



H2O遵循多层前馈神经网络模型来进行预测性建模。本节详细地描述H2O的深度学习特征、参数配置,以及计算机实现。
(1)特征概要
H2O的深度学习功能包括:
1)用于回归与分类任务的纯监督训练协议。
2)快速以及高效利用存储的JAVA实现,这种实现基于柱状压缩以及精细地图/微量递减。
3)在单结点或者一簇多重结点上进行多线程的分布式并行计算。
4)全自动的单神经元自适应学习速率,以求快速收敛。
5)可选的学习速率规格、退火以及动量选项。
6)正则化选项包括L1、L2、dropout,Hogwild以及平均化模型,这些选项用来防止过拟合。
……
(2)训练
1)初始化。多种深度学习架构结合了非监督预训练与监督训练,但是H2O使用单纯的监督训练协议。默认初始化方案是清一色的自适应选项,这些选项是基于网络规模进行了优化的。另一方面,可以选择服从均匀分布或者正态分布的随机初始化,对此,要说明换算因数。
2)激活函数与损失函数。可选的激活函数总结于表11.1。表中,xi与wi分别代表神经元的输入值和权重值;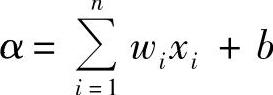 。
。
表11.1 激活函数

可选的损失函数列于表11.2。
表11.2 损失函数
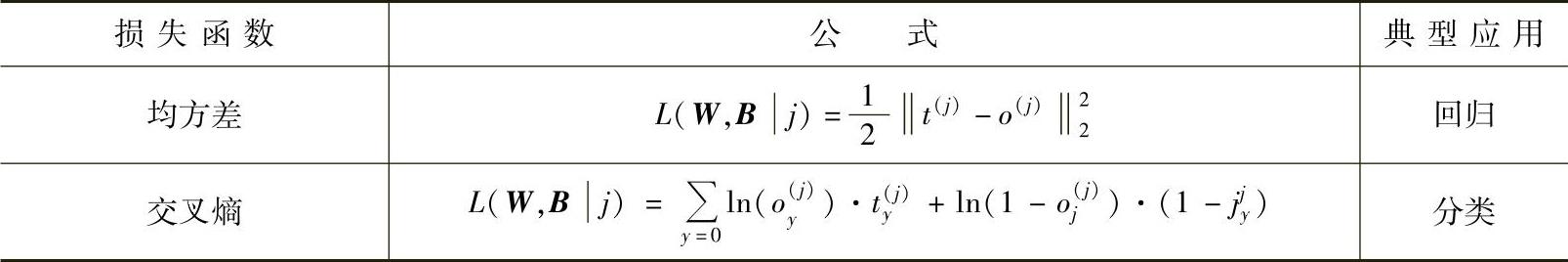
3)精调。使损失函数值最小化的过程类似于随机梯度下降(Stochastic Gradient Descent,SGD)。微调过程如下:
初始化:W,B。
迭代:
获取第i个训练样本;
修改wik和bki
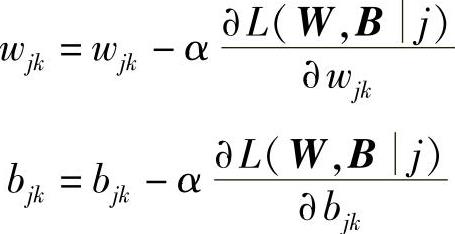
直到满足收敛条件。
其中,α表示学习速率,它控制着梯度下降中的步长。
4)训练算法。在H2O中使用SGD进行分布式多线程训练,以下是一个算法概要:
步骤1.初始化全局模型参数W、B。
步骤2.跨结点分布训练数据T(结点可以不交,也可以重复)。(https://www.xing528.com)
步骤3.迭代。
对训练子集Tn上的n个节点进行并行计算:
1)获取全局参数Wn、Bn的副本。
2)选择子集Tna⊂Tn。
3)通过核nc把Tna划分为Tnac。
4)对节点n的核nc,并行计算:
4.1)获取第i个训练样本,i∈Tnac。
4.2)修改所有权重wik∈wn,偏移量bik∈Bn。
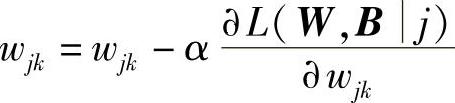
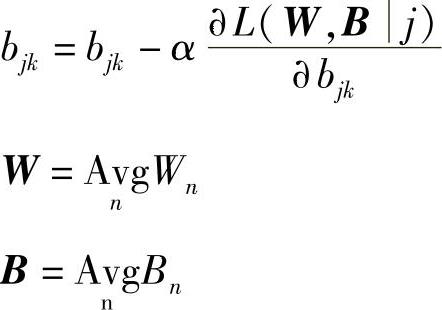
直到满足收敛条件。
步骤4.根据验证集分数优化模型。
5)指定每步迭代的样本数。H2O深度学习是可扩展的并且能够利用一大簇计算结点。一共有三种运行模式。默认行为是,让每个结点在整个数据集上训练,但是自动为每步迭代分配训练数据。
(3)正则化
H2O的深度学习框架支持正则化技巧来防止过拟合。L1与L2正则化方法都修改了损失函数为
L′(W,B|j)=L(W,B|j)+λ1R1(W,B|j)+λ2R2(W,B|j)
还有一种正则化方法称为dropout。
(4)优化
H2O在优化阶段,有手动模式与自动模式。手动模式特性包括动量训练和学习速率退火,而自动模式自适应调整学习速率。
动量训练:动量训练修改了反向传播,它允许前步迭代影响目前的更新。专门定义一个向量V来对更新进行修改如下:
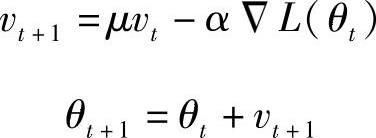
其中,θ代表W、B参数;μ代表动量系数;α代表学习速率。
(5)数据下载
当用R下载在使用H2O时需要的数据,这和通常的方法稍有些不同,即必须将数据集转化为H2OParsedData对象。例如,在Http://bit.ly/1yywZzi.下载天气数据,首先下载数据到R调试环境的当前工作目录,接着运行如下命令:
weather.hex=h20.uploadFile(h20_server.path="weather.csv",header=true.
sep=".",key="weather.hex")
快速概览数据,运行如下命令:
summary(weather.hex)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。