



相关性建模分析流程如图3-47所示。首先对产品进行FMECA,即通过系统分析,确定元器件、零部件、设备、软件在设计和制造过程中所有可能的故障模式,以及每一故障模式的原因及影响。在进行了FMECA后,即得到了按照可能发生的概率等级与严酷度等级排序的每个故障模式。据此对UUT的功能和结构进行划分,结合可用测试点建立相关性图示模型,进而建立一阶相关性关系、D矩阵模型,也可由相关性图示模型直接建立D矩阵模型。在建立了D矩阵模型后,可进行测试点优选计算,建立故障诊断树及故障字典,此时可利用生成的诊断策略来预计FDR、FIR。
1.建立相关性图示模型
相关性图示模型是建立D矩阵模型的基础,此模型是在功能框图的基础上建立的。图3-48所示为某简单UUT的功能框图,根据此功能框图,结合可用测试点,即可直接绘制出相关性图示模型,此模型可以直接用于测试性分析。
图3-47 相关性建模分析流程
图3-48 某简单UUT的功能框图
2.建立D矩阵模型
1)直接分析法
此方法适用于UUT组成部件和初选测试点数量不多(即m和n值较小)的情况。UUT根据功能信息流方向,逐个分析各组成部件Fi的故障信息在多测试点Tj上的反映,即可得到对应的D矩阵模型。
2)列矢量法
此方法是首先分析各测试点的一阶相关性,列出一阶相关性表格,然后分别求各测试点所对应的列,最后组合成D矩阵模型。例如,对某一测试点Tj(j=1,2,…,n)的一阶相关性中,如果还有另外的测试点,则该点用与其相关的组成部件代替。这样就可找出与Tj相关的各个部件。在列矩阵Tj中,与Tj相关的部件位置用1表示,不相关部件位置用0表示,即可得到列矩阵Tj。所有的测试点都这样分析一遍,即得到各个列矩阵,从而可组成UUT的D矩阵模型Dm×n。
图3-48所示UUT,通过各测试点的一阶相关性分析,一阶相关性表如表3-40所示,D矩阵模型如表3-41所示。其结果与直接分析得出的D矩阵模型一样。
表3-40 某UUT各测试点的一阶相关性
表3-41 某UUT各测试点的D矩阵模型
3)行矢量法
此方法同样是先根据功能框图分析一阶相关性,列出各测试点的一阶相关性逻辑方程[式(3-52)],然后求解一阶相关性方程组,得到D矩阵模型。
3.优选测试点
在建立了UUT的D矩阵模型之后,就可以优选故障检测用测试点、故障隔离用测试点。
1)简化D矩阵模型识别模糊组
为了简化以后的计算工作量并识别冗余测试点和故障隔离的模糊组,在建立了UUT的D矩阵模型之后,应首先进行简化。
比较D矩阵模型的各列,如果有Tk=T1,且k≠1,则对应的测试点Tk和T1是互为冗余的,只选用其中容易实现的和测试费用少的一个即可,并在D矩阵模型中去掉未选测试点对应的列。
比较D矩阵模型中各行,如果有Fx=Fy且x≠y,则其对应的故障类(或可更换的组成部件)是不可区分的,可作为一个故障隔离模糊组处理,并在D矩阵模型中合并这些相等的行为一行。
这样就得到简化后的D矩阵模型,也可得到故障隔离的模糊组。出现冗余测试点和模糊组的原因是UUT的功能框图中存在多于一个输出的组成单元和(或)反馈回路。
2)选择检测用测试点
假设UUT简化后的D矩阵模型为D=[dij]m×n,则第j个测试点的故障检测权值(表示提供检测有用信息多少的相对度量)WFD可用下式计算:
计算出各测试点的WFD之后,选用其中WFD值最大者为第一个检测用测试点。其对应的列矩阵为
用Tj把D矩阵模型一分为二,得到两个子矩阵,分别为
式中 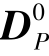 ——Tj中等于0的元素所对应行构成的子矩阵;
——Tj中等于0的元素所对应行构成的子矩阵;
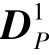 ——Tj中等于1的元素所对应行构成的子矩阵;
——Tj中等于1的元素所对应行构成的子矩阵;
a——Tj中等于0元素的个数;
P——下标,为选用测试点的序号。
选出第一个检测试点后,P=1。如果![]() 的行数不等于零(a≠0),则对
的行数不等于零(a≠0),则对![]() 再计算WFD值,选其中WFD最大者为第二个检测用测试点,并再次用其对应的列矩阵分割
再计算WFD值,选其中WFD最大者为第二个检测用测试点,并再次用其对应的列矩阵分割![]() 。重复上述过程,直到选用检测用测试点对应的列矩阵中不再有为0的元素为止。若有为0的元素,则意味着其对应的UUT组成单元(或故障类)还未检测到;若没有为0的元素存在,则表明所有组成单元都可检测到,故障检测用测试点的选择过程完成。
。重复上述过程,直到选用检测用测试点对应的列矩阵中不再有为0的元素为止。若有为0的元素,则意味着其对应的UUT组成单元(或故障类)还未检测到;若没有为0的元素存在,则表明所有组成单元都可检测到,故障检测用测试点的选择过程完成。
如果在选择检测用测试点过程中,出现WFD最大值对应多个测试点,可从中选择一个容易实现的测试点。
3)选择故障隔离用测试点
仍假设UUT简化后的D矩阵模型为D=[dij]m×n,则第j个测试点的故障隔离权值(提供故障隔离有用信息的相对度量)WFI可用下式计算:
式中 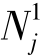 ——列矩阵Tj中元素为1的个数;
——列矩阵Tj中元素为1的个数;
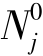 ——列矩阵Tj中元素为0的个数;
——列矩阵Tj中元素为0的个数;
Z——矩阵数,Z≤2P,P为已选为故障隔离用测试点数。计算出各测试点的WFI之后,选用WFI值最大者对应的测试点Tj为故障隔离用测试点。其对应的列矩阵为
用Tj把D矩阵模型一分为二,得
开始时只有一个矩阵,当选出第一个故障隔离用测试点后,P=1。分割矩阵后Z=2。对矩阵![]() 列计算WFI值,选用WFI大者为第二个故障隔离用测试点,再分割子矩阵,这时,P=2,子矩阵数Z=2×2=4。重复上述过程,直到各子矩阵变为只有一行为止,即完成故障隔离用测试点的选择过程。
列计算WFI值,选用WFI大者为第二个故障隔离用测试点,再分割子矩阵,这时,P=2,子矩阵数Z=2×2=4。重复上述过程,直到各子矩阵变为只有一行为止,即完成故障隔离用测试点的选择过程。
当出现最大WFI值不止一个时,应优先选用故障检测已选用、测试时间短或费用少的测试点。(https://www.xing528.com)
可以证明,已知正数A与B之和为C,只有当![]() 时,A与B之积最大,所以用WFI值最大的测试点分割D矩阵模型,符合串联系统中的对半分割思路,可以尽快地隔离出故障部件。也就是说,把原来只适用单一串联系统中对半分割的诊断方法,引申扩展用于复杂系统的故障诊断。
时,A与B之积最大,所以用WFI值最大的测试点分割D矩阵模型,符合串联系统中的对半分割思路,可以尽快地隔离出故障部件。也就是说,把原来只适用单一串联系统中对半分割的诊断方法,引申扩展用于复杂系统的故障诊断。
另外,根据信息理论可知,在UUT中各组成单元故障概率相等的条件下,可用下式近似计算各测试点提供故障隔离的信息量I(tj):
式中 m——UUT的D矩阵模型的行数;
![]() ——测试点Tj对应列中1的个数和0的个数。
——测试点Tj对应列中1的个数和0的个数。
4.建立故障诊断树
建立故障诊断树以测试点的优选结果为基础,先检测后隔离,以测试点选出的先后顺序制定故障诊断树。其过程如下。
1)故障检测顺序
(1)用第1个检测用测试点(FD用TP1)测试UUT分割其D矩阵模型。如结果为正常,且0元素对应的子矩阵![]() 不存在,则无故障;如结果为正常,且0元素对应的子矩阵
不存在,则无故障;如结果为正常,且0元素对应的子矩阵![]() 存在,则要用第2个FD用TP2测试
存在,则要用第2个FD用TP2测试![]() 。
。
(2)用第2个FD用TP2测试![]() 。如结果正常且
。如结果正常且![]() 不存在,则无故障;如结果正常且
不存在,则无故障;如结果正常且![]() 存在,则需用下一个测试点测试。
存在,则需用下一个测试点测试。
(3)选用下一个FD用TP测试,直到![]() 不存在为止(所选出的FD用TP用完)。
不存在为止(所选出的FD用TP用完)。
如任一步检测结果为不正常,则应转至故障隔离程序。
2)故障隔离顺序
(1)用第一个隔离用测试点(FI用TP)测试UUT,按其结果(正常或不正常)把UUT的D矩阵模型划分成![]() 。如测试结果为正常,可判定
。如测试结果为正常,可判定![]() 无故障,故障在
无故障,故障在![]() 中,需要用第二个FI用TP测试
中,需要用第二个FI用TP测试![]() ;如测试结果为不正常,则可判定
;如测试结果为不正常,则可判定![]() 无故障,而
无故障,而![]() 存在故障,需要用第二个FI用TP测试
存在故障,需要用第二个FI用TP测试![]() 。
。
(2)用第二个FI用TP测试剩余有故障部分(有故障的子矩阵),再次划分为两部分![]() 。如测试结果为正常,则故障在
。如测试结果为正常,则故障在![]() 中,需用下一个FI用TP继续测试
中,需用下一个FI用TP继续测试![]() ;如测试结果为不正常,则故障在
;如测试结果为不正常,则故障在![]() 中,需用下一个FI用TP继续对
中,需用下一个FI用TP继续对![]() 测试。
测试。
(3)用下一个FI用TP测试有故障的子矩阵![]() (或
(或![]() ),并把它一分为二,重复上述过程直到划分后的子矩阵成为单行(对应UUT的一个组成单元或一个模糊组)为止。
),并把它一分为二,重复上述过程直到划分后的子矩阵成为单行(对应UUT的一个组成单元或一个模糊组)为止。
在测试过程中,任何一步隔离测试,把原矩阵分割成两个子矩阵后,如某个子矩阵已成为单行,则对该子矩阵就不用测试,而对另一个不是单行的子矩阵继续测试。
3)建立故障诊断树
上述故障检测与隔离顺序的分析结果,可以用简单形象的图形表示出来。从第一个FD用测试点开始,按其测试结果正常和不正常画出两个分支。
对正常分支(以0表示),继续用第二个FD用TP测试,再画出两个分支,其中不正常分支用FI用TP测试,转入隔离分支。而其中正常分支继续用FD用TP测试,直到用完FD用TP,判定UUT有无故障,就可画出检测顺序图。
对不正常分支(以1表示),用第一个FI用TP测试,按其结果为0和为1画出两个分支。再分别用第二个FI用TP测试,画出两个分支。这样连续地画分支,直到用完所选出的FI用TP各分支末端为UUT单个组成单元或模糊组为止,就可画出隔离顺序图。
检测与隔离顺序图画在一起,第一个测试点为根,引出的两个分支为树杈,接着每个分支再用第二个测试点,各自再引出两个分支。这样,直到树杈末端为无故障、单一组成单元或模糊组(即树叶)为止。这样就构成了UUT的故障诊断树。
5.建立故障字典
在优选出测试点之后,UUT无故障时在各测试点的测试结果与有故障时不一样,不同的故障其测试结果也不同。把UUT的各种故障与其在各测试点上的测试结果列成表格就是故障字典。使用前面介绍的测试点优选方法很容易建立故障字典,即在UUT的D矩阵模型(简化后)中,去掉未选用测试点所对应的列就成为该UUT的故障字典。为了便于故障检测,有时加上无故障时所对应的测试结果。
诊断树用于分步测试检测和隔离故障,而故障字典用于在采集各测试点信息后,综合判断UUT是否有故障或哪个组成单元发生故障。
6.诊断能力计算
根据测试点优选结果和画出的故障诊断树,可统计分析得出的测试性参数有选用测试点数、模糊组、FDR、FIR、诊断测试平均步骤数等,这也属于初步的测试性预计。
1)选用测试点数和模糊组
根据测试点优选过程和D矩阵模型,很容易统计出故障检测和隔离用测试点数,以及比初选结果节省了的测试点数。
2)FDR、FIR(未考虑可靠性因素,实为组成单元覆盖率)
式中 UFD——选用测试点能检测的UUT组成单元数;
UFI——选用测试点能隔离的UUT组成单元数;
UT——UUT组成单元总数。
3)诊断测试步骤数
故障诊断(包括检测与隔离)测试步骤的计算,以故障诊断树为基础。树中的测试点为节点,从树根到树叶为分支。各个分支上的节点数就代表找到对应树叶(无故障、部件或模糊组故障)时所需的测试步骤数。所以,UUT的平均故障诊断测试步骤数为
式中 ND——故障诊断平均测试步骤数;
ki——第i个分支上的节点数;
m0——故障诊断树的分支数目。
根据故障诊断树也可以分别计算故障检测的平均测试步骤数和故障隔离的平均测试步骤数。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。