



实际的离散信源可能是平稳的或是非平稳的。而平稳信源的熵为H∞,非平稳信源的熵H∞不一定存在,但可以假定它是平稳的,用平稳信源的熵H∞来近似。
然而对于一般的离散信源,求H∞也是极其困难的。工程中的解决思路是假定该平稳信源是m阶马尔可夫信源,用m阶马尔可夫信源的熵Hm+1来近似,近似程度取决于记忆长度m的大小,最简单的马尔可夫信源是记忆长度m=1的信源,信源的熵Hm+1=H2=H(X2|X1)。因此,对于一般的离散信源都可以近似地用不同记忆长度的马尔可夫信源来逼近。若再进一步简化信源,即可以假设信源为无记忆信源,而信源符号有一定的概率分布,这时可以用信源的平均自信息量H1=H(X)来近似。最后,则可以假定是等概率分布的离散无记忆信源,用最大熵H0=logr来近似。
根据式(2.83),上述的熵和条件熵之间具有下列关系:
log r=H0≥H1≥H2…≥Hm+1…≥H∞
由此可见,信源符号间的记忆关系使信源的熵减小。如果它们的前后记忆关系越长,则信源的熵越小。并且仅当信源符号间彼此无记忆、等概率分布时,信源的熵才最大。也就是说,信源符号之间记忆关系越强,每个符号提供的平均信息量就越小。每个符号提供的平均自信息量随着符号间的记忆关系的长度的增加而减小。为此,引进信源的冗余度来衡量信源的相关性程度(有时也称为多余度或剩余度)。
定义2.27 信源的实际熵H∞与具有同样符号集的最大熵H0的比值称为信源熵的相对率η,即

信源的冗余度γ为1减去熵的相对率,即
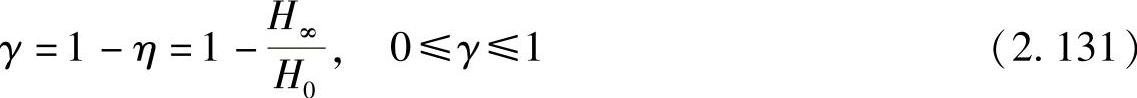
信源冗余度很好地反映了离散信源输出的符号序列中,符号之间记忆关系的强弱和概率分布的均匀性:
1)冗余度γ越大,相对率η越小,信源的实际熵H∞越小。表明信源符号之间的记忆关系越强(即符号之间的记忆长度越长)和/或符号的概率分布越不均匀。
2)冗余度γ越小,相对率η越大,信源的实际熵H∞越大。表明信源符号之间的记忆关系越弱(即符号之间的记忆长度越短)和符号的概率分布越均匀。
3)冗余度γ=0,相对率η=1时,信源的实际熵H∞等于极大值。表明信源符号之间不但统计独立、无记忆,且各符号是等概率分布。
所以在某种程度上,可以认为冗余度表示信源分布的确定性的程度,完全确定性的信源是不含有信息量的,因此是冗余的。相对率表示信源的不确定度的程度,表示信源荷载信息能力的利用率。
【例2.40】
二元信源的符号0和1等概率分布,且符号之间无相关性,则其信源熵达到极大值:H(X)=1 bit/符号,信源相对率η=1,冗余度γ=0。
当信源有记忆和/或非等概率分布时,且实际信源熵为H(X)=H∞=0.8 bit/符号,则相对率为
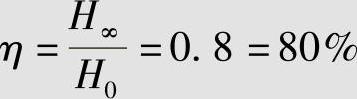
冗余度为
γ=1-η=0.2=20%
为了更经济有效地传输信息,需要尽量压缩信源的冗余度,压缩冗余度的方法就是尽量减少符号间的相关性,并且尽可能地使信源符号等概率分布。
从提高信息传输效率的观点出发,人们总是希望尽量消除冗余度。但是从提高抗干扰能力的角度来看,却希望增加或保留信源的冗余度。因为冗余度大的消息具有纠错能力,抗干扰能力强。对应的信源编码通过减小或消除信源的冗余度,以提高信息的传输效率,而信道编码则通过增加冗余度来提高信息传输的抗干扰能力。
日常的人类自然语言,如汉语、英语、法语、德语等都是由一组符号的集合构成的信源。汉语采用的符号是汉字,英语、法语、德语等采用的符号是一些字母表(还可以加上标点符号和空格)的符号集。自然语言就是由这些符号构成的符号序列。在自然语言的符号序列中符号之间是有关联的,它们都可以用马尔可夫信源来逼近。
【例2.41】
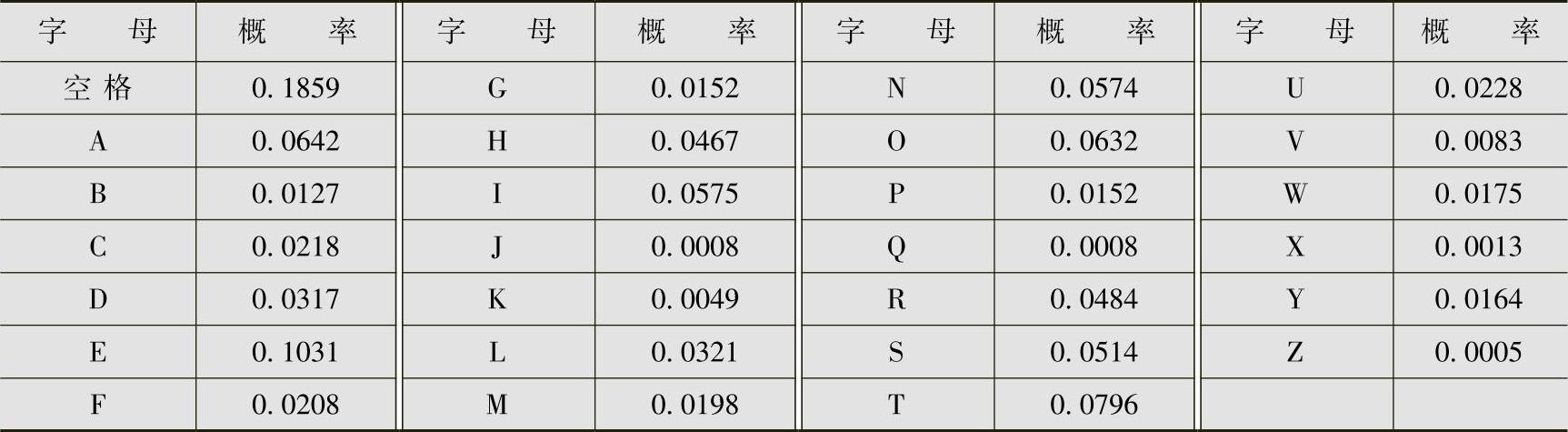
以英文为例,信源由26个英文字母和空格构成(没有空格无法表示一个英文单词和另一个英文单词的分隔,其实还需加标点符号,但不用也可以表达意思,故不计算在内),计算英文信源的冗余度。英文字母(含空格)出现的概率见表2.8。
表2.8 英文字母概率表
解 英文字母组成的信源的最大熵为27个字母(含空格)等概率时情况,其熵为
H0=log 27=4.76 bit/符号实际英文字母组成单词、再由单词组成文章时,英文字母不是等概率出现的,以表2.8的概率分布计算英文的无记忆信源熵为(https://www.xing528.com)
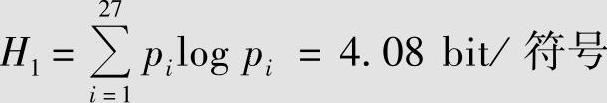
考虑到字母之间的记忆关系,可以把英文信源作进一步的近似,看作1阶或2阶马尔可夫信源。这样可以求得
H2=3.32 bit/符号
H3=3.10 bit/符号
对于实际英文字母组成的信源,其实际熵H∞有许多近似值。这是由于统计逼近的方法不同或所取的样本不一致而引起的差异。一般认为
H∞=1.4 bit/符号
那么,英文信源熵的相对率为
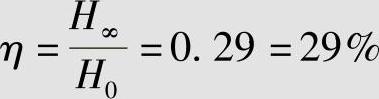
英文信源的冗余度为
γ=1-η=0.71=71%
例2.41的结论说明,英文信源从理论上看有71%是由词法、语法等语言结构确定的,只有29%是写文章的人可以自由选择的。直观地说,100页的英文书从理论上看只有29页是有效的,其余71页是多余的。正是由于这一多余量的存在,才有可能对英文信源进行压缩编码。可见,信源的冗余度表示了信源可以压缩的程度。
用马尔可夫信源模型近似表示英文信源需要计算大量的条件概率,1阶时需要计算272=729项条件概率,2阶时需要计算273=19683项条件概率,而3阶时需要计算高达274=531441项条件概率。这样的计算在更高阶时是完全不现实的。因此,必须采用复杂的语言模型的方法才能进行更准确的信源熵的估计。本书不讨论该方面的问题。
反过来如果有了语言模型,是否可以利用语言模型输出有意义的文章?下面给出Shan-non提出的一种构造近似英文信源的典型字母序列的最简单方法。
【例2.42】
选取一本有代表性的英文书籍,或者从互联网上打开一个较大的英文文件。随机地翻开某一页,并随机地选择该页中的一个字母,假设是Y,将Y作为典型字母序列的第1个字母。在随机地跳过若干行或若干页,读到第一个Y,就读紧随其后的字母,假设为O,将O作为字母序列的第2个字母。然后,再随机地跳过若干行或若干页读到O,将紧随其后的字母作为字母系列的第3个字母。这样反复操作,就能够得到一阶马尔可夫信源所输出的一个典型序列:
YORELD_INGHID_ADRD_HINY_TONEGEPPRT_ORIS_GOF_HESH_T_S_CITH_MAWA-TISE_I_MANT_HOLSIPUSS_TATHED_NAND_WNTH……(1阶近似,100字符)
用类似的方法也可以构成近似的2阶马尔可夫信源所输出的典型序列。随机翻开某一页,随机在该页选择两个连续字母,假设是SI,将它们作为典型字母序列中的头两个字母;接着随机跳过若干行和若干页,读到字母SI,就将紧随其后的字母作为序列的第3个字母,假设为N;然后,再随机地跳过若干行或若干页,并读到两个字母IN时,就将紧随其后的字母作为字母序列的第4个字母。现在每次读两个字母,并将紧随其后的1个字母作为输出,这样反复操作,就能得到近似的2阶马尔可夫信源所输出的一个典型序列:
SING_OUTS_AN_THE_EM_OF_DRIONTHINS_A_WAT_OF_SUCK_THEMORMIN_IFTER_LOSETTER_FOR_MERE_BEEK_HAD_AGING_THA……(2阶近似,100字符)
类似地,可以构造出近似的3阶和4阶马尔可夫信源所输出的典型序列:
TURESE_WORD_IT_I_WAS_ANGER_MOSING_ARENCE_TURNINTY_MRADILY_DID_YEARD_HERE_BY_WAS_IT_COME_OF_LOWED_ONE……(3阶近似,100字符)
FRONT_OUT_I_DECKING_THE_NEXT_MOVEMENT_SMART_OF_ETHERE_LONGER_WHO_HAVE_AND_WET_HIS_CROWDERY_NICE_GOVE……(4阶近似,100字符)
而仅考虑字母分布概率,不考虑字母间的记忆关系时,其输出信源序列:
EN_OILUHASNV_M_YE_SIATE_HNMI_FL_OEITFANH_WOSIOP_IMT_GNTEBT_RSMP_BHYORUA_OY_TAMEISN_EADCTSR_FTE_WOHR……(0阶近似,100字符)
从例2.42可见,当考虑的英文字母间的相关性越强时,其输出就越接近英文。如果将例2.42中的方法从以字母为最小单元改进成以单词为最小单元,则输出的字母序列的符号间相关性就更强了(此时,单词是准确的),从简单的形态上看就更像英文了。
从提高传输效率的观点出发,总是希望减小或去掉信源的冗余度。如发送中文短消息时,为了经济与节省,总希望在原意不变的情况下尽可能把中文写得简洁些。例如,把“中华人民共和国”压缩成“中国”,原意未变,消息简洁得多,冗余度减小了。
但冗余度也有它的用处,冗余度大的消息具有强的抗干扰能力。当干扰使消息在传输过程中出现错误时,能够通过前、后文之间的关联关系纠正错误。例如,收到消息“X华人民共X国”,很容易把它纠正为“中华人民共和国”。如果是传输压缩后的文字“中国”,而接收到的是“X国”,就不知道是“中国”“美国”“英国”……若接收到“中X”,则原文可能是“中国”“中间”“中场”……所以,从提高抗干扰能力角度,总是希望增加或保留信源的冗余度。
还可以从另一个理解语言的角度来说明冗余度在接收信息中的重要作用。一般人都有这样的经验,听中文广播时注意力不需要太集中,即使是边听边做其他事,同样能听懂广播的大意。这是因为听者并不需要完全听清一句话中的每一个字,才能听懂整句话的意思。但是听外语则不然,以英语为例,初学者都有这样体会,哪怕注意力高度集中地去听,而且句子中的每一个单词都学过,要想听一遍就听懂也非易事。如果一篇文章中有几个生词,往往是成句成段地听不懂。这是因为听者对每个单词的发音、对句型都不太熟悉,必须在听完了一句话的每一个单词,才能了解全句的意思。反应稍有迟钝,后面的单词或句子就听漏了。这其实是语言的冗余度不够所造成的。
后面将要学习的信源编码和信道编码就是针对数据的冗余度进行的。信源编码就是通过减小或消除冗余度来提高通信效率,而信道编码则是通过增加冗余度来提高通信的抗干扰能力,即提高通信的可靠性。通信的效率问题和可靠性问题往往是一对矛盾。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。