



(1)Dropout能增加成功概率
随机忽略一部分隐藏层神经元的过程称为Dropout(见图2.9)。更为正式的陈述是:对于每个隐藏层的神经元,以概率p随机地从网络中省略。由于神经元是随机选择的,因此将为每个训练实例选择不同的神经元组合。
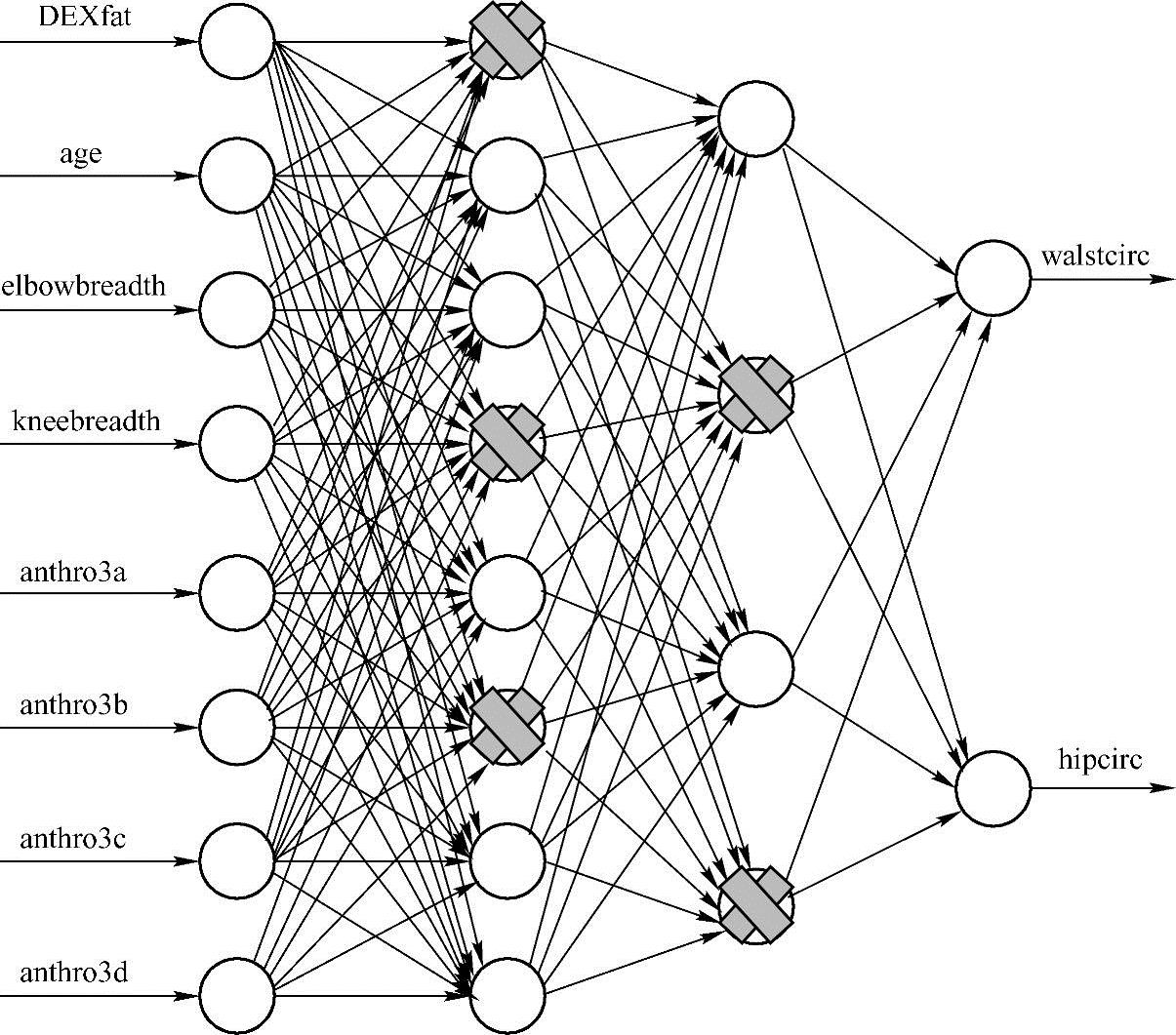
图2.9 DNN Dropout策略
这个想法非常简单,并在每层建立弱学习模型。弱学习模型本身具有低预测能力,然而许多弱模型的预测可以被加权并组合以产生具有更强预测能力的模型。
事实上,Dropout非常类似于Bagging的机器学习技术背后的想法。Bagging是一种模型平均方法,其中多数表决是从训练数据的Bootstred样本上训练的分类器中取得的。事实上,可以将Dropout视为多个神经网络模型的隐式Bagging。因此,Drop-out可以被认为是在大量不同神经网络上执行模型平均有效的方式。
DNN的能力主要来自于每个神经元,这些神经元在DNN中作为独立的特征检测器。然而,在应用中,要解决的另一个问题是共线性问题,即两个或多个变量高度相关。这意味着变量包含类似的信息;特别地,其中一个变量可以从其他具有非常小误差的变量线性地预测。实质上,一个或多个变量在统计上是冗余的。共线性问题可以通过从模型中Dropout一个或多个变量来解决。
通过在训练的前馈阶段Dropout神经元的激活来阻止隐藏层神经元的共线性。Dropout也可以应用于输入层,在这种情况下,算法将随机忽略某些输入。
经验告诉我们,Dropout并不一定会影响未来的表现,但也不能绝对地保证能提高性能,值得一试。在开发DNN模型时,需记住以下三点:
1)通过创建多个路径以在整个DNN中实现校正分类。
2)Dropout越多,训练期间引入的噪声越多;这降低了学习速度。
3)在非常大的DNN模型上,Dropout似乎能展现最大的好处。
(2)从反向传播算法中受益(https://www.xing528.com)
正向传播计算DNN的所有层的每个结点的权重。反向传播是计算所有训练样本的误差,并且调整权重。
分块反向传播是加速神经网络计算的一种常用方法。它涉及同时计算多个训练样本上的梯度,而不是在原始随机梯度下降算法中发生的针对单独样本的计算。
注意,块尺度越大,运行模型所需的内存越多。为了了解分块反向传播计算效率,假设有一大小为500的数据,同时有1000个训练样本。它只需要2次迭代来完成1个结点的计算。
一个常见的问题是,什么时候应该使用分块技术?答案取决于建立的DNN规模。模型中的神经元越多,分块反向传播的潜在益处越大。
另一个常见的问题是块的最佳规模。在选择最佳块尺寸方面需要一定的经验。经验告诉我们,最好的建议是尝试不同的值,以了解哪些对样本和DNN架构有效。
(3)早期停止的简单计划
如果能更容易提取测试样本可接受的性能,则应该提早停止DNN训练。这是早期停止的概念,其中样本被分成三组:训练集、验证集和测试集。
训练集用于训练DNN,训练误差通常是单调函数,每次迭代都会减小,图2.10说明了这种情况,在前100次迭代期间,误差迅速下降,然后在接下来的300次迭代中下降速率更慢,随后变为恒定值。
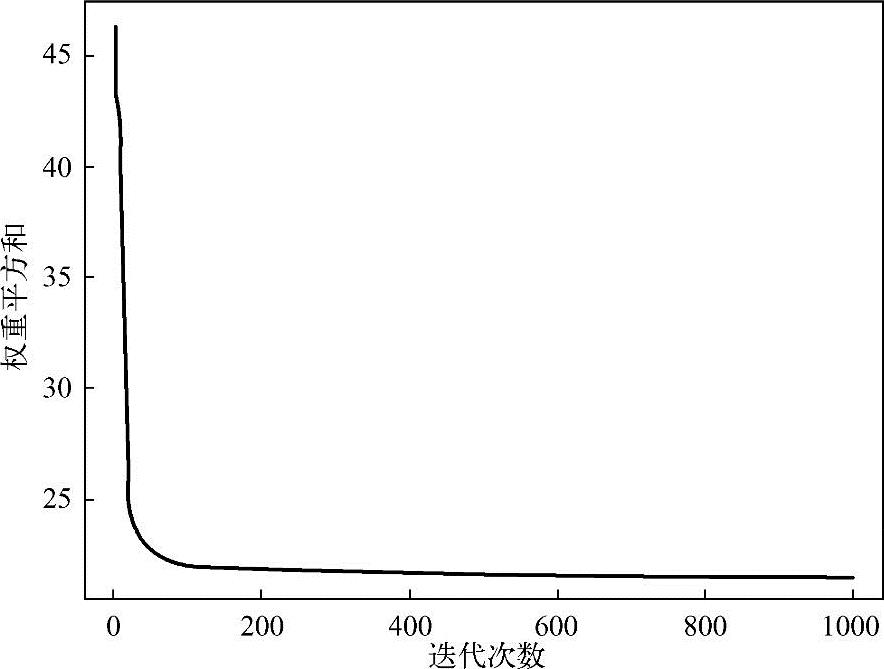
图2.10 网络的迭代误差
验证集用于评估模型的性能。验证误差通常在早期阶段急剧下降,同时网络快速学习出函数形式,但随后误差增加,这表明模型开始过拟合。
当验证集上误差最低时停止训练,然后在测试样本上使用验证模型,对于减少过拟合是非常有效的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。