



举例说明字典码的思想。设A和B两人约定用相同的字典(例如辞海)互相通信。A将信文中每个单词用二元标识符(k,l)代替,k和l分别表示单词在字典中的页数和在此页的位置次序。当逐个单词被替代后,就将标识符序列发给B。B收到标识符序列后按标识符恢复单词。如果标识符号数据量少于单词符号数据量,就实现了文本压缩。
LZ-77编码是一种字典编码,算法参见图4.13。算法的主要思想是,把已输入的数据流存储起来,作为字典使用。编码器为输入数据流开设一个滑动窗口(由移位寄存器实现),其长可达几千字节,将输入的数据存在窗内(用实线表示)作字典使用,窗口外是待编码数据的缓存器,长只有几十字节(用虚线表示)。

图4.13 LZ-77编码示意
LZ-77编码用三元标识(k,l,x)给数据编码,k是滑动窗(字典)内从尾部自右向左搜索的字符位数,称为移位数;l是滑动窗内可以与滑动窗外有相同符号的字符串的长度,称为匹配字符串(匹配串)长度;x是窗外已找到的匹配串后的首字符。
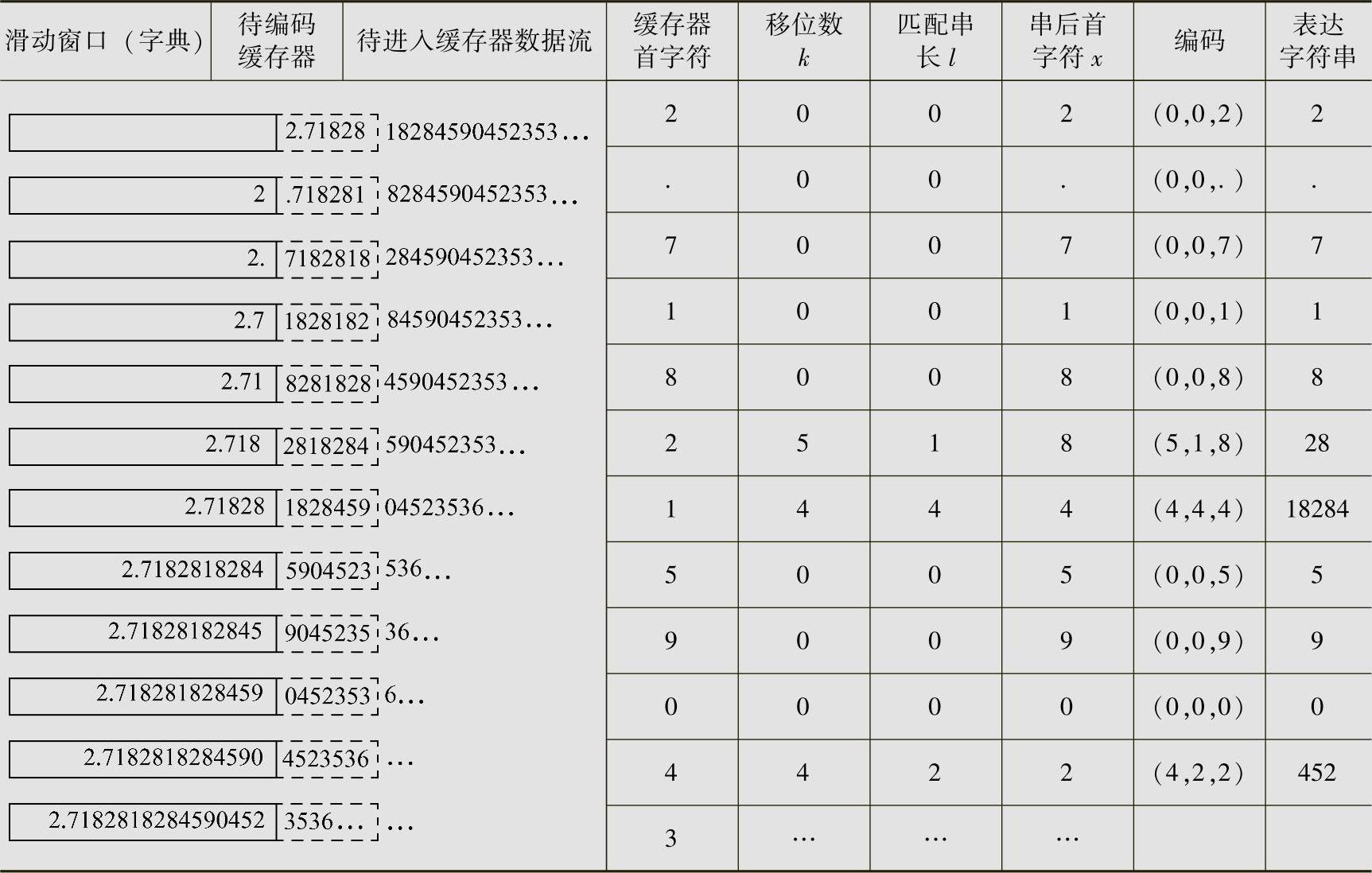
以图4.13为例说明编码过程。待编码缓存器中首字符为“1”,在字典“2.71828”中搜索“1”,其移位数k=4,且有匹配串“1828”,长为l=4,匹配串后的首字符x=4。当用数据(k,l,x)=(4,4,4)编码后,表示编码后的字符串为“18284”,字典更新是将已编码的5位数据字符串“18284”送入滑动窗口,字典更新为“2.7182818284”;同时用后续5位数据“04523”送入待编码缓存器中,待编码缓存器更新为“5904523”。
LZ-77编码器的初始化状态是滑动窗口为空。若窗内没有与待编码字符x匹配的字符时,编码为(0,0,x)。
【例4.22】
用LZ-77编码对自然对数的底e进行编码。
解 自然对数的底e为
e=2.718281828459045235360287471352662497757247093699959574966967…
仅对e的前若干位进行编码。其LZ-77编码的过程见表4.15。表中倒数第2列的所有的标识(k,l,x)序列就是e的压缩编码序列,即
(0,0,2),(0,0,.),(0,0,7),(0,0,1),(0,0,8),(5,1,8),
(4,4,4),(0,0,5),(0,0,9),(0,0,0),(4,2,2),…
表4.15 例4.22的LZ-77编码过程(https://www.xing528.com)
当然应注意两点:
1)若字典内搜索到两个以上的匹配串时,应选匹配长度l大的。若l值相同,并且此时还将对编码后的标识序列再进行二次编码,则取移位数值小的串的k值(这是改进的LZH码);若无二次编码,选移位大的串的k值。
2)若出现下述情形:

则可以编码为(1,5,t),将“eeeeet”输入窗内,这里必须“eeeeet”都在待编码的缓存器内。
LZ-77码的译码器要有一个与编码器字典窗口等长的缓存器,可以边译码,边建立译码字典,即编码字典不用传送,译码器可以自动生成。这种码隐含了假设条件:输入数据的产生模式是相距很近的。
【例4.23】(续例4.22)
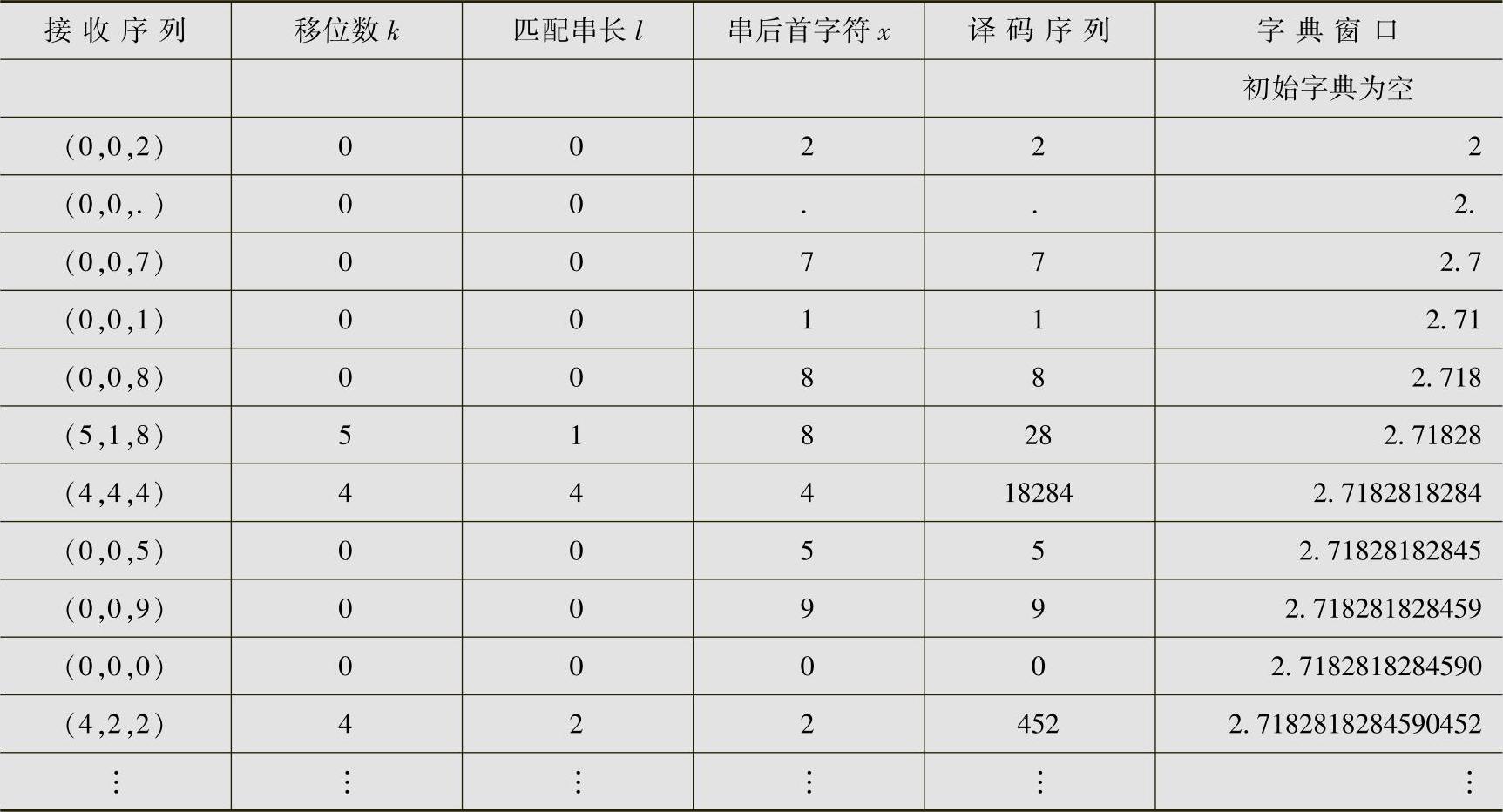
对例4.22的编码结果:(0,0,2),(0,0,.),(0,0,7),(0,0,1),(0,0,8),(5,1,8),(4,4,4),(0,0,5),(0,0,9),(0,0,0),(4,2,2),…进行译码。
解 译码过程见表4.16。译码结果为e=2.7182818284590452…。
表4.16 例4.23的LZ-77译码过程
1980~1990年出现多种对LZ-77的变形码,主要是对窗口数据结构方法和快速搜索方式的各种改进,如著名的LZSS码,又如在1/4英寸盒式磁带技术中也应用了LZ-77码的变形码:QIC-122压缩标准。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。