



1.泰勒级数法
已知函数y(x)在区间(a,b)上有初值y(a)=y0,现在考虑解下列微分方程来求y(b)
y′=f(x,y)
首先,把区间(a,b)等分为n份,每份长h=(b-a)/n,然后在每个点(xi=a+ih,i=1,2,…,n)上求y(x)的近似值。由泰勒级数可得
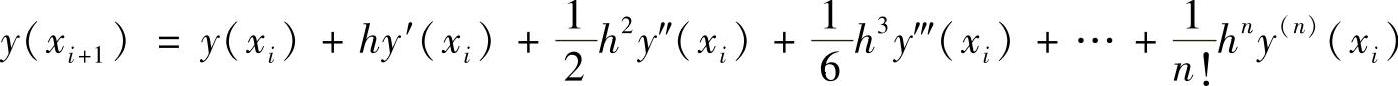
如果h很小,可以忽略掉h的2次方以上的项,于是上式可以写成
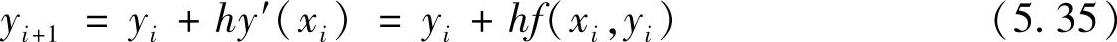
这里,yi+1表示y(xi+1)的近似值。这个保留了1次项的泰勒级数法又称为欧拉方法(Euler Method)。该方法非常直接了当,已知y0,即可按1阶计算精度依次求得y1,y2,…,yn,直至得到y(b)。
欧拉方法只有在h很小时,才可以达到较高精度。为了提高精度,简单的方法就是保留到泰勒级数的2次项,即

上式中的2阶微分项可以进一步写为
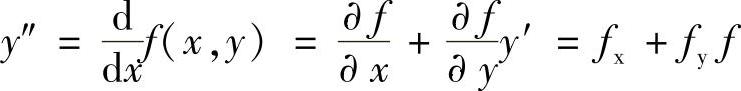
fx、fy分别表示对x、y的偏微分。于是,可得到下列递推近似公式(2阶泰勒级数法)
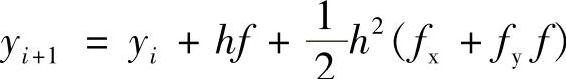
已知数据点(xi,yi)上的f、fx、fy,即可求得下一个数据点上的函数值。同样,也可以推导出3阶泰勒级数递推公式以及更高阶的泰勒级数递推公式。但是,高阶泰勒级数展开也引入了高阶偏微分,使得计算变得很复杂。
2.Runge-Kutta法
为了避免高阶泰勒级数方法所带来的偏微分计算问题,大约在1900年,德国数学家C.Runge和M.W.Kutta提出了只需要f便可进行递推运算的数值积分方法,这一重要的方法被称为Runge-Kutta法。同前面介绍的方法一样,Runge-Kutta法也有1阶、2阶等类型。其中,最常用的是4阶Runge-Kutta法,简称RK4法。其递推公式为
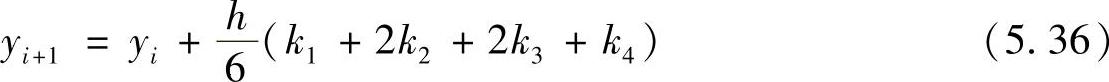
这里k1=f(xi,yi)

可见,在这个递推公式中没有引入偏微分计算。RK4法的误差为步长的5次方,具有4阶计算精度。
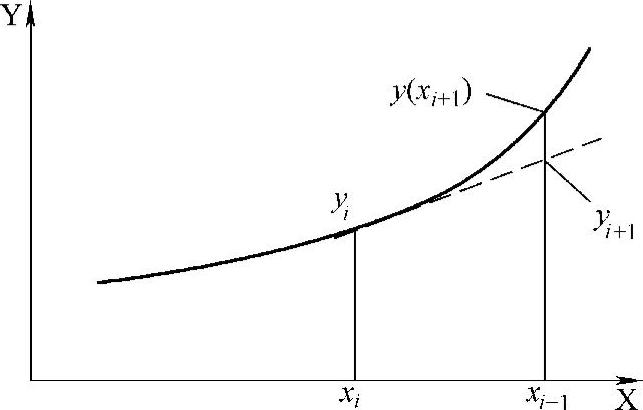
图5.11 显式解法示意图
3.隐式解法
以上方法均是由已知的数据点的值来进行递推运算,这种方法称为显式解法(Explicit Method)。例如前面介绍的欧拉方法就是用i时刻的值递推i+1时刻的值,公式为
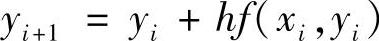
图5.11为该方法的示意图。其中,xi+1-xi=h,f(xi,yi)为点(xi,yi)处的斜率。
由图5.11很容易想到,若用点(xi,yi)和点(xi+1,yi+1)的斜率的平均来代替上式中的f(xi,yi),则可能改进计算精度,即可以构成以下递推关系

但是,式(5.37)右边含有未知的yi+1,因而不能直接进行递推运算,需要用反复迭代方法求解该方程。这种方法称为隐式解法(Implicit Method)。
为了研究该方法的精度,把式(5.37)中的f(xi+1,yi+1)用泰勒级数展开

即式(5.37)可以写成
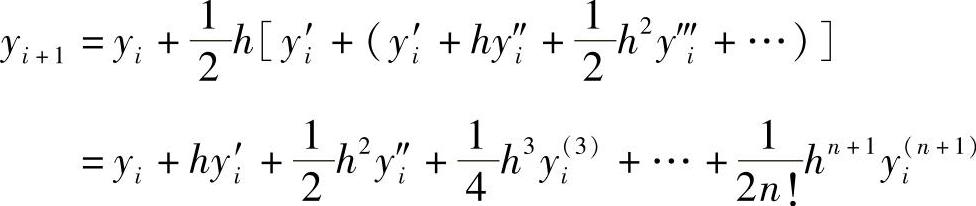
对比用泰勒级数表示的真值
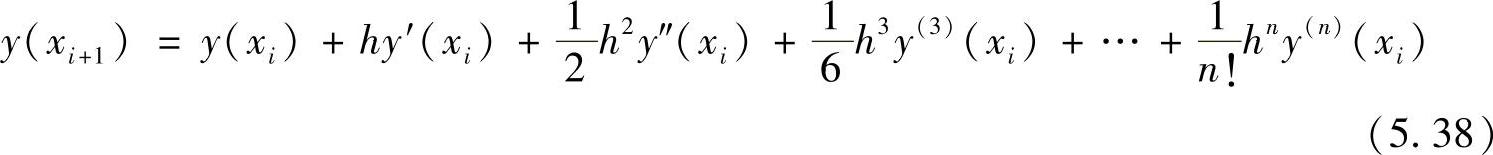 (https://www.xing528.com)
(https://www.xing528.com)
可见,误差从y‴的项开始,误差项的系数为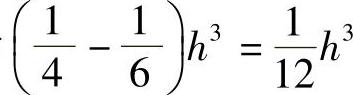 ,即式(5.37)的误差为3次,精度为2阶。可见,该方法把欧拉解法的1阶计算精度提高到了2阶精度。
,即式(5.37)的误差为3次,精度为2阶。可见,该方法把欧拉解法的1阶计算精度提高到了2阶精度。
Runge-Kutta法也有隐式解法的形式,以下为4阶Runge-Kutta隐式解法。
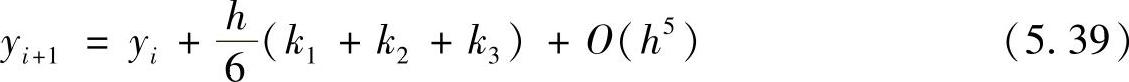
这里k1=f(xi,yi)
k2=f(xi+0.5h,yi+0.25h[k1+k2])
k3=f(xi+h,yi+hk2)
在求解k2时,需要用到迭代算法。和显式解法式(5.36)相比,要达到同样的4阶精度,隐式解法只需要3步运算。但是,隐式解法求解k2可能比较费事。
显式算法一般只有条件稳定性,即积分步长必须小于某临界值;否则,计算将发散。相比之下,隐式算法具有无条件稳定性,原则上积分步长不受限制。这是隐式算法的一大优点。
4.多步法(Multistep Methods)
以上介绍的各种方法均属于单步法,即求(i+1)点的值只用到了相差1步的i点的值。容易设想,如果用已知的多个数据点的值来估算(i+1)点的值,则有可能提高精度。例如单步的欧拉法可以改为(参照图5.12)

即用(i-1)和i两点的数据来计算(i+1)点的值,这种方法称为多步法。

图5.12 多步法示意图
把式(5.40)中的yi-1用泰勒级数展开

代入式(5.40)后进行整理,可得
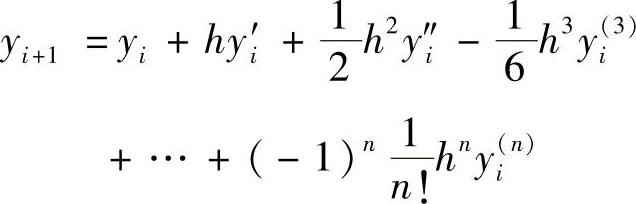
与真值式(5.38)相比可知,由式(5.40)进行运算的误差为3次,计算精度为2阶。
多步法的一般形式为

系数a1,a2,…,as和b0,b1,…,bs决定了方法的形式。若b0=0,上述方法为显式算法;若b0≠0,上述方法为隐式算法。
典型的显式多步法是Adams-Bashforth法。例如2步、3步、4步的公式分别为

典型的隐式多步法则是Adams-Moulton法。例如1步、2步、3步的公式分别为

式(5.42)和式(5.43)中各式的最后一项代表误差项,其中,ξ为区间(xi,xi+1)上的某值。隐式多步法的误差比相应的显式多步法的要小。在实际应用中,常常把显式多步法同隐式多步法结合起来,形成一个“预测-校正”系统。例如用Adams-Bashforth法预估出yi+1,然后把这个值作为初始值,代入到Adams-Moulton公式中进行迭代运算,以求出更准确的yi+1。
“预测-校正”系统的一个好处是容易估计每一步的误差。例如用y(xi+1)表示时刻(i+1)的真值,用y0i+1代表由4阶Adams-Bashforth法得到的预测值,用yi1+1代表由Adams-Moulton法得到的校正值,则有下列关系
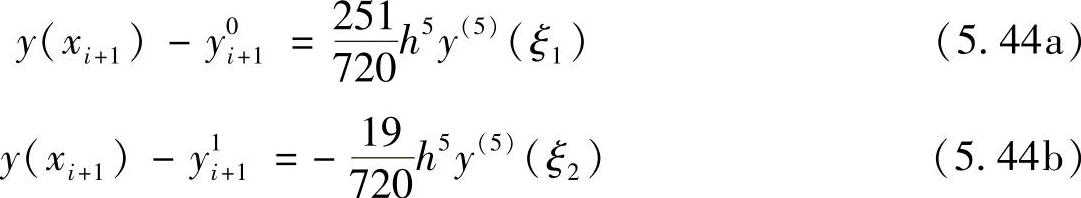
在很小的积分步长h上,可以认为y(5)(ξ1)=y(5)(ξ2)=y(5)(ξ),式(5.44a)和式(5.44b)相减求得y(5)(ξ),再代入式(5.44b)中,可得到由预测结果和校正结果表示的误差
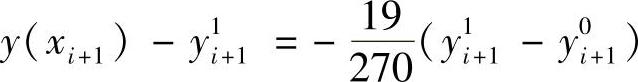
这个误差可以用来作为调整积分步长的判断依据。
同Runge-Kutta法相比,多步法的一个优点是函数运算的次数少。例如4阶Adams-Bashforth法每递推一步仅需计算一次新的f(x,y),而用4阶Runge-Kutta法则要计算4次f(x,y)。当函数f(x,y)很复杂时,这个优点将很突出。
多步法的一个缺点是在已知初值的条件下,还不能启动递推运算。以式(5.40)为例,由初值条件可得y0,但这还不够,需要先用单步法求出y1以后,才可以启动递推运算。在计算途中想改变步长h时,也会遇到同样的问题。
此外,收敛性和稳定性是应用显式多步法时必须考虑的问题。当积分步长超过临界值时,会出现计算发散的现象。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。