



实验采用了45个从市场上买回来不同品牌、不同批次的淀粉样本,并将其混合穿插标号,主要有玉米和马铃薯两大类:玉米淀粉共29个,其中有25个老样本、4个新样本;马铃薯淀粉共16个,其中有12个老样本、4个新样本。根据这45个淀粉样本的近红外光谱图,用OPUS软件进行聚类分析,建立样本分类模型。
新旧淀粉混合使用建模和验证:本实验使用的淀粉主要有2012年和2014年两个批次,先把新旧淀粉混合在一起进行建模。选择12个马铃薯淀粉样本的原始光谱用来建模,马铃薯淀粉中的3号、12号、20号(新)和35号(新)用作预测。从玉米淀粉中选择25个样本的原始光谱用作建模,玉米淀粉中的10号、19号、30号和40号(新)用作预测,进行聚类分析。
取上述45个淀粉样本逐一放置在旋转样本台的样本杯中,然后进行近红外光谱采集。波数范围为4000~12500cm-1,波长间隔为8cm-1,环境温度为20~23℃。得到的近红外漫反射光谱如图11-1所示,其中,波数在9000~11500cm-1段的光谱图多为噪声,一般情况下都将其忽略不计。
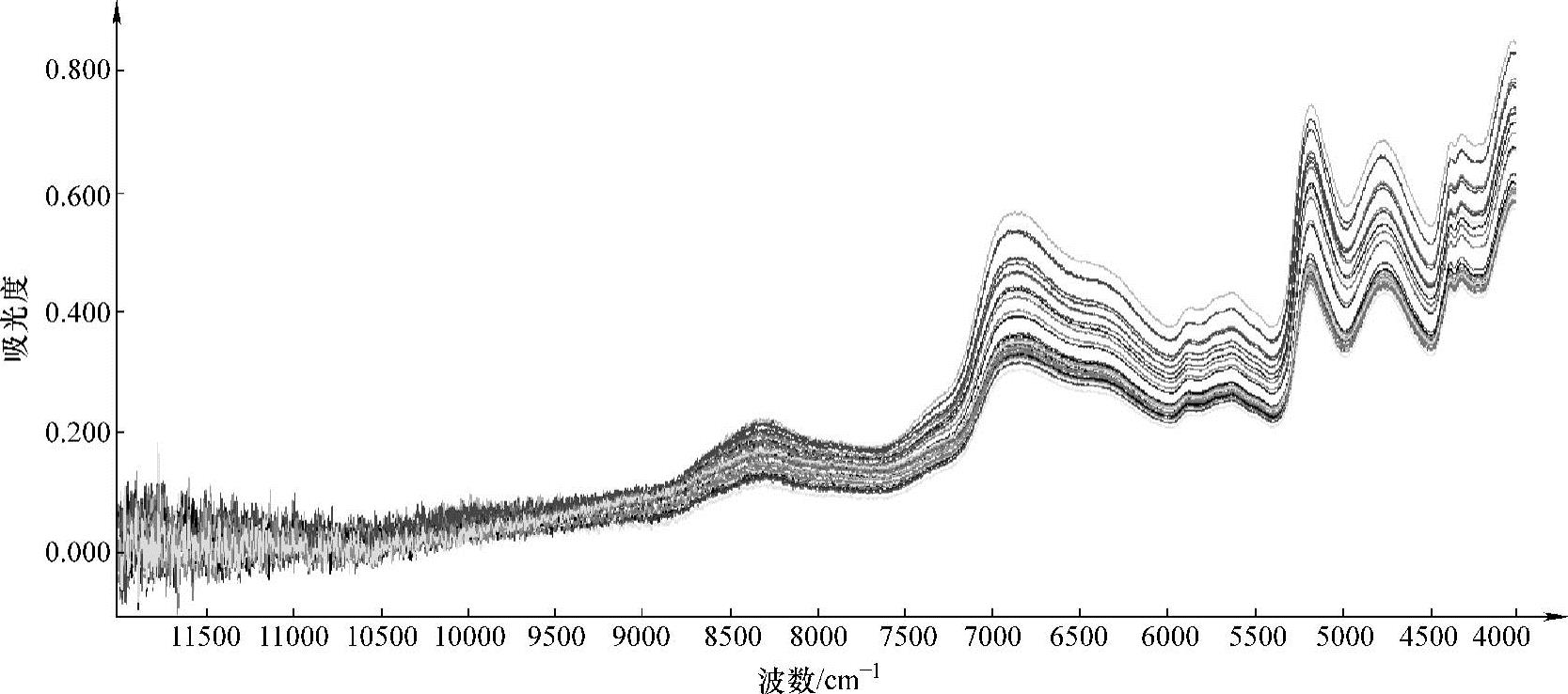
图11-1 45个淀粉样本的近红外光谱图(https://www.xing528.com)
数据预处理的方法选择总共有6种,分别为不进行预处理、SNV、一阶导数、一阶导数+SNV、二阶导数、二阶导数+SNV。各种方法的处理算法并不相同,所以需要逐一进行验证比较,从而选择出最佳建模方案。
注意,实验中要将频谱范围缩小,排除频数近似、波动不大的部分,减小模型的误差,如图11-2所示。
本实验通过选择预处理的方法以及平滑点数不断地试验,找到最合适的方法建立出最佳模型,11.3.2节就是6种建模的结果分类树状图及相应分析说明。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。