



(1)抗原识别
抗原对应于所要解决的问题。抗原识别就是判断侵入的抗原是不是曾经遇到过的抗原。
(2)初始种群产生
初始抗体对应于问题的候选解。如果抗原识别判断出侵入的抗原是曾经遇到过的,则从记忆单元中取出相应的抗体组成初始种群,否则随机产生初始种群。由于取出的抗体适应度比较高,且有一定的多样性,因而大大地加快了搜索速度。
(3)亲和度计算
分别计算所有抗体的亲和度。亲和度有两种形式:一是指抗体和抗原之间的关系,即解和目标函数之间的匹配程度,又称为适度计算;二是指抗体之间的关系,即候选群之间的相似程度。
(4)记忆单元更新
将适应度高的抗体加入到记忆单元中,由于记忆单元数目有限,因此用新加入的抗体取代与其亲和度高的原有抗体。这样处理的目的是将适应度高的抗体存入记忆单元的同时,保持记忆单元中抗体的多样性。
(5)抗体的促进和抑制
它与抗体的浓度和适应度有关系。适应度高的抗体得到促进,浓度高的抗体受到抑制,其中抗体的浓度是指相近抗体的浓度。(https://www.xing528.com)
(6)抗体的产生
通过交叉和变异两种操作,产生下一代抗体,交叉运算和变异运算是算法中必不可少的运算环节。
1)交叉运算:交叉运算是最重要的遗传操作,种群通过交叉产生新的抗体,从而不断扩展搜索空间,最终达到全局搜索的目的。交叉运算的设计往往与编码方式密不可分,对于二进制编码,基本的交叉算子有单点交叉、两点交叉和均匀交叉;对于浮点编码,基本的交叉算子有算术交叉和启发性交叉。
2)变异运算:变异运算是指对抗体串的某些基因位作改变的操作,引入变异算子可以提供初始种群不含的基因,或找回选择过程中丢失的基因,为种群提供新的内容。变异算子的作用效果在于:一是提高算法的搜索能力,使算法能够搜索到精确解;二是保持种群的多样性,防止出现过早收敛的现象。
(7)循环
重复(1)~(6)步,直到终止条件满足为止。
IGA的流程如图5-7所示。
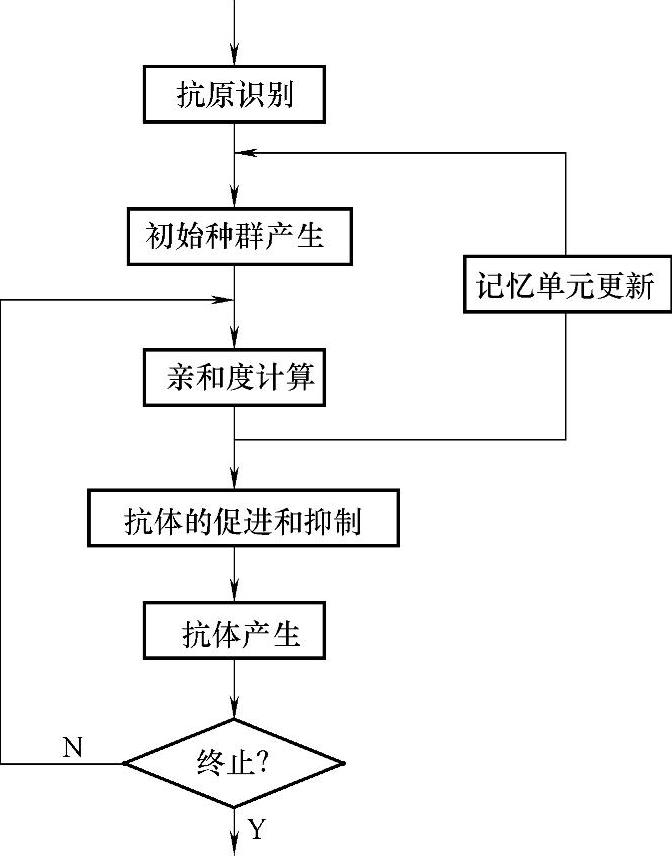
图5-7 IGA的流程
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。