



1.简单背景植物油中掺杂单一动物油脂的识别
(1)样本来源及配制方案
目前国家和研究机构对食用油中胆固醇的检测方法主要集中在色谱法、质谱法、色谱质谱联用等化学方法上,虽然以上化学方法检测精度较高,但是检测周期长、操作复杂等因素都严重限制了以上方法的普及推广。由于拉曼光谱的不稳定性(对环境依赖度较高)等原因,现在还没有文献进行食用油中胆固醇的拉曼检测,也无法得到胆固醇拉曼检测的国标限。郭涛等人利用高效液相色谱法做了通过检测胆固醇鉴别地沟油实验,得出该方法的检测限为0.05mg/g。刘薇等人用电导率法进行潲水油检测得知:猪油、猪板油和牛油中胆固醇含量分别为0.75mg/g、1.01mg/g和1.45mg/g。参考已有研究,配制本实验样本见表8-9。
表8-9 猪油和五湖豆油样本配制表
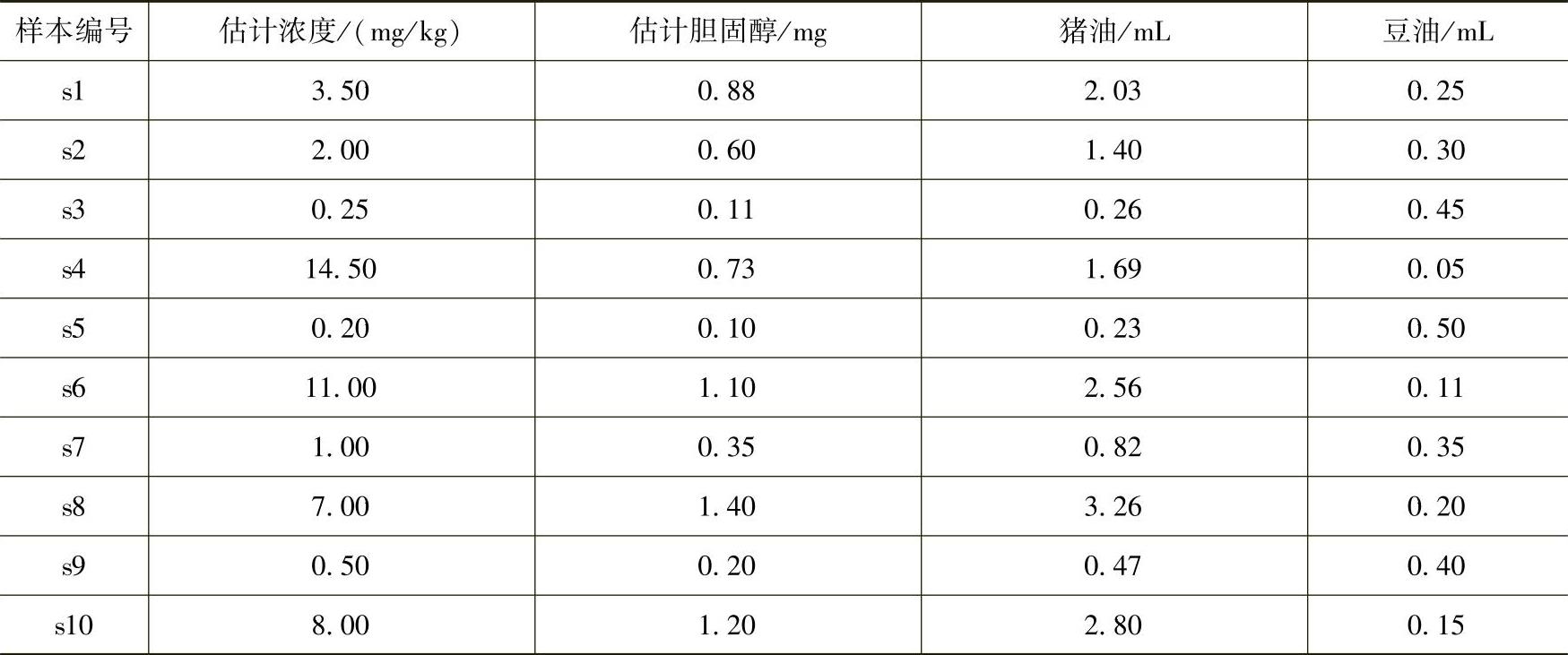
此外为了增加样本的多样性,又加入不同品牌不同批次的豆油作为背景油,每个样本平行配制2个样本,配制方案见表8-10。
表8-10 不同品牌豆油与猪油样本配制

(2)TQ距离匹配分析
纯食用油样本55份,动物油脂28份,共83份样本。其中24份样本用作校验集,59份样本用作建模集。算法采用距离匹配法,通过试验光谱范围采用全光谱时分类准确率最高,基线校正采用二阶导。样本分类结果如图8-29所示,从图中可以看出,TQ距离匹配分析结果较好,真伪样本分类准确率为100%。
(3)Libsvm建模分析
采用Libsvm建模总样本数、掺伪样品数、真样品数均与上述TQ中使用的相同,形成对照。核函数选用多项式核函数。建模集样本61个,预测集样本22个。分类准确率为90.9%。真、伪样品各有一个不能正确识别。

图8-29 TQ初步分析结果
(4)WEKA贝叶斯分类器分析
在WEKA中使用朴素贝叶斯分类器需要将已经得到的数据进行离散化[虽然得到的光谱数据已经是离散化的点,但是贝叶斯分类器对数据有特殊要求,所有的数据要求可以形成一个有向无环图(DAG)]。一共有83个样本,使用28个样本用来作预测集,其余55个样本用作建模集。WEKA数据要求将数据第一行添加为样本的属性值,这就要求数据规模不能过大,所以需要对光谱数据进行主成分分析。这样得到的数据是离散化的,故而在进行分类建模和预测时是针对不同的属性进行的。
进行主成分分析后取前6列作为光谱矩阵的主成分矩阵。这六个主成分列矩阵进行WEKA朴素贝叶斯分类器建模和预测时,人们发现样本属性3能够较好地进行样本分类,分类准确率为71.4%,其余样本属性预测效果都仅是50%左右。
(5)3种算法的比较
相比以上3种算法,距离匹配原理简单且分类效果较理想。
2.复杂背景植物油中掺杂单一动物油脂的识别
(1)样本配制方案
第二部分实验样本配制浓度更低,且背景油采用不同种类和品牌的植物油,期望找出胆固醇拉曼光谱的检测限。每个样本平行配制2个,样本配制方案见表8-11。
表8-11 样本配制表

(2)TQ距离匹配分析
纯食用油样本共55份,猪油掺杂样本18份,共73份样本,其中24份样本作为校验集,49份样本作建模集。校验集中真假样本分别为17份和7份,建模集中真假样本分别为38份和11份。用TQ中的距离匹配原理得到的分析结果仍然是100%(采用二阶导去噪,全光谱建模),如图8-30所示。(https://www.xing528.com)
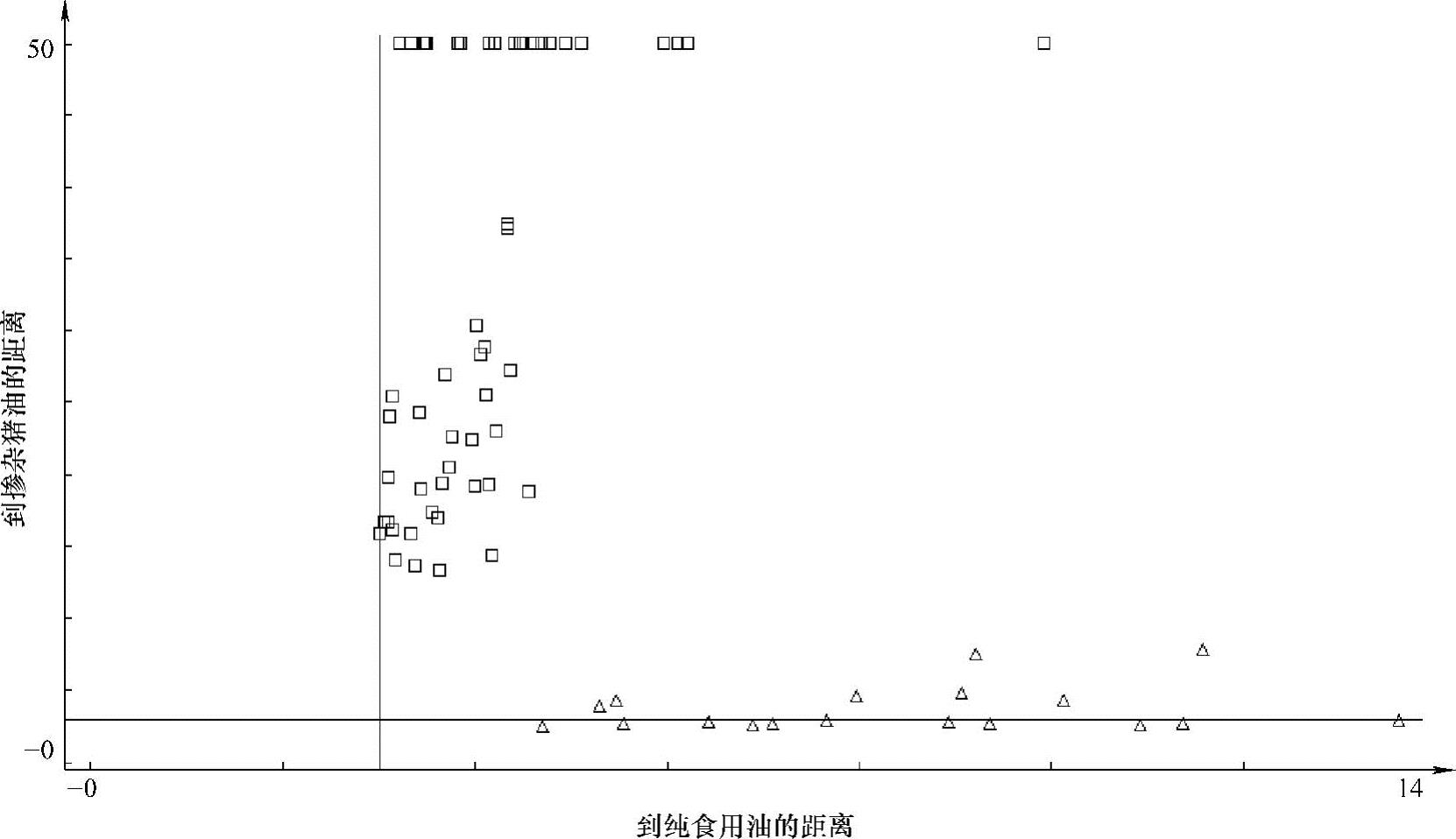
图8-30 TQ距离匹配法建模结果
(3)Libsvm建模分析
核函数采用多项式时识别率为100%,采用高斯径向核函数时识别率为70.8%。共73份样本,其中49份样本用作建模,其余24份样本用作预测。识别效果与TQ相同。
(4)WEKA贝叶斯分类器分析
这里共有73份样本,25份样品用作预测,48份用作建模,其中预测集中正确分类的有20个样本,不能正确分类的是5个。总体识别率能达到80%。
(5)3种算法的比较
通过以上3种算法对复杂背景油动物油脂掺杂样本分类的效果可以看出,距离匹配法和Libsvm识别效果最好,而贝叶斯分类器分类效果较差,只能识别80%的样本。
3.简单背景植物油中掺杂多种类动物油脂的识别
(1)样本配制方案
本部分实验主要探索复杂动物油脂来源情况下,样本分类的效果。其中动物油脂分别采用超市购买的小肥羊火锅清汤底料(内蒙古小肥羊调味食品有限公司)、实验熬制的牛油、分析纯胆固醇(国药集团化学试剂有限公司生产)。背景油采用五湖大豆油,用上述3种识别方法进行鉴别。
实验烹制牛油样和小肥羊清汤火锅底料均为液体油样,其配制方案参照见表8-12。
表8-12 牛油、火锅油、分析纯胆固醇样本配置方案
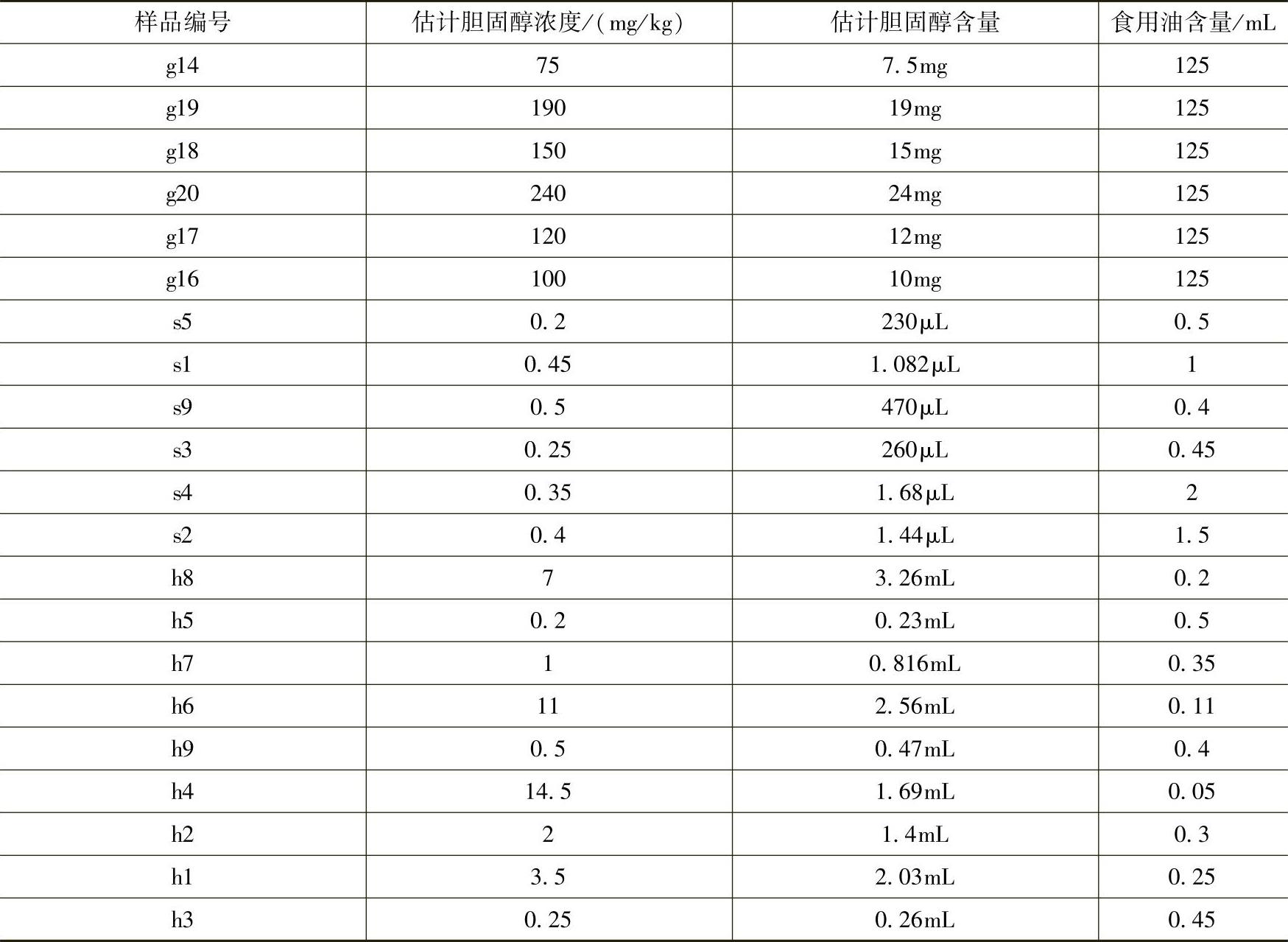
注:牛油试验样本配制,根据文献得知地沟油胆固醇含量为416mg/kg为标准进行配制。以上编号中g代表分析纯胆固醇配制方案;s代表牛油配制方案;h代表火锅清汤油配制方案。
(2)TQ距离匹配分析
TQ分析中共79个样本,胆固醇样本23个,纯食用油样本56个,用24个样本(16个纯油样,8个胆固醇样本)作预测集,55个样本(40个纯油样,15个胆固醇样本)作建模集。距离匹配法分类结果达到96%(只有一个纯油样不能正确识别)。具体分类效果如图8-31所示。

图8-31 TQ距离匹配法分类效果
(3)Libsvm建模分析
建模集和预测集的建立与TQ一样,和函数采用多项式核函数,分类结果也是只有一个纯样本不能正确识别。当和函数采用高斯径向核函数时识别率为66%,但是样本配制用到的背景油纯样可以正确识别,采用cg参数巡游得到的识别效果是一样的。
(4)WEKA贝叶斯分类器分析
采用贝叶斯分类的识别准确率为66.7%(预测集为27个,18个能准确识别,9个不能准确识别)。
(5)3种算法的比较
通过以上3种算法的比较,还是距离匹配法和Libsvm分类效果较好,贝叶斯分类效果样本前处理等还需要进行验证。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。