



在Spark 1.3中,针对Kafka数据源引入的新的不借助Receiver,而采用直接读取数据的方法,这个方法具有更强的端到端的保证。当启动处理数据的Jobs时,Kafka底层的Con-sumer API会根据定义的offset范围从Kafka中读取数据。方法中通过周期性地查询每个“Topic+Partition”的最新offsets,以及设置的offset范围,来获取批数据,进行处理。当前这一试验性的方法只在Spark 1.3的Scala和Java API中提供。
虽然,在Spark 1.2版本中,Spark Streaming引入了WAL,但是,如果WAL已经写成功了,但还没及时更新Zookeeper中的Kafka偏移量时,而Kafka是根据Zookeeper中记录的Consumer当前的offset来发送数据的,所以当系统出现故障时,还是会导致某些数据重复处理。
根本原因在于Spark Streaming的WAL操作和Zookeeper中的offset更新并不是一个原子性的操作,并不能保证Spark Streaming和Zookeeper中记录的数据offset的一致性。因此在Spark 1.3引入了Direct API概念,它可以在不使用WAL的情况下实现仅处理一次的语义(exactly-once semantics)。Direct API直接使用Kafka的低层次API,指定要读取的offset。因此,真正使用的offset是由Spark Streaming通过Checkpoints来维护的,只在一个地方维护offset,就不会出现不一致的问题了。
一、案例实践的准备
一般在企业中,会对一些日志信息、网络异常事件信息等进行统计,本案例针对这些信息,通过Kafka发送到Spark Streaming,以关键字ERROR作为特征值,统计流持续的异常信息的条数,用两种不同的方式,统计从Kafka获取的数据的单词数量。
这里给出应用代码以及两种offset获取方式的实践案例与分析。
应用代码的如下:



这里为了测试方便,将流的批数据时间片设成了10秒。
在另一个终端或节点上,启动Producer,对应脚本如下(或者用前面的start-producer.sh):
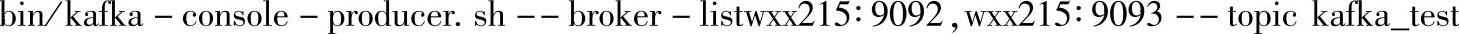
在Producer生产者界面上输入以下日志信息:


这是从Kafka日志里截取的一段,将INFO信息替换为ERROR进行测试。实际企业环境中,可以通过Flume-ng收集日志信息,存入Kafka,也可以自己编写Kafka的Producer客户端,向Kafka指定Topic发送消息等。
二、从Topic最新的offset开始读取数据的案例与分析
通过设置Kafka的参数为:
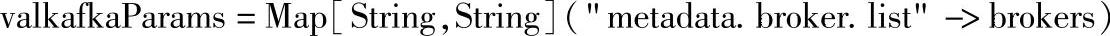
准备好日志数据之后,开始启动作为启动生产者的脚本:
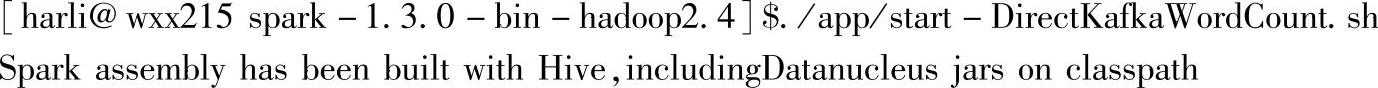
界面每隔时间片长度10秒时间就打印一次统计信息,第一次10秒的统计信息如下:


生产者界面一次输入包含10条ERROR的日志信息,可以看到,过滤ERROR并持续统计的结果是当前流一共有10条信息包含ERROR信息。
后面两个统计结果,只是使用了不同的方法实现相同的单词统计功能,因此显示的统计结果是一样的。
再次向生产者输入信息,这次先输入包含9条ERROR的日志信息,可以看到,过滤ERROR并持续统计的结果,是流数据的前一次统计状态值(10条ERROR信息),加上新增的9条,一共包含19条ERROR的信息,信息如下:


对应的最后一行数据在生产者界面输入后,对应的统计为:

可以从单词统计中新增的ERROR单词数(这里日志的一条信息中只出现一次ER-ROR),推出第一个统计结果确实保留了流数据的状态信息。
三、重置offset,从Topic最老的offset开始读取数据的案例与分析
只需要在创建Kafka流时,将Kafka的参数metadata.broker.list设置为smallest,就可以从Kafka中缓存的最早的数据开始读取。
通过设置Kafka的参数为:(https://www.xing528.com)
//修改这里添加一个Kafka的属性配置,设置后,会重置offset,也就是会从Kafka那从头开始读取数据
//val kafkaParams=Map[String,String]("metadata.broker.list"->brokers,"auto.offset.reset"->"
smallest")
这里将注释去掉,同时注释掉上面一行的kafkaParams设置,然后启动应用,这时候不需要再在Producer生产者界面中输入任何信息,因为Kafka已经缓存了一批数据(默认缓存时间为7天)。
启动脚本:

每次启动后都会从Kafka的缓存中从头开始读取数据。对应界面提示信息中有:

这是第一、二次启动脚本时的输出,每次都是从当前Kafka的缓存中重新读取,因此统计数据是一样的。


这里再在Kafka生产者界面输入10条包含ERROR的消息,然后重新启动,预期结果应该仅仅将ERROR的状态计数统计更新为:(ERROR,68+10)

如上面的(ERROR,78)就是预期的结果。
四、深入状态更新函数的源码解析
Spark Streaming API中比较难理解的除了窗口类型的API之外,还有一个就是状态更新类型的API。
这里从最简单的状态更新类型的API开始分析,案例中给出了两个API的实例,调用代码如下:

这两者是一样的,为了更深入理解updateStateByKey,先详细分析updateErrorCount和newUpdateFunc两个函数。分析函数有个比较简单的方法,可以启动Scala运行环境,然后直接将函数定义复制进去,这时候就可以看到交互式界面反馈的详细信息了,步骤如下:
首先要在本地安装Scala环境,具体安装方法可以从网上搜下,这里以Windows 7下为例,启动Windows下的command窗口,如图4.37所示。
图4.37 启动Windows下的command窗口
打开command窗口后,输入scala,按<Enter>键后出现scala交互式界面,如图4.38所示。

图4.38 启动Windows下scala交互式界面
然后将代码复制进去,交互式界面的反馈信息如下:

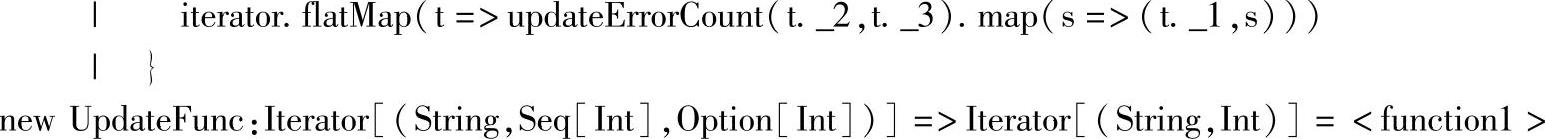
这里,函数字面量newUpdateFunc的类型是一个<function1>,即带一个参数的Func-tion类,输入参数的类型为Iterator[(String,Seq[Int],Option[Int])],返回类型为Iterator[(String,Int)]。输入参数中,String参数对应的是Key,Seq[Int]对应的是Value序列,Op-tion[Int]对应的是历史状态值;返回类型中的String对应Key,而Int则是对应Key更新后的新的状态值。
接下来分析updateStateByKey方法的源码:

调用代码updateStateByKey(updateErrorCount),这是最简单的状态更新API方式,只需要提供Value序列值和历史状态信息,就可得到新的状态信息的处理结果。内部使用的分区器是默认分区器,实际上就是new HashPartitioner(ssc.sparkContext.defaultParallelism)构建的分区器,这部分可以参考章节2.2.9分区数设置的案例与源码解析部分。最终在各种默认参数被设置后,就到了第二个API,及调用updateStateByKey[Int](newUpdateFunc,new Hash-Partitioner(ssc.sparkContext.defaultParallelism),true,initialRDD)方法。最终构建了StageD-Stream实例:

到此状态,更新类的API源码解析结束。对应构建的StateDStream源码解析可以参考前面的WindowedDStream源码解析。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。