



1.聚类分析原理介绍
在对众多样本进行模式识别时,人们通常事先并不知道样品内在的分类。其中无监督模式识别方法在未知训练集样本的类别的情况下,同样可以对样本进行分类识别。聚类分析法便是无监督模式识别法的代表,其应用十分广泛。分析流程如图8-1所示。
在多维空间中,相似的样本彼此距离应小些,反之,不相似的样本彼此间的距离会相对较大。也即常说的“物以类聚”,有效地将同类与异类分开,合理地按样本独有的特性来进行合理的分类。
这里的样本相似表示样本间的亲疏程度,通常用相似系数和距离来表征,将每一个样本看成n个变量的一个点,在这样的空间中计算样本间的亲疏程度。相似系数用夹角的余弦值或相关系数表示。
夹角余弦如式(8-1)所示:

式中,xik是第i个样本的第k个特征变量。
相似系数如式(8-2)所示:
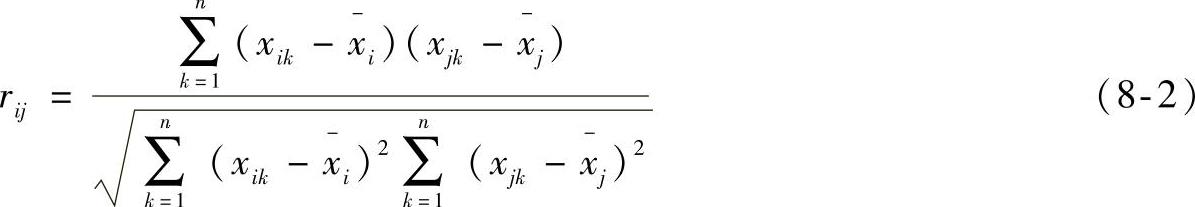
式中,x-i是第i个样本所有特征变量的均值;x-j是第j个样本所有特征变量的均值。
距离则多用欧式距离和马氏距离来表示。
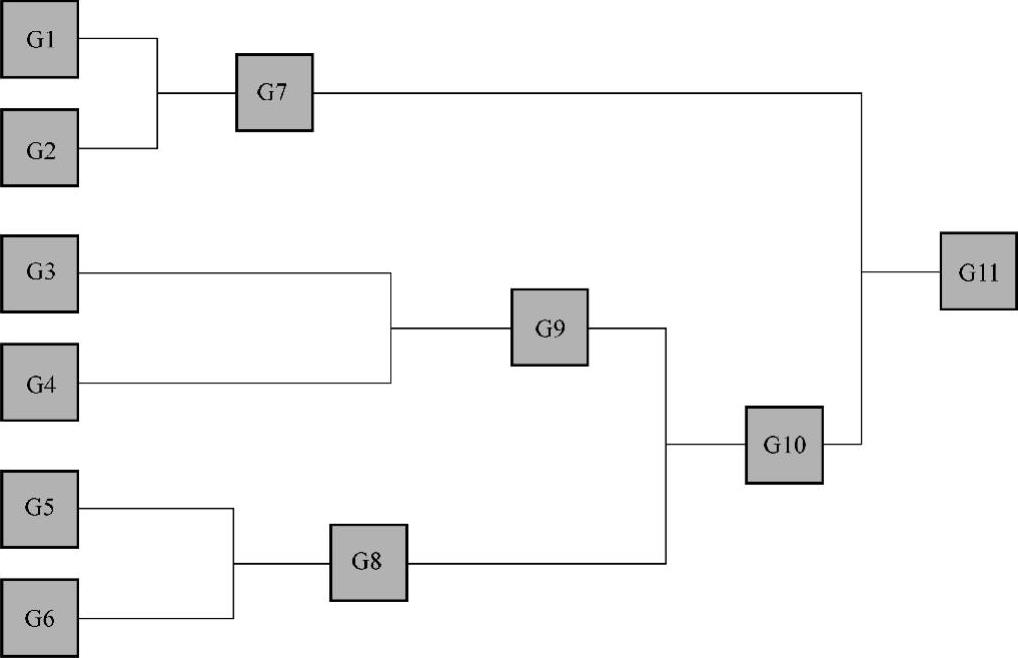
图8-1 聚类分析流程
注:G1~G6代表6个不同的样本类,把距离最近的两个类聚成新类(如G1和G2合成新类G7),再在新类中寻找距离最近的合成另一个新类(如G8和G9合成新类G10)。
根据类间距离的不同定义方式,系统聚类法可分为最短距离法、最长距离法、中间距离法、重心法和方差平方和法。
最短距离法:两个不同类中最短距离的两个样本间的距离定义为两类之间的距离,其计算如式(8-3)所示:
Dγi=min{Dpi,Dqi},(i≠p,q) (8-3)
最长距离法:两个不同类中最长距离的两个样本间的距离定义为两类之间的距离,其计算如式(8-4)所示:
Dγi=max{Dpi,Dqi},(i≠p,q) (8-4)
中间距离法:类与类间的距离采取折中的方法,既不选取两类中距离最近的两个样本,也不选取两类中距离最远的两个样本的距离。
重心法:每类在物理意义上都会存在重心,两类的重心间的距离作为类间的相似性。
方差平方和法:也称为Ward法,该法认定准确的分类应满足类内方差尽可能小,而类间方差尽可能大,其计算如式(8-5)所示:
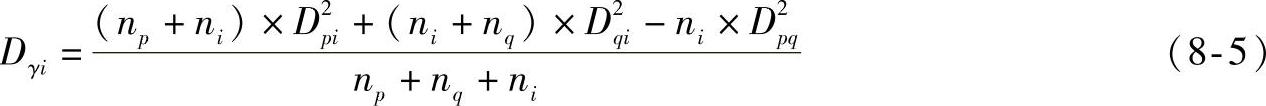 (https://www.xing528.com)
(https://www.xing528.com)
式中,γ是类p和类q聚成的新类;Dpi是类p和类i的光谱距离;Dqi是类q和类i的光谱距离;Dγi是类γ和类i的光谱距离;np是类p中聚类光谱的数量;nq是类q中聚类光谱的数量;ni是类i中聚类光谱的数量。
2.样品制备与光谱采集
本实验收集17个食用植物油样本(在超市购买的不同品牌不同批次样本),其中纯花生油(福临门、鲁花、龙大等品牌)4个、纯大豆油(福临门等品牌)4个、纯橄榄油(多力等品牌)9个。将其编号,分为校正集和预测集样品。1~15号为校正集样本,其中hs01~hs04为纯花生油,dd01~dd04为纯大豆油,gl01~gl09为纯橄榄油。另外收集5个不同的植物油样品,即纯花生油(hs00)、纯橄榄油(gl00)、纯大豆油(dd00)、纯菜籽油(cz00)、纯棕榈油(zl00)作为预测集样本。
采用德国Bruker公司生产的VERTEX70近红外光谱分析仪对原始样本进行全谱测定。检测器为Bruker公司的专利数字检测器。将原始样品分别装入50mm的实验用白色塑料瓶内,采集光谱时,将光纤探头探入样本内部,采用透反射采样模式,对4000~12500-1谱区扫描,分辨率为8cm-1,扫描32次。
22个食用油样本未经任何化学处理,将光纤探头伸入装有样本的小瓶中,逐一扫描样本,每次测量前均用石油醚清洗探头,避免样本间交叉污染。测得的样品近红外光谱如图8-2所示。
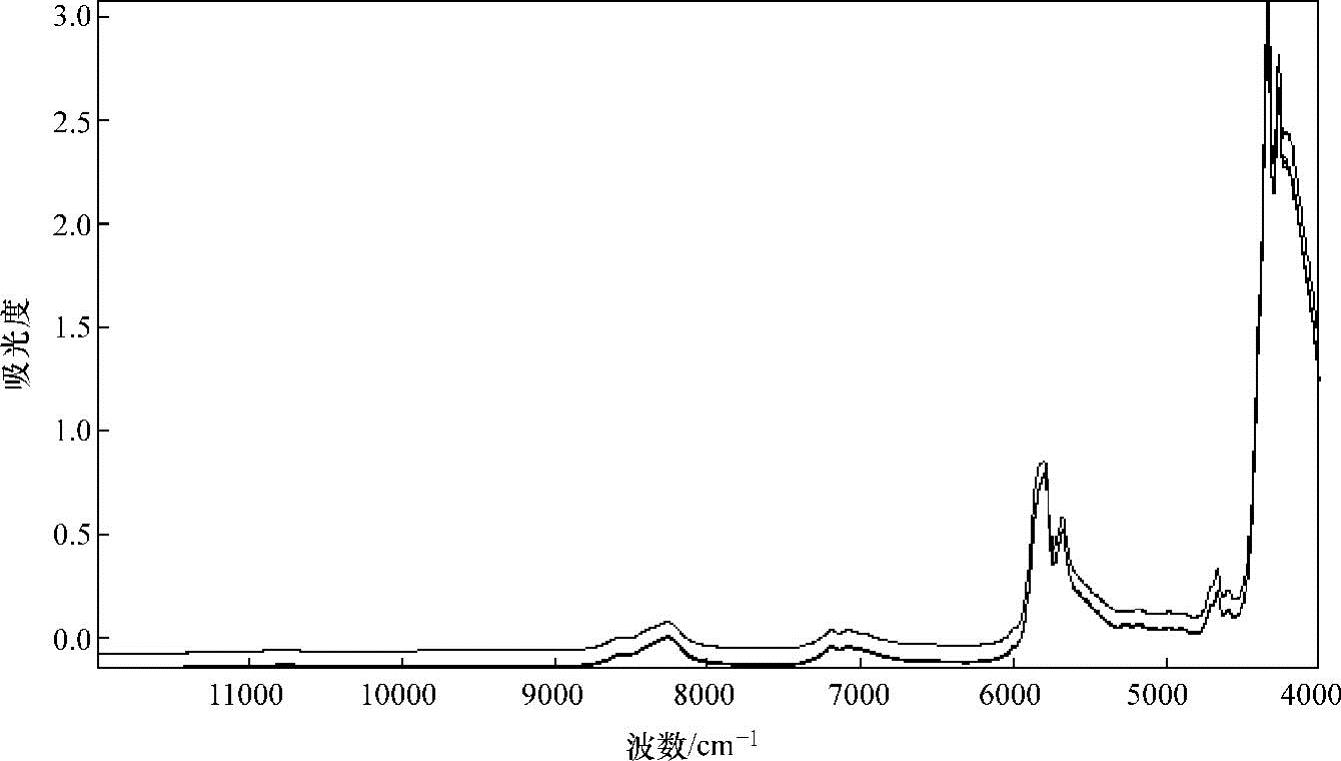
图8-2 样品近红外光谱图
由图8-2可以看出,食用油谱图的峰形、峰位有一定的差别,利用化学计量学的方法对光谱进行预处理,采用系统聚类的算法进行鉴别,可以突出样本之间化学组成含量上的微小差别,从而达到分类的目的。
3.模型建立与测试
(1)模型建立
17个食用油样本采集光谱图后,经过SNV的预处理方法,去除干扰信号,光谱范围选择为4000~9000cm-1。使用OPUS6.5光谱分析软件进行聚类分析,样本间的距离采用欧氏距离法,类间距采用Ward算法。
从图8-3分析可得,样本集可以准确地分为3类,即花生油、大豆油和橄榄油,识别率达到了100%。
(2)模型校验
为考察聚类分析模型的预测能力,使用预测集样本纯花生油(hs00)、纯橄榄油(gl00)、纯大豆油(dd00)、纯菜籽油(cz00)和纯棕榈油(zl00)对该模型进行预测,验证模型的预测准确率。预测结果如图8-4所示。
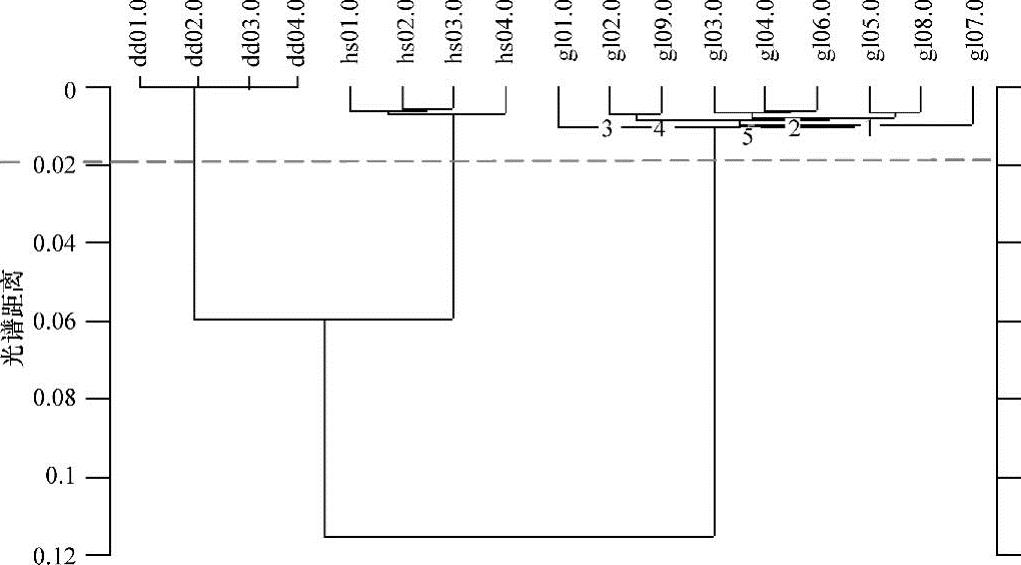
图8-3 聚类分析结果
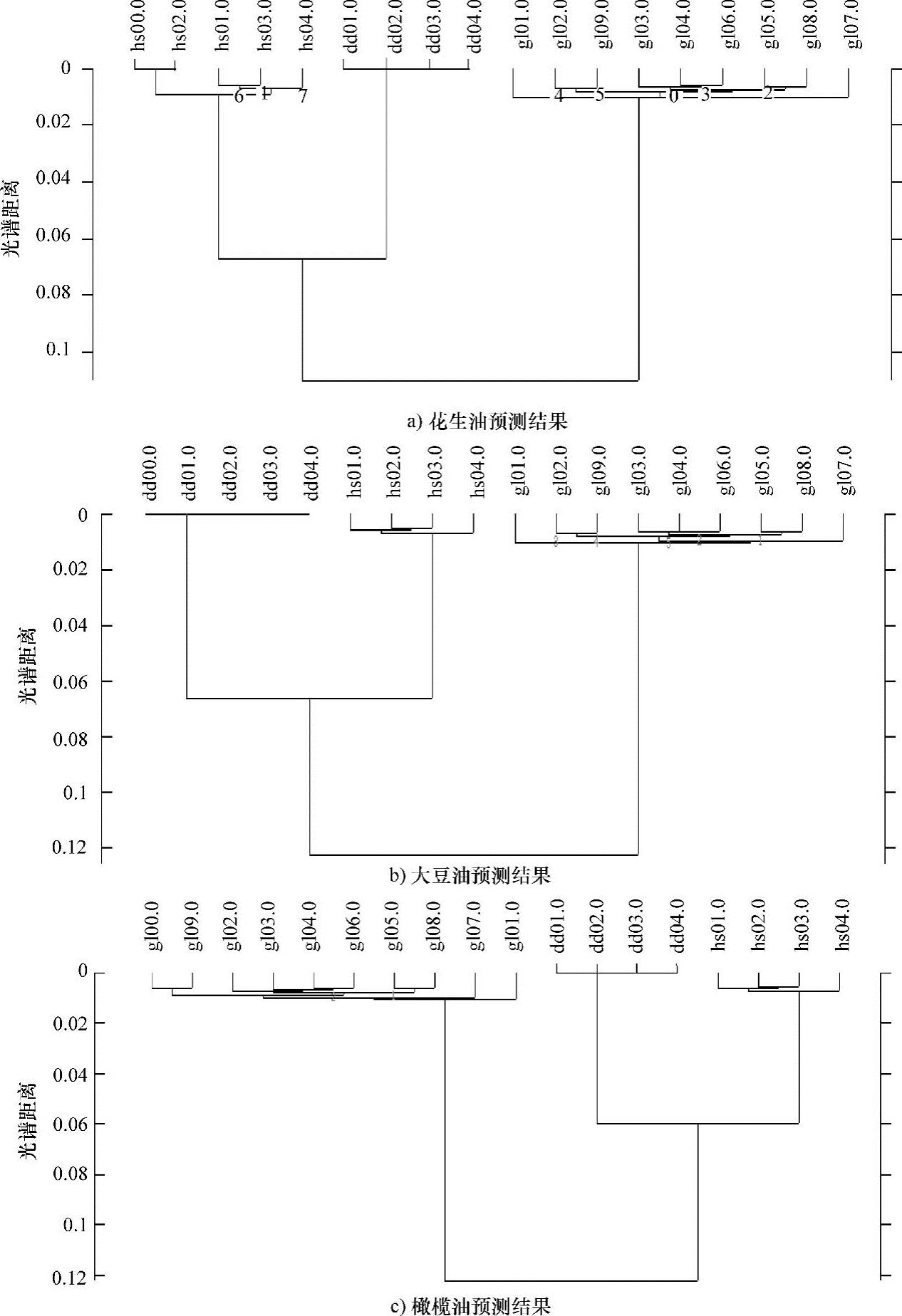
图8-4 预测集样本分析结果图
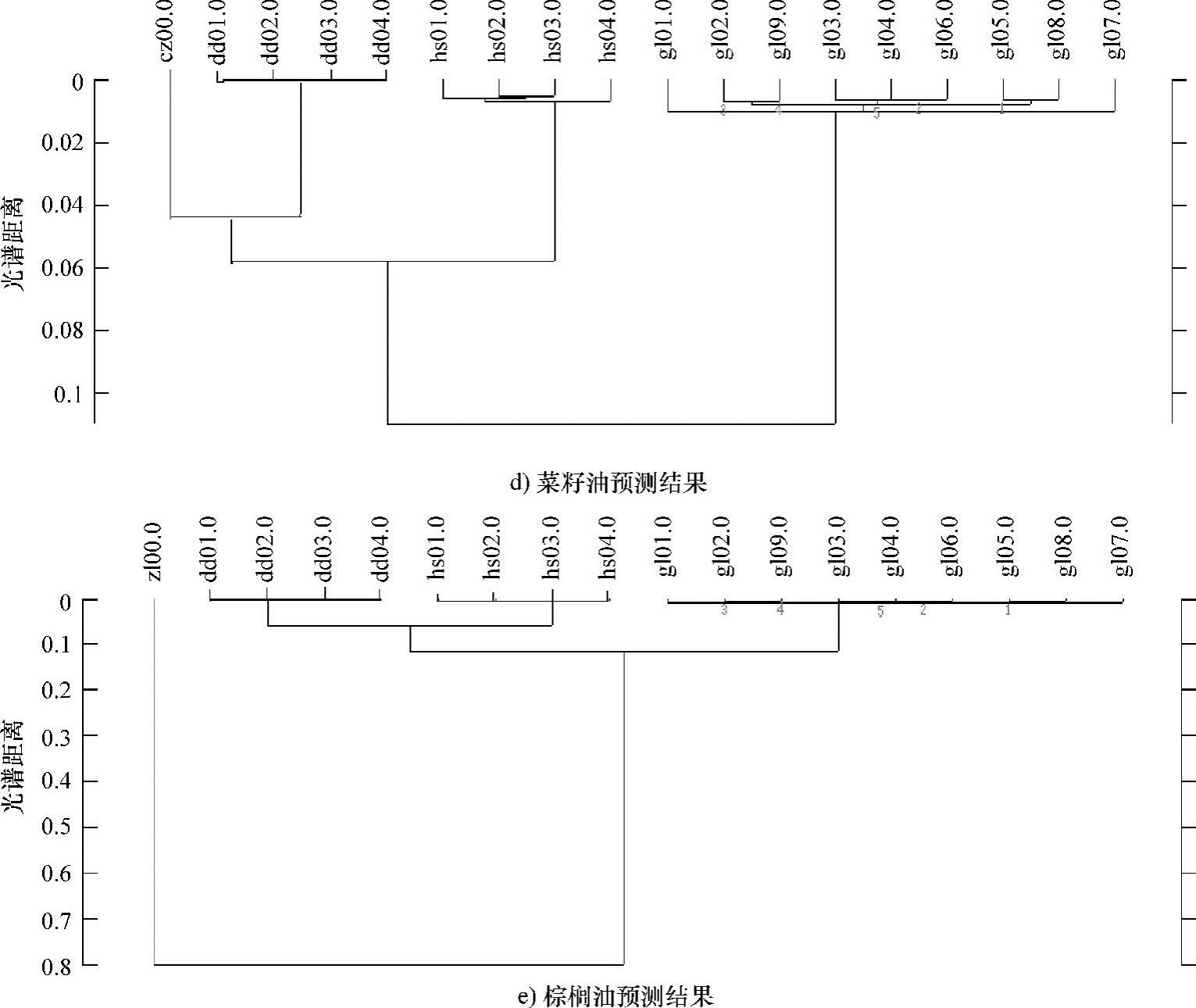
图8-4 预测集样本分析结果图(续)
从预测集样本的预测结果可以得出,当聚类模型类间距确定在0.01~0.04时,纯花生油(hs00)、纯橄榄油(gl00)、纯大豆油(dd00)均能被正确识别和归类,纯菜籽油(cz00)和纯棕榈油(zl00)则可以被确认为不属于花生油、大豆油和橄榄油的任意一种,因此综合建模和预测两者的结果,可将聚类模型的类间距确定在0.01~0.04,则模型的识别率和预测率均可达100%。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。