



信息融合是对来自单个或多个不同平台传感器的信息进行综合,以获得更精确的目标信息的数据处理过程。融合处理的对象不局限于接收到的初级数据,还包括对多源数据进行不同层次抽象处理后的信息。处理过程可利用各种数学工具进行。在多传感器信息融合中,各个传感器提供的信息都具有一定的不确定性和不准确性,因此对这些信息的融合过程是一个不确定性信息的推理与决策过程,信息融合的一个显著特点就是决策与推理。信息融合有三层含义:①信息的全空间性:即信息包括确定的和模糊的、全空间的和子空间的、同步的和异步的、数字的和非数字的,它是复杂的多维多源的、覆盖全频段;②信息融合不同于组合:组合指的是外部特性,融合指的是内部特性,它是系统动态过程中的一种信息综合加工处理过程;③信息的互补性:信息表达方式的互补、结构上的互补、功能上的互补、不同层次的互补,它是融合算法的核心,只有互补信息的融合才能使信息处理结果发生质的飞跃。
1.信息融合的体系结构[2]
(1)集中式信息融合结构(Centralized Fusion)集中式信息融合结构是将多个传感器的信息经过简单调理后直接送入数据融合中心,如图4-4所示。在这种体系结构中,数据融合中心先将传感器信息进行分类,最先处理具有矛盾或相似特性的信息。理论上讲,这是最有效的一种数据融合方法,但是这种结构会造成数据融合中心同时处理大量数据,无法在实时性要求很高的传感器网络系统中应用。
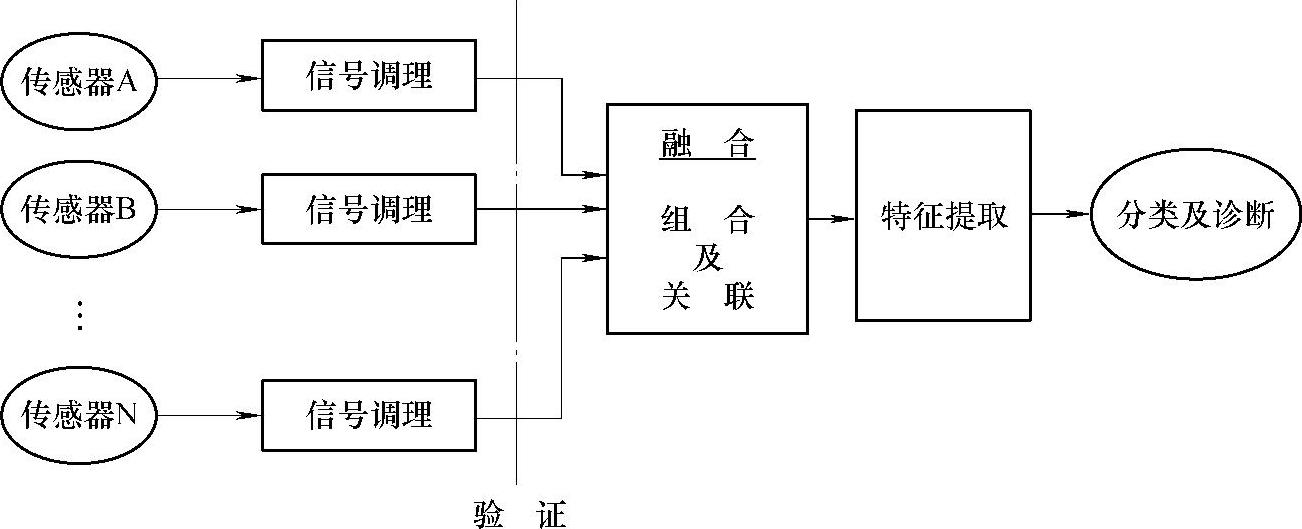
图4-4 集中式信息融合结构
(2)自主式信息融合结构(Autonomous Fusion Architecture)[3]自主式信息融合结构如图4-5所示,将特征提取环节提前至数据融合之前,消除了大部分数据管理问题。将特征提取环节放在实际数据融合环节之前可有效降低待处理数据的维数,与集中式数据融合结构相比,这是一个非常重要的优点。但该体系结构的局限性是,采用单纯的自主式结构时特征融合的结果可能比采用原始信号进行融合的结果精度要低,这是由于在自主式融合结构中,原始传感器信号中相当数量的信息在特征提取环节中被忽视。
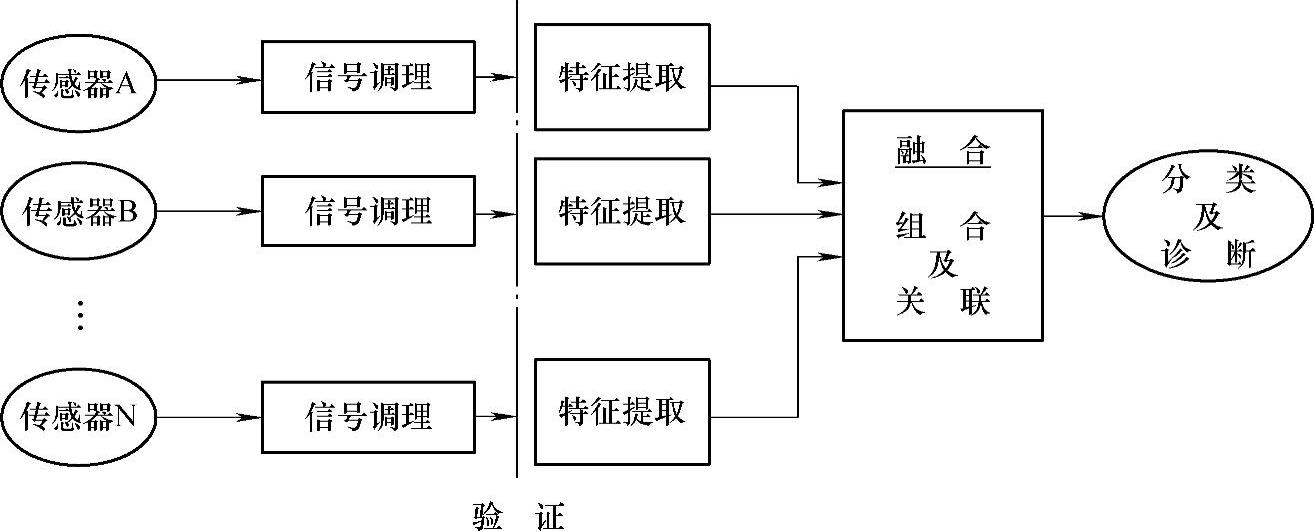
图4-5 自主式信息融合结构
(3)混合式信息融合结构(Hybrid Fusion Architecture)混合式信息融合结构如图4-6所示,更加实用,因为它结合了上述两种结构的优点,可以同时进行原始传感器数据和特征数据的融合,在数据融合中心进行特征数据融合的过程中可以根据需要从原始传感器信号中寻找有用信息,进而有效提高运算结果精度。
(4)混合式分类融合结构(Hybrid Classification Fusion Architecture)混合式分类融合结构如图4-7所示,与上述混合式数据融合结构类似,区别在于分类(Classification)环节的输出或最终的故障诊断算法。在这种结构下,先采用合适的信号调理和特征提取算法对原始传感器信号进行处理,然后采用独立的故障分类算法对故障特征信号进行处理,实现故障隔离(Fault Isolation),再将故障分类隔离的结果通过合适的融合算法进行运算,最终得到最可能发生的故障种类。
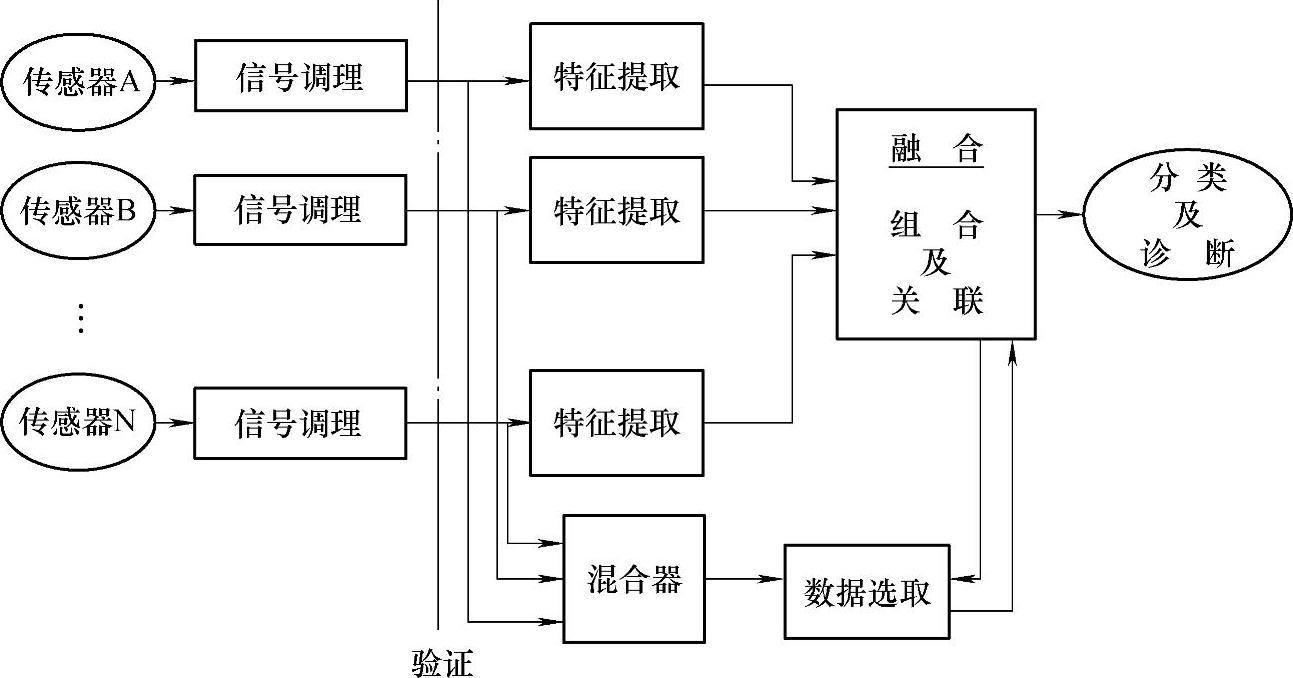
图4-6 混合式信息融合结构
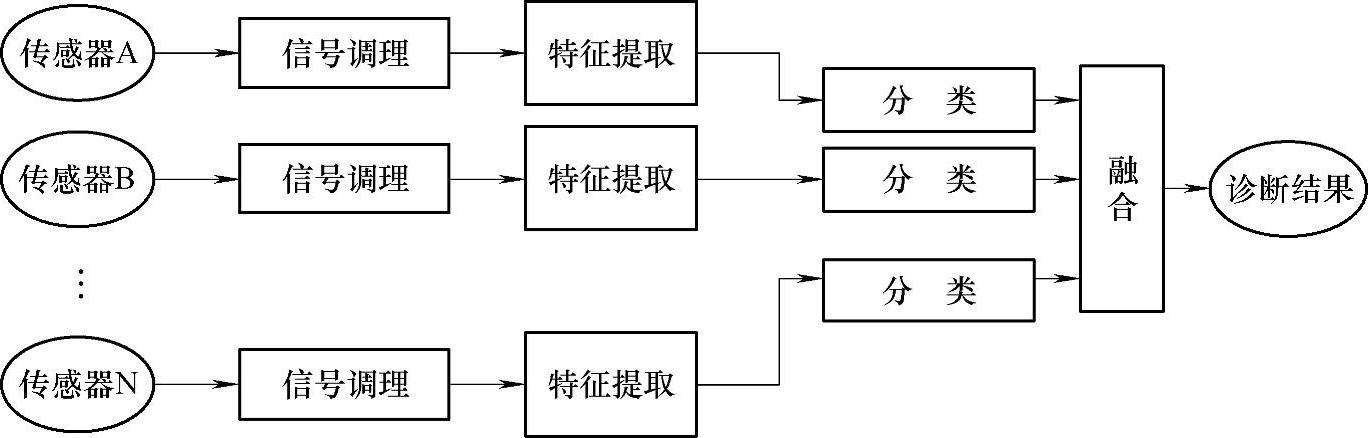
图4-7 混合式分类融合结构
2.信息融合算法
目前存在大量的信息融合、特征融合或知识融合算法,因此对于某一个特定场合的应用而言,如何选取最有效的融合算法是一件不容易的工作,以下介绍常见的融合算法。
(1)贝叶斯推理(Bayesian Inference)贝叶斯推理可给出某一类故障的发生概率,其基本思想是在设定先验概率的条件下,利用贝叶斯规则计算出后验概率,再根据后验概率做出决策,这样就可以处理不确定性问题[4]。贝叶斯方法是一种常见的理论体系完整的融合方法,但它也有实现难点,在于寻找合适的概率分布,特别是当数据来自低档传感器时就显得更为困难。此外,实际中很难知道先验概率,当设定的先验概率与实际情况不符时,推理结果很差。贝叶斯推理的一般表达式为(https://www.xing528.com)
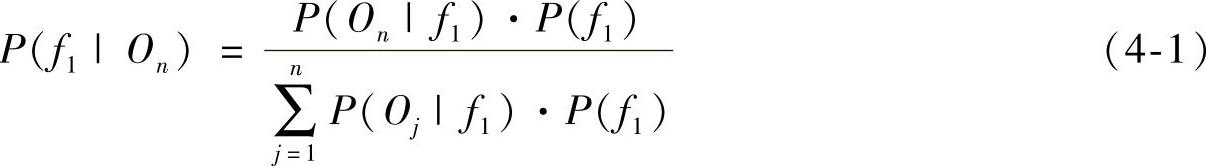
式中,P(f1|On)表示当故障诊断结果为On时,发生故障模式f1的概率;P(On|f1)表示与故障模式f1相关的故障诊断结果On的产生概率;P(f1)表示故障模式f1发生的概率。
贝叶斯推理只能用来分析来自故障诊断分类器的离散数据,即只能得到发生故障或者没有发生故障。因此,一种经过修改的方法被人们具体采用,这种方法使用来自三个不同方面的信息进行推理,即某一故障在t时刻发生的先验概率PFO(t),来自故障分类器的故障发生概率CD(i,t)和与时间无关的故障特征可信度RD(i),如式(4-2)所示:
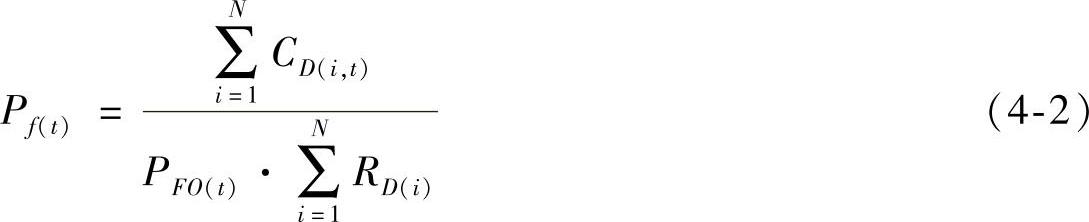
(2)D-S证据方法(Dempster-Shafer Method)D-S方法可以解决上述经典贝叶斯方法中的部分难题,尤其是针对先验概率不易获知这一问题。D-S方法的缺点是在大型融合问题中算法的实时性无法保证,因而限制了实际应用。因此,在解决实际故障诊断与故障预测问题时要根据问题的特点选择最合适的方法[5]。D-S方法考虑了条件概率中的不确定度,它的关键在于识别故障发生概率的计算方法,该方法包括了所有可能的前提,每一个前提条件都有一个可信度(Belief),通过下式中的m表示。式(4-3)表示了D-S方法的计算形式:
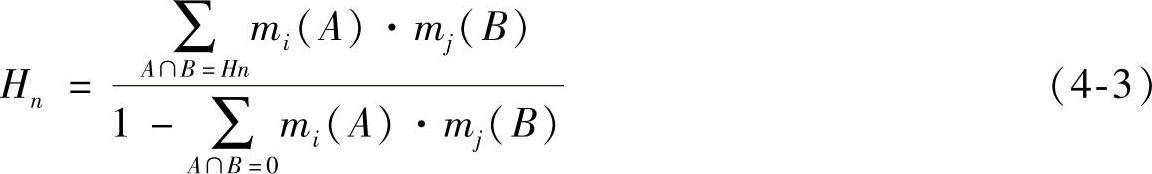
(3)权重/表决融合算法(Weighting/Voting Fusion)贝叶斯推理和D-S方法可以通过精细计算满足实际应用的需求,但是计算量较大,而权重/表决融合算法较为简单。在这种方法中,基于正在使用当中的故障诊断和故障预测算法的精度对权重值进行分配,同时所有权重值之和必须等于1。每一个置信度与其对应的权值相乘,然后再在时间区间求和,权重值也可以是时间的函数[6]。该方法的表示式如下:

式中,i表示故障特征的数量;C表示置信度;W表示每一个故障特征对应的权值。
虽然该方法在实际应用中比较简单,但是设置合适的权值至关重要,这将直接影响到不同条件下故障诊断的精度。
(4)模糊逻辑推理(Fuzzy Logic Inference)模糊逻辑推理基于隶属度函数将系统输入进行融合,产生输出[7]。该方法的基础是基于规则库中的一系列规则对隶属度函数进行度量。在完成了隶属度函数度量之后,通过诸如求和或求最大值等方法将不同隶属度函数融合在一起,最终利用融合后的隶属度函数计算融合输出结果。
(5)神经网络数据融合(Neural Network DataFusion)人工神经网络(Artificial Neural Network,ANN)应用最广泛的领域之一就是数据融合技术领域[8]。神经网络由大量的神经元连接而成,是一种大规模、分布式的神经元处理系统。由于信息融合过程接近人类思维活动,与人脑神经系统有较强的相似性,因此利用神经网络的结构优势和高速的并行运算能力进行多维信息融合处理是一种有效的技术途径。进行融合处理时,需要选取合适的学习规则对人工神经网络进行训练。其输入是由各传感器信源获得的观测值,其输出则是信息融合系统做出的决策。神经网络的层或节点连接可以采用多种形式。对输入向量进行非线性变换,当输入输出关系未知时,可以得到较为理想的结果。神经网络的具体算法见4.2.2。
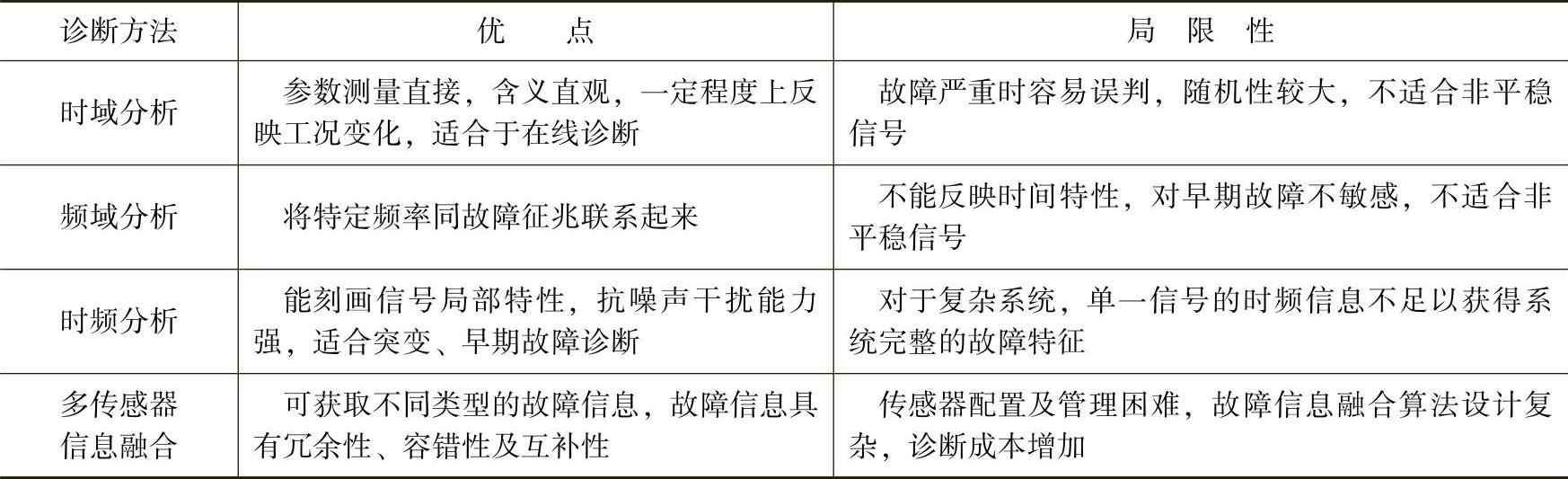
基于信号处理的液压系统故障诊断方法的优点及局限性见表4-1。
表4-1 基于信号处理的液压系统故障诊断方法的优点及局限性
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。