据集的特性有位置感知、容错性和负载均衡等。在众多特性中,最难实现的是容错性。一般来说,分布式数据集的容错性有两种方式:数据检查点和记录数据更新。当面向大规模数据分析时,数据检查点操作成本很高:需要通过数据中心的网络链接在各台机器之间复制庞大的数据集,而网络带宽往往比内存带宽低得多,同时还需要消耗更多的存储资源(在内存中复制可以减少需要缓存的数据量,而存储到磁盘则会拖慢应用程序)。
这里所讲的RDD就是在这种背景下所产生的。Spark的RDD是一种基于工作集的工作模式。无论数据集还是工作集,它们都有一些共同的特征,如位置感知、容错和负载均衡等,为了有效地实现容错,RDD本身提供了一种高度受限的共享内存模型,它是只读的记录分区的集合,只能够通过从外界读取文件,或者说由其他的RDD来产生。RDD的读操作可以精确到一条记录,RDD的写操作则是批量的。RDD的模型特别适合迭代,因为后面的RDD都是依据前面的RDD产生的,或者从外部读取数据而产生的,这就有一种前后的依赖关系,创建RDD的一系列转换被记录下来(即Lineage机制),以便恢复失去的数据。
Spark的RDD为基于工作集的应用提供了更为通用的抽象,用户可以对中间结果进行显式的命名和物化,控制其分区,还能执行用户选择的特定操作(而不是在运行时去循环执行一系列MapReduce步骤),Spark为工作集的应用提供了基本的抽象,同时又具有以Ha-doop为代表的数据流模型的优势(如自动位置的感知、自动容错、伸缩性和良好的调度等),Spark的RDD之间具有依赖关系且高度抽象,编程模型更容易,容错更好。一些算法,如逻辑回归、k幂次数列等,都会在多个作业中重用或共用计算结果,在多个共享数据集中交互式查询。RDD本身采用分布式内存计算的抽象容错机制解决了多步骤迭代,在一个共享数据集中执行多个交互式查询(多个Job中重用计算数据),这是RDD的使用场景。RDD不太适合那些异步更新共享状态的应用,如并行Web爬虫。RDD的目标是为大多数分析型应用提供有效的编程模型。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。