



除了基于Flume风格的推送数据的方式外,还可以使用定制的Sink,基于拉取数据的方式整合Flume与Spark Streaming。使用拉取数据的方式有以下两个优点:
1)Flume将数据推送到定制的Sink,并且这些数据会被缓存起来。
2)Spark Streaming使用一个可靠的Flume Receiver和事务处理从Sink中拉取数据。事务仅仅在数据接收并在Spark Streaming中备份后才算成功。
拉取数据方式相比第一种方法,可以确保强可靠性以及增加了对容错方面的保证。
拉取数据方式的一般性的要求:需要选择一台机器,在一个Flume Agent上运行定制的Sink,Spark机器中的机器节点必须可以访问运行定制Sink的这台机器。
(一)配置Flume
1.在负责运行定制Sink的节点上,将定制的Sink对应的jar包添加到Flume的lib路径下。定制的Sink对应的jar信息如下:
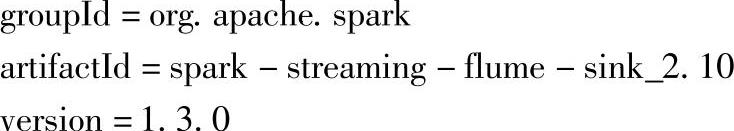
可以到Maven仓库手动下载该jar包。
2.在该机器上,为Flume Agent设置定制的Sink相关的配置信息,信息内容如下所示:

其中:
1)agent对应Flume Agent的名字。
2)Spark对应定制的Sink的名字。
3)org.apache.spark.streaming.flume.sink.SparkSink对应的是定制Sink的类名,由于不是Flume内置的Sink,因此需要使用全路径。
4)memoryChannel对应定制的Sink所关联的Channel名字。
5)hostname与port是接收数据的机器信息。
(二)Flume+SparkStreaming实践案例与解析
同样,整合应用程序也需要添加sparkSpark-streaming-flume_2.10依赖包。对应的部署方式也一样。
(三)FlumeAgent配置案例与解析
复制基于Flume风格的推送数据方式中的配置文件avro.conf为spark.conf。然后,将其中的Sink的名字avroSink修改为sparkSink,同时,修改该Sink的type信息,由avro修改为定制的Sink,即org.apache.spark.streaming.flume.sink.SparkSink。
对应的配置文件内容如下:


配置文件中,重点关注sparkSink的属性配置,这里配置为Agent所在的hostname,Spark Streaming应用启动后,通过该hostname和port信息,拉取信息。
当前配置文件中的配置对应的数据流如图4.44所示。
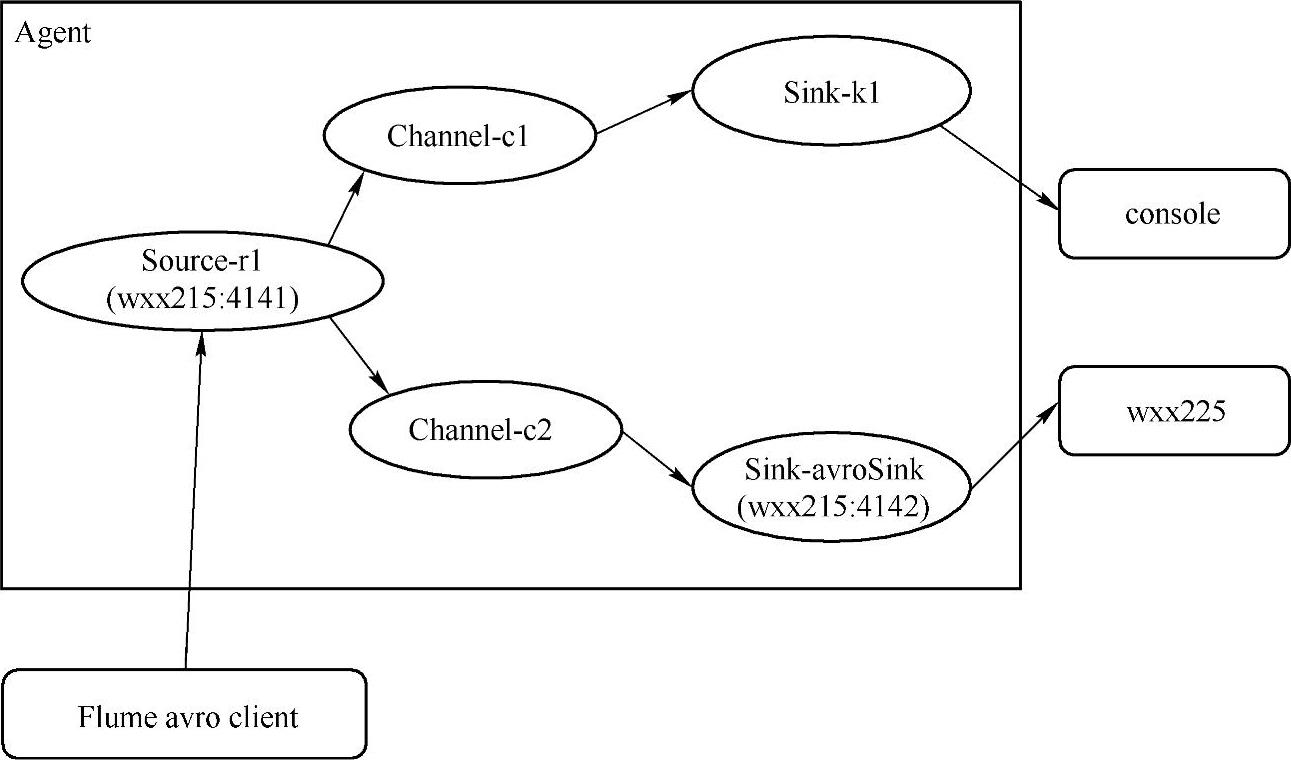
图4.44当前配置对应的数据流图
用新配置的属性文件spark.conf,启动Flume Agent:

由于sparkSink上定制的Sink,不是Flume内置的,使用时,需要先将定制的Sink对应的jar包(spark-streaming-flume-sink_2.10-1.3.0.jar)添加到启动Agent时的CLASS-PATH路径下,这里复制到$FLUME_HOME/lib路径下:

重新启动Agent,启动过程会出现一些类找不到的错误提示,这是因为定制的Sink所在的jar包依赖了Scala的jar包和Spark的jar包。Flume中用到了Hadoop的类库,启动Flume Agent时会自动去识别环境变量$HADOOP_HOME,然后添加Hadoop的类库到Flume运行的CLASSPATH下,可以参看启动Agent时,界面输出信息中的CLASSPATH内容,是包含hadoop lib下的jar包的,也就是说,如果环境中没有配置Hadoop的环境变量$HADOOP_HOME,启动Agent时也会报类找不到的错误。而对应的Scala和Spark类库,则是因为引入定制的Sink才需要的,因此默认情况下是不会自动识别$SCALA_HOME和$Spark_HOME这两个环境变量,然后自动添加所需jar包到Flume的CLASSPATH路径下的。
这本机上测试时,错误信息如下:
1.找不到Scala类的错误信息

2.找不到Spark类的错误信息

解决方法,是将Scala和Spark的类库放入Flume的CLASSPATH(对应用Java命令执行时的-cp选项)下,具体步骤如下:
1)编辑Flume的环境变量配置文件conf/flume-env.sh。
2)将Scala和Spark的lib类库添加到环境变量,如下所示:

在启动过程中,还可能会出现以下错误,如Flume的方法找不到的错误信息:

在启动时,将-c选项设置为Flume的conf即可。
小技巧:在vim中替换全局的字符串,可以使用“s/avroSink/sparkSink/g”这种方式,会将文件文件中第一个字符“avroSink”全部替换为“sparkSink”;输入/string可以搜索string字符串,输入n可以查找下一个。具体请参考vim使用手册。
修改CLASSPATH成功,指定sparkSink的“host:port”,再次启动Spark Streaming应用,比如:

再次向source-r1指定的“host∶port”发送数据:(https://www.xing528.com)
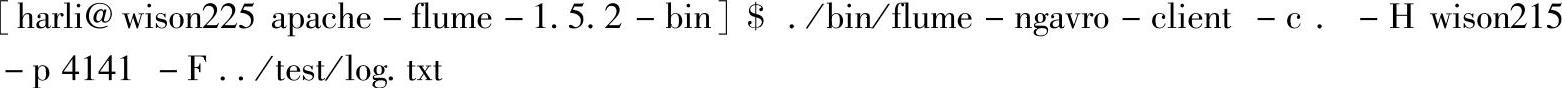
查看Driver的Web Interface界面(http∶//wxx215∶4040)的Streaming页面,如图4.45所示。
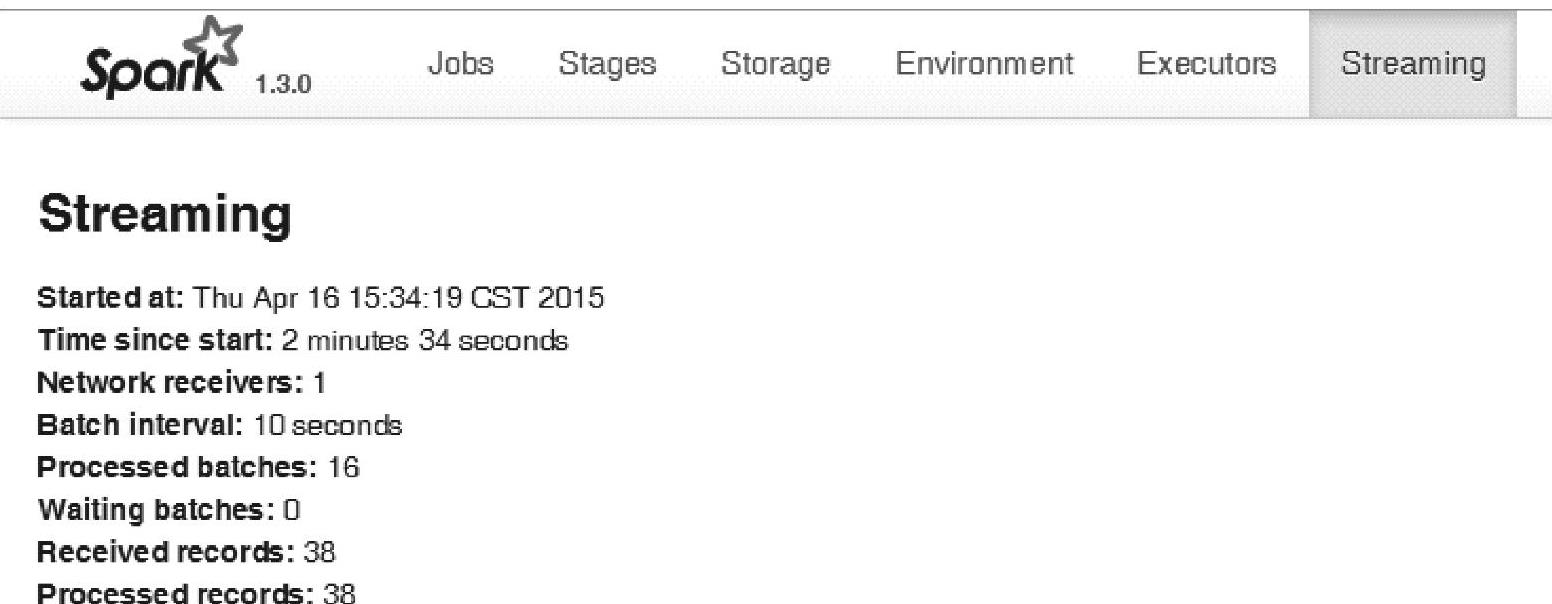
图4.45 Spark Streaming的Streaming页面
以上是定制Sink在单Receiver的使用场景,下面给出定制Sink在两种场景下,Flume的配置及相应代码的案例实践与解析,注意拉取方式下定制Sink的host:port的设置,参考单Receiver案例即可。这里采用单机方式进行案例实践,此时,需要注意的是,要通过port来区分不同的Source、Channel、Sink。
(四)共享Channel场景下的多并行度的应用程序案例与解析
在实际企业级应用场景下,为了提高接收数据的并行度,需要相应的增加推送数据的Sink配置。需要注意的是,Flume在推送数据时,是在Sink推送后,就清除掉Channel里的数据,因此,如果两个Sink关联到同一个Channel的话,实际推送时,就相当于队列分发模式列。下面如测试这种情况。
这里在自己的集群(仅Cluster01节点的分布式集群)上测试,配置文件c2Spark.conf如下:

注意:这里sparkSink2的配置和sparkSink基本一样,和sparkSink使用了相同的channel-c2,唯一不同的地方在于port的设置(这是因为当前在一台机器上)。
启动Flume Agent:

启动过程中,虽然配置文件中两个Sink关联到了同一个Channel,但启动不会报错或警告。
打开两个终端,启动两个Spark Streaming应用:

查看Master的Web Interface界面(http∶//cluster01∶8080/),如图4.46所示。可以看到同时运行了两个Spark streaming应用程序。
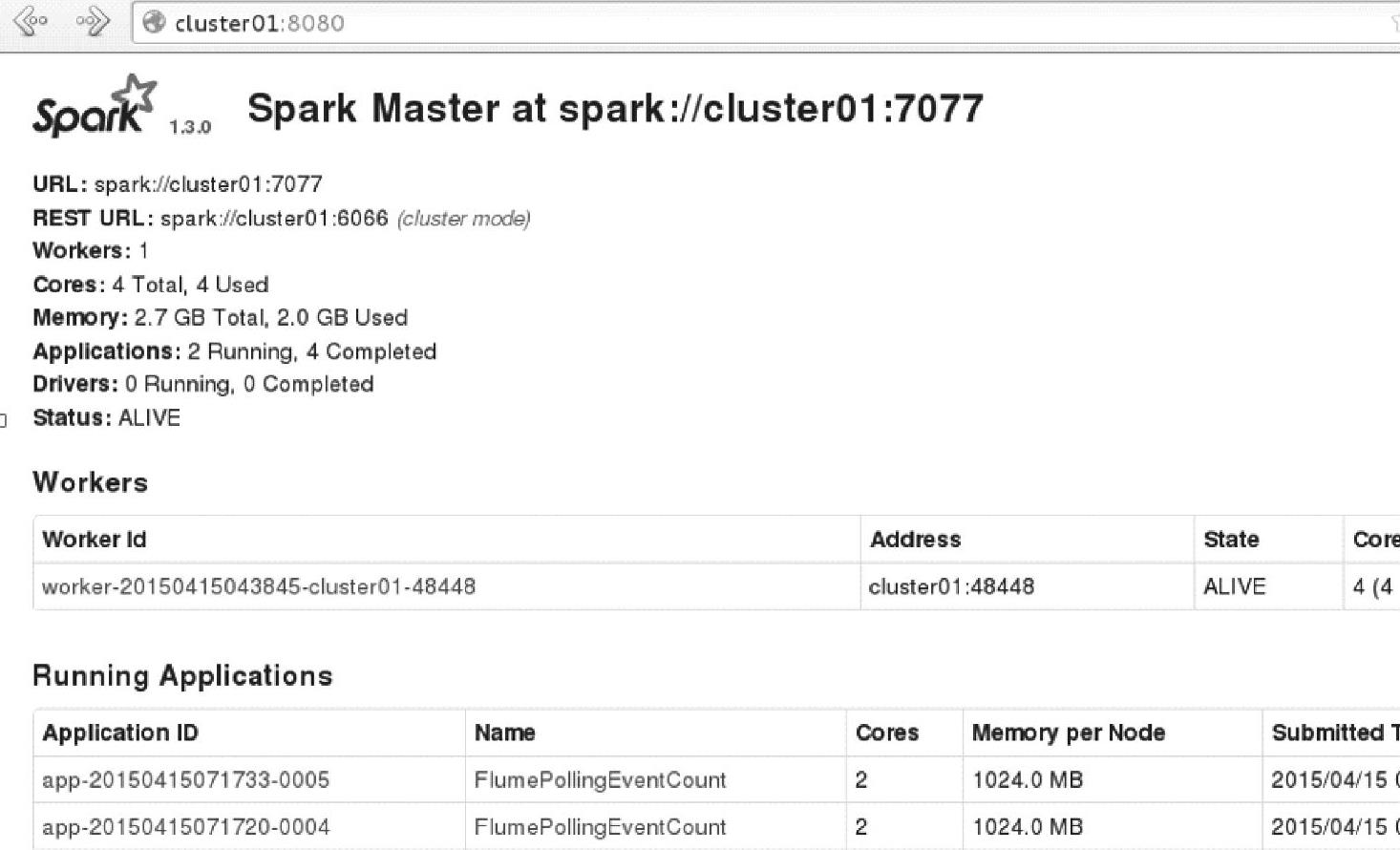
图4.46 Spark Streaming的应用信息
各自单击应用程序的名字,进入Spark Streaming应用的Driver的Web Interface界面,打开Streaming页面,如图4.47所示。持续一段时间后,Streaming页面信息的变更为如图4.48所示。
两个Spark Streaming应用程序都收到了从Channel-c2上拉取过来的数据。
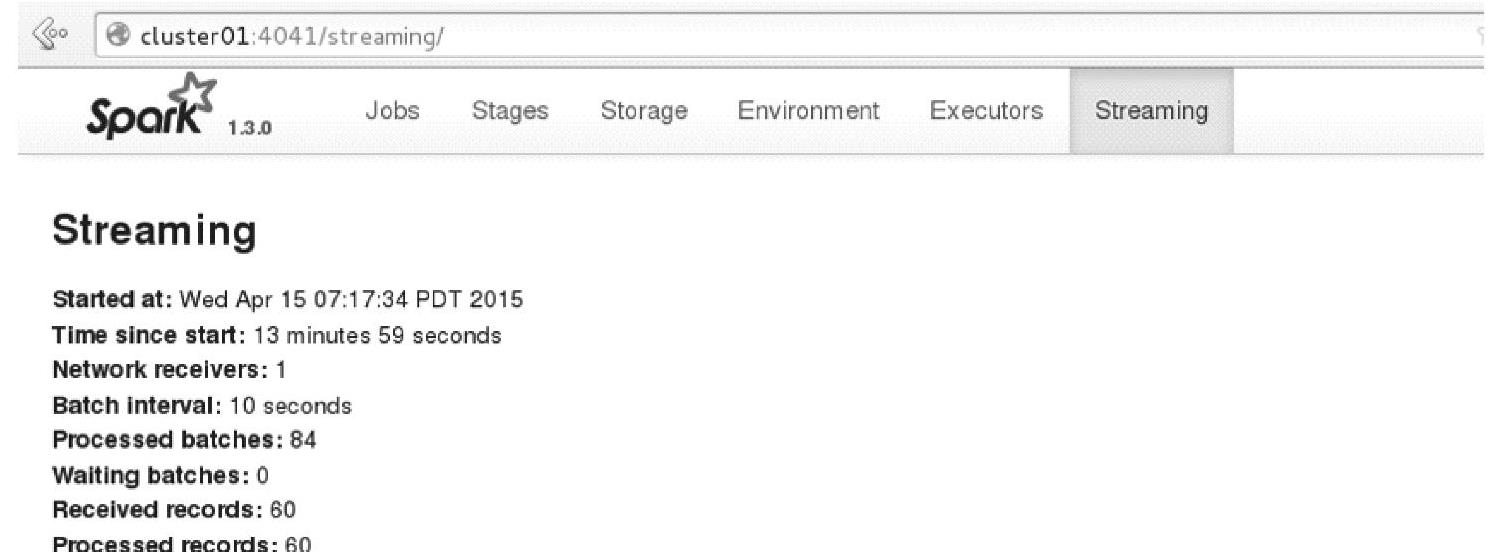
图4.47 Spark Streaming的应用的Streaming页面信息
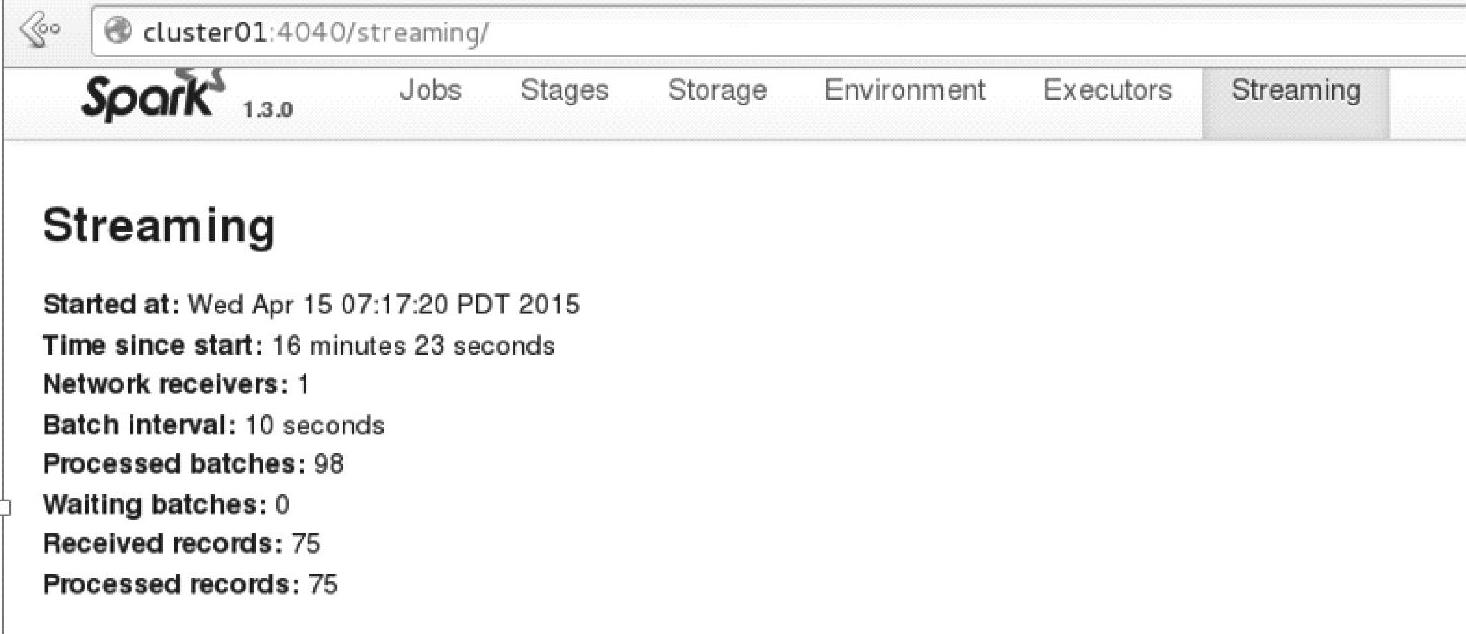
图4.48 一段时间后Streaming页面信息的变更
(五)Sink与Channel一对一场景下的多并行度的应用程序案例与解析
一般情况下,为了提高集群的资源使用率。应用程序的性能等,都需要同时启动多个Receivers,增加数据接收的并行度,下面在单Receiver基础上给出新增一个Receiver的案例及分析。
还可以更进一步,即在一个Agent上添加一个新的Resource,从整条数据流上增加并行度,在方法上一样的。这里为了简化,只简单添加新的Sink和Channel。
当然,企业级别在实际应用时,可以为各个数据源都配置一个Agent来收集数据,只要将配置文件复制过去,然后启动Agent即可。
Flume的配置multispark.conf:


配置文件中,增加了一个新的Sink-sparkSink2,和新的channel-c3,并将这两者关联起来。
应用程序代码:


启动应用命令如下:

参数cluster01∶4142 cluster01∶4143对应两个SparkSink设置的hostname和port信息。在刚开始启动时,会多次尝试连接,这时候连接失败的信息可以忽略。
然后启动Flume avro-client客户端,发送数据:
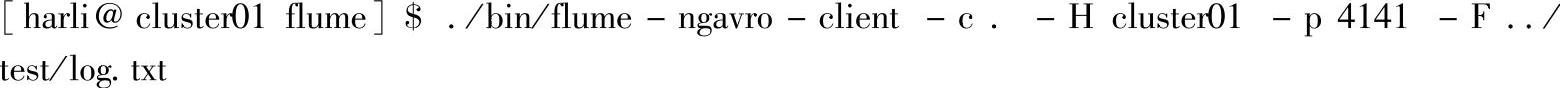
打开查看Driver的Web Interface界面(http∶//clulster01:4040),查看Streaming页面信息,如图4.49所示。
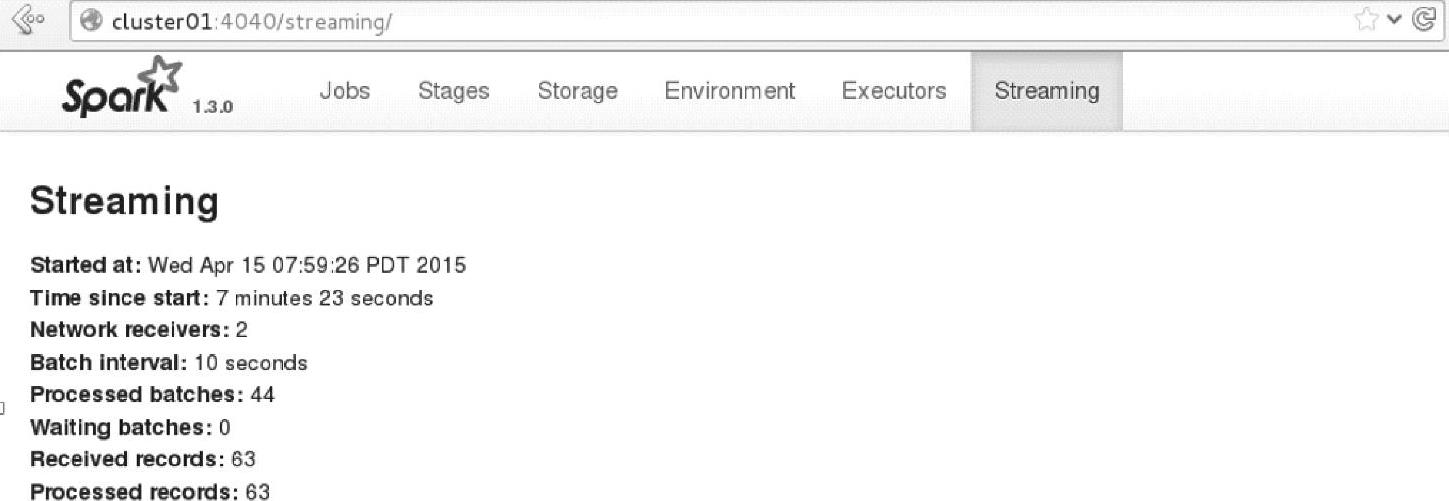
图4.49 Spark Streaming应用的Streaming页面信息
可以看到已经接收并处理列63条记录信息。
在多次快速启动Flume avro-client客户端,发送数据后,发现应用程序接收不到数据,这时,查看对应的Agent的输出日志,会发现如下报错信息:

从界面日志信息中可以看出,由于当前Channel设置的MemoryTransaction太小,空间已满,导致无法接收数据。在企业级实际应用中,需要根据实际情况设置足够的Channel空间(这里是使用内存进行缓存,还可以使用其他方式,具体参考Flume的官方文档说明)。
需要注意的是,在出现以上错误之后,Spark Streaming就不能继续接收数据了,本机测试时,即使重启Spark Streaming应用,也不能继续使用。对应的Agent的Sink-k1,即con-sole输出部分,还能正常运行。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。