



1.编码性能与香农限
我们说信道编码是达到香农容量的现实实现方式,这里我们就简单讨论一下他们之间的关系。首先说编码性能,对于给定一个编码方式,以及编码码率和调制方式,现实中不可能一下子就能保证是无误传输的。对每一个信噪比SNR,都对应一个错误概率。显然,SNR越高,错误概率将越小。从错误概率与SNR的关系曲线来看,就对应一条所谓的“瀑布”曲线。当然,只要编码方式、编码码率和调制方式三者之间有一个不同,就对应不同的“瀑布”曲线,如图12-2所示。其中,拿了LDPC和卷积码作为例子来比较示意,一般相同码率和调制方式下,LDPC比卷积码的性能要好,即相同SNR,错误概率要低。但注意,这里仅为性能示意,具体数值不一定绝对准确。
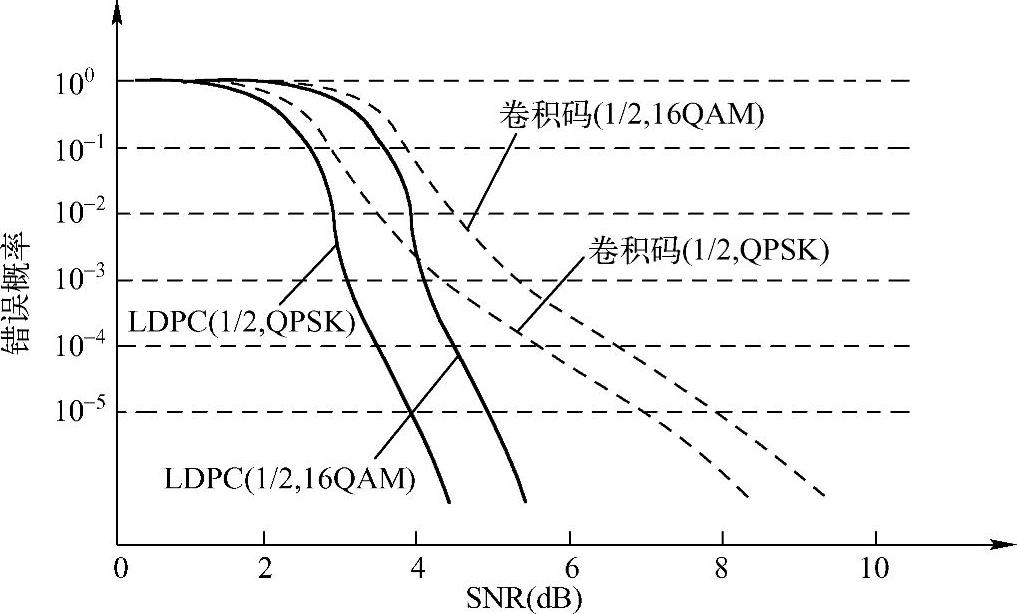
图12-2 错误概率与SNR关系“瀑布”曲线
前面也提到过,达到香农信道容量时,每个数据符号可以从所有实数 (或所有复数)里选择,只要满足信号功率要求即可。而给定一个实际的信道编码和调制方式,调制方式决定了每个数据符号的取值,信道编码方式决定了数据符号序列出现的形式。比如,若调制方式是QPSK,那么数据符号就只有四个取值;而固定调制方式和编码码率,不同的编码方式对同一个消息(原始信息比特)选择了不同的数据符号序列,从而造成性能差异。显然,达到香农信道容量时,是全局优化;而实际的信道编码和调制方式是更进一步限制下的局部优化。因此,无论如何,实际的信道编码和调制方式实际达到的容量(或者说无误传输达到的速率)不可能超过香农容量给出的界限。如图12-3所示,香农容量曲线表示的是复AWGN信道容量与SNR的关系,即满足香农容量(比特每符号)公式:
(或所有复数)里选择,只要满足信号功率要求即可。而给定一个实际的信道编码和调制方式,调制方式决定了每个数据符号的取值,信道编码方式决定了数据符号序列出现的形式。比如,若调制方式是QPSK,那么数据符号就只有四个取值;而固定调制方式和编码码率,不同的编码方式对同一个消息(原始信息比特)选择了不同的数据符号序列,从而造成性能差异。显然,达到香农信道容量时,是全局优化;而实际的信道编码和调制方式是更进一步限制下的局部优化。因此,无论如何,实际的信道编码和调制方式实际达到的容量(或者说无误传输达到的速率)不可能超过香农容量给出的界限。如图12-3所示,香农容量曲线表示的是复AWGN信道容量与SNR的关系,即满足香农容量(比特每符号)公式:
log2(1+SNR)
另一方面,若调制方式采用的是QPSK,那么即使编码速率为1的无误传输也最多能达到2比特每符号,因此任何信道编码不论SNR是多少都不可能超过这个界限;16QAM、64QAM类似。同时,给定一个SNR,现实信道编码和调制不可能绝对无误,那么图中的容量可以用错误概率很小(比如10-5)能达到的最大码率折算的比特数来近似。比如,采用QPSK调制,给定一个SNR,LDPC在错误概率为10-5能支持的最大码率为r,那么在这个SNR和QPSK调制下,LDPC能达到的容量为2×r比特每符号;其他调制编码方式类似。图中比较了LDPC和卷积码,一般来说,LDPC比卷积码更接近香农容量极限。
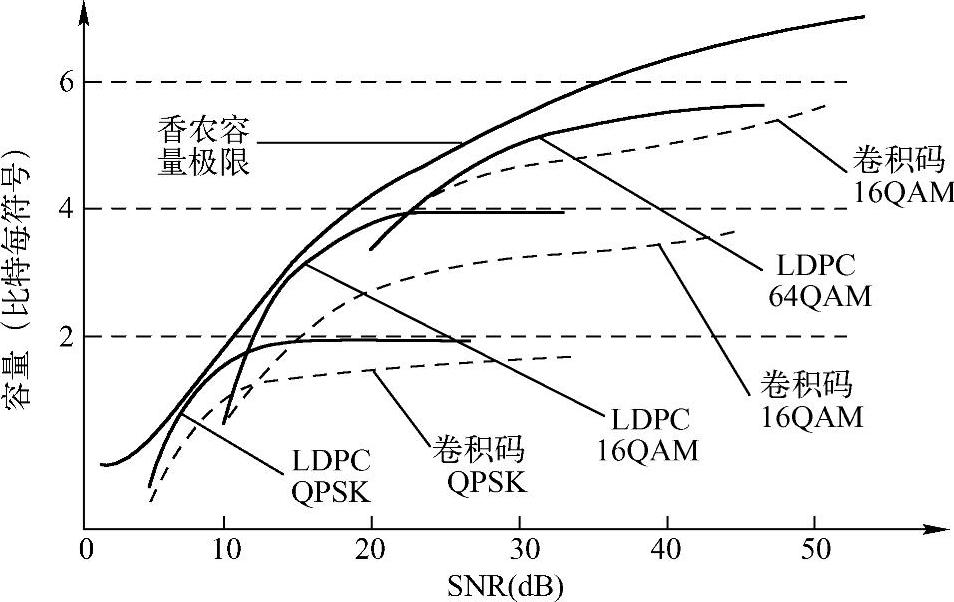
图12-3 香农容量极限与各调制编码方式容量(https://www.xing528.com)
2.选择不错的编码方式
大家都知道线性分组码只要给出一个生成矩阵G就可以了,又或者,卷积码只要给一个卷积规则就行了。但是具体的生成矩阵或者卷积规则,具有哪些特征才算不错的编码呢?这里所谓“不错”主要是从两方面来说:一是性能,二是对应的编译码复杂度。
通常,不管性能还是译码复杂度,都和译码相关。说说译码(或者称为解码),译码一般指接收端通过接收到的比特序列(码字过信道后得到的)来生成一个原始信息比特序列的过程。不管是什么编码,理论上都是可以采用最大似然译码的,即拿所有可能的码字和接收到的比特信息比较,哪一个码字和接收到的比特关系最大(比如计算先验/后验概率),就认为发射端发的是哪个码字,从而该码字对应的原始信息比特就可以判断为发射端真正想要传输的信息比特。
可以看到,在整个最大似然译码过程描述中,译码器只需要知道可能的码字比特有哪些,而不用关心这些码字比特是怎么来的,即具体编码过程的特征(对于线性分组码就是生成矩阵的特征)完全没有在译码算法里体现出来。虽然最大似然译码理论上可行,但实际产品实现的时候,一旦原始信息比特较长,译码复杂度就会很高。比如,原始信息比特若有20个比特,那么可能的码字就有220个,若要用最大似然译码,要比较220个不同的情形,这仅仅20比特已经上百万次比较了,更不用说大多数情形,原始信息比特长度远远超过20个比特。
因此,在最原始、最泛的编码理论中讨论性能,都可以把任何编码看成两串比特之间的映射关系,并不需要编码的结构的概念,也就是没有编码性能与其结构的联系。但大多数情况下,较实际的算法是和具体编码过程的特征相关的。人们在寻找具体的编码方案时,总是带着预想的规则,或者说想要的性质去构造编码方案,当该构造的编码方案现实可用时,这些规则或性质就变成了该编码方案的结构。从而,人们会去研究该编码方案的性能与结构有着怎样的关系,不同的编码结构也可能找到各自适合的译码方式,而不需要都用最大似然译码。
在AWGN信道下,一般把编码后输出的码字间的码距作为一个重要性能参考量。单从两个码字来看,如果他们之间距离越大,则一个被错误接收成另外一个的概率越小;从所有码字整体来看,通常最小码距越大,整体性能越好。但并没有一条绝对规则,可以按这个规则一定能比较出不同编码间的性能差异。每种编码方案性能与结构的关系有其自身的特有之处,不能随便把编码方法甲的性质套到编码方法乙中。
即使应用码距这个大致判断规则,也不尽相同。例如,Reed-Muller码一般能对较少量的信息比特进行编码,且编码到固定长度,所以最小码距是一个比较好的度量;而卷积码,Turbo码等几乎能对任意长度进行编码,如果仅对某个长度的原始信息比特来说,它对应的最小码距仍然是一个比较好的度量;但既然它是为任意长度原始比特设计的,那最好所有比特的性能都考虑进来,从而需要把每一个比特长度的最小码距都考虑进去,即有了所谓“自由距”的考虑。
最后,实际产品中所采用的信道编码方法,往往是性能与复杂度的折中。有可能,一种编码方式的性能更好,但译码复杂度高;人们反而退而求其次,采用性能差一点但译码更简单的编码。不过,复杂度这个指标是相对的、分阶段的。比如,早期的芯片CPU和数字处理技术,连处理百次可能都算复杂,但现在处理上万次也无所谓复杂问题。同样,现在认为上百万次复杂,将来可能也是小菜一碟。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。