



基于Receiver读取的方法,使用了一个Receiver来获取数据,使用Kafka的高层次API实现了数据接收。在所有的Receivers中,通过一个Receiver从Kafka接收数据,并存入Spark Executors,在Spark Streaming处理数据时提交jobs。
由于使用了Kafka的高层次API,数据读取的offset信息由Spark负责管理,一旦处理失败将会丢失数据,因此Spark Streaming引入了WAL(Write Ahead Logs),用于保存offset信息,在失败时,重新读取offset信息,开始读取数据。
从高层次的角度看,之前的和Kafka集成方案使用WAL工作方式如下:
1)运行在Spark Workers/Executors上的Kafka Receivers连续不断地从Kafka中读取数据,其中用到了Kafka中高层次的消费者API。
2)接收到的数据被存储在Spark Workers/Executors的内存中,同时也被写入到WAL中。只有接收到的数据被持久化到Log中,Kafka Receivers才会去更新Zookeeper中Kafka的偏移量。
3)接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。
一、应用程序准备
这里以Spark提供的example案例作为基础,进行案例实践分析,代码如下:


KafkaUtils.createStream通过源码查看的话,可以看到内部默认设置了一些参数,

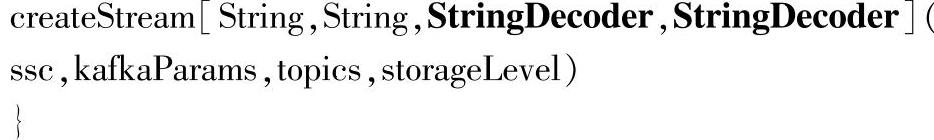
这里默认使用的存储级别为StorageLevel.MEMORY_AND_DISK_SER_2,通过辅助来提供容错性,和RDD的默认存储级别不同;默认用于序列化的解码类为StringDecoder,和KafkaWordCountProducer发送消息时的编码类是一样的。
注意:收发双方的编码应保持一致,避免出现乱码,有特殊需求时,可以自定义编解码的类。
二、无WAL的案例测试
启动Producer脚本start-producer.sh和Consumer脚本:start-consumer.sh。
当代码为:val wordCounts=words.map(x=>(x,1L)).reduceByKeyAndWindow(_+_,_-_,Minutes(10),Seconds(2),2)时,在start-consumer.sh启动终端,每隔2秒就统计前10分钟的单词统计信息,其中10分钟为窗口长度,2秒为批数据时间间隔。
下面是其中的一部分输出(当前仅一个Consumer,分组为:Group 1,Topic及其分区数为Kafka_test-4 partitions):


为了深入分析reduceByKeyAndWindow方法的作用,这里使用Kafka自带的console的Producer来提供数据,对应执行命令为:
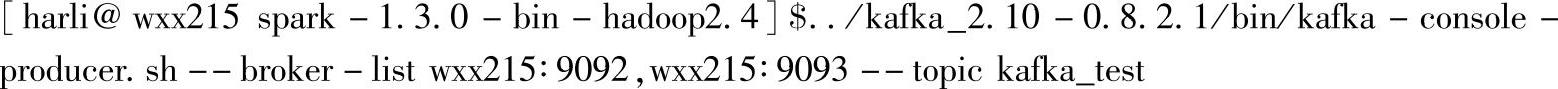
测试滑动长度与输出的关系,使用的代码:val wordCounts=words.map(x=>(x,1L)).reduceByKeyAndWindow(_+_,_-_,Minutes(5),Minutes(3),2),即修改了时间,窗口长度为5分钟,滑动时间间隔为3分钟,对应的测试结果:
Consumer的启动时间是28分钟11秒,打印时间整理见表4.1。
表4.1 打印结果的时间表

这里可以看到reduceByKeyAndWindow方法,滑动长度的Minutes(3)值,对应了窗口数据统计的频率。对应的窗口长度,也可以通过这种方式去测试。把后一次的打印时间减去上一次的打印时间就是对应滑块长度Minutes(3),也就是窗口数据统计的频率。
这是Consumer界面对应的输出信息:


可以看到,前面在Producer界面输入数据后,每隔滑动时间3分钟就统计一次前窗口长度5分钟的单词信息,到后面,Producer不再输入数据,统计信息也就变成了0。
在实时流处理中,窗口的概念是很重要的,经过上面这种人为地控制输入数据的测试,这里进一步对reduceByKeyAndWindow方法进行详细分析。
reduceByKeyAndWindow有两个重载方法,如下面两种样例:
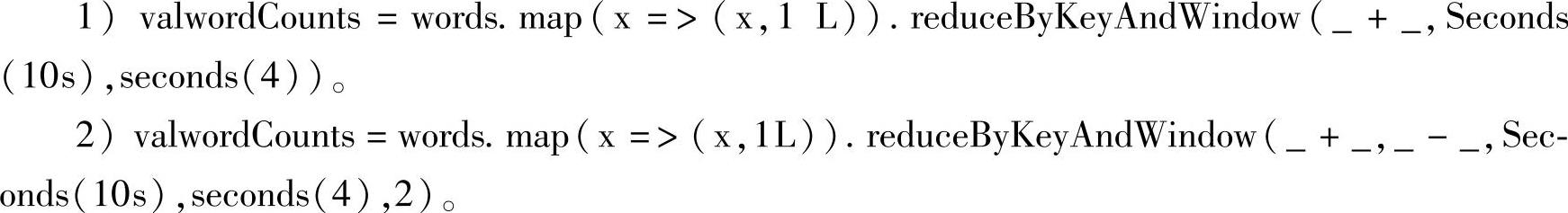
以KafkaWordCount这个Consumer为例,上面样例对应的窗口操作可以理解成,每隔4秒的时间,统计一次过去10秒的时间内的所有输入数据的单词统计信息。这里的窗口长度Seconds(10s),表示统计的范围,滑动时间间隔seconds(4)表示每隔4秒就开始统计一次。
这是官方网站上对窗口方法相关概念的图形描述,这里在原图上加了一些细节说明,如图4.34所示。这些说明中的一些概念可以参考章节4.2 Spark Streaming基础概念部分。
两个长方形框,描述一个窗口信息,其中包含了3个时间片的批数据,对应的时间跨度就是“3乘时间片”;滑动时间间隔,是指从第一个窗口滑动(沿着时间流方向前进)到第二个窗口时,经过的时间片,由于是2个时间片,对应的滑动时间间隔就是“2乘时间片”。
reduceByKeyAndWindow方法也是窗口方法之一,其他的窗口方法,在理解窗口长度和滑动时间间隔之后都比较好理解,这里针对相对复杂的reduceByKeyAndWindow方法进行深入分析,加强对窗口类方法的理解。
这里通过图形来描述reduceByKeyAndWindow的重载方法的异同点,如图4.35所示。
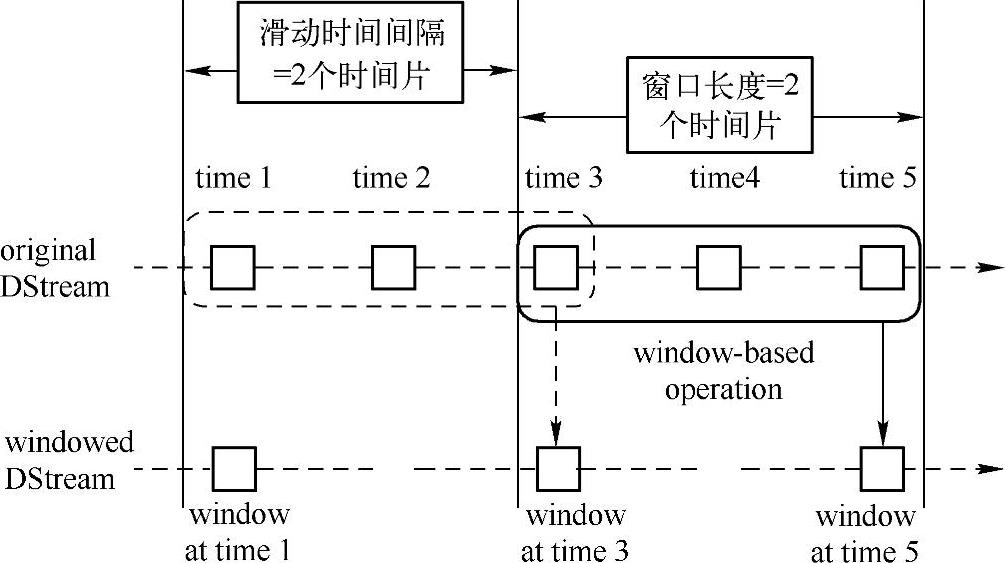
图4.34 窗口长度与滑动时间间隔图
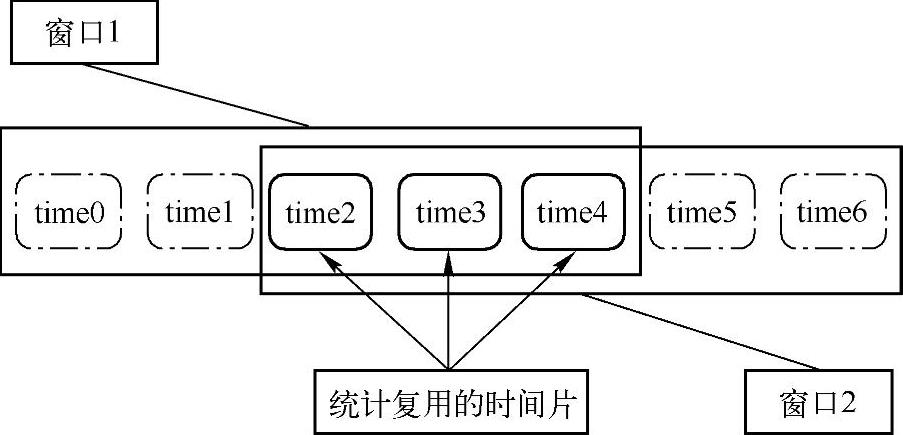
图4.35 reduceByKeyAndWindow方法描述图
对应的方法调用为reduceByKeyAndWindow(_+_,Seconds(5s),seconds(2))。该方法在Scala API官方网站上的定义如下:
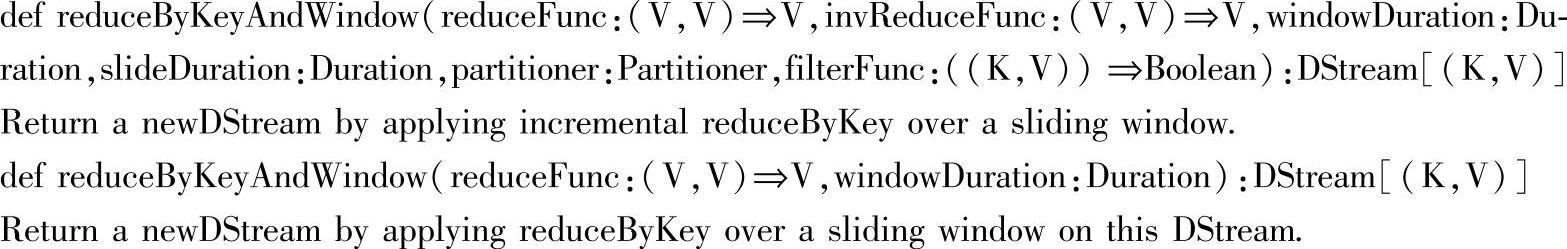
其他的重载方法只是细节上的差异,这里不做具体分析。下面开始分析该API。
1.def reduceByKeyAndWindow(reduceFunc:(V,V)⇒V,windowDuration…
以reduceFunc:(V,V)中V为“_+_”为例进行分析。
该方法只是根据滑动时间间隔,对窗口长度内的时间片数据进行reduceFunc统计,对应的结果如下。
1)窗口1的统计结果:win1=time0+time1+time2+time3+time4
2)窗口2的统计结果:win2=time2+time3+time4+time5+time6
在图4.35中,对应为简单地各自统计自己的5个时间片的数据。
2.def reduceByKeyAndWindow(reduceFunc:(V,V)⇒V,invReduceFunc:(V,V),windowDu-ration…
以reduceFunc:(V,V)中V为“_+_”,invReduceFunc:(V,V)中V为“_-_”为例进行分析。
该方法复用了两个窗口中,时间片的交集部分的统计结果,即图中的时间片交集为time2,time3,time4,因此进行reduce时,复用了这三个时间片的结果,对应的结果可以表示为:(https://www.xing528.com)
1)窗口1的统计结果:win1=time0+time1+time2+time3+time4
2)窗口2的统计结果:win2=win1+time5+time6-time0-time1
即,窗口2的统计是在窗口1的统计基础上,加上新增的时间片,同时减去移出的时间片。
根据上面的分析,我们可以知道,reduceFunc和invReduceFunc这两个方法必须是互逆的,像“_+_”和“_-_”是互逆操作一样。
同时,还可以看出,当滑动时间间隔远小于窗口长度时,前后两个窗口的时间片交集就越多,因此使用第二种方法可以复用更多的时间片的统计结果,对应的性能也就更高了。如果滑动时间间隔等于或大于窗口长度时,由于没有可复用的时间片统计,这时候直接使用第一种方法就可以了。
三、窗口方法的源码解析
在DStream类中提供了window的方法,通过查看该方法的源码,进一步解析窗口操作。

查看各种窗口相关的API,基本上都是间接或直接调用了window的方法。
因此,通过对window方法,也就是对WindowedDStream类的深入源码解析,可以了解窗口操作的具体实现细节。
主构造函数:

这里父依赖DStream为传入的DStream,在主构造函数体内:


这里在构造WindowedDStream实例时,就对窗口长度和滑动时间间隔做了检查,两者都必须是parent.slideDuration的倍数,parent.slideDuration对应的就是DStream的slideDuration属性,查看源码可知,该属性即时间片的时间值,DStream类中该属性的源码如下:
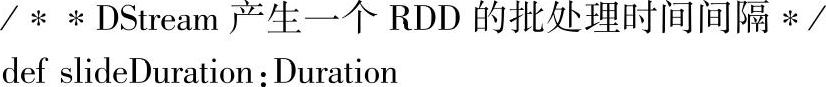
对外部数据源来说,slideDuration就是我们设置的批处理的时间间隔,每持续slideDura-tion时间,就开始构建一个RDD。对应的WindowedDStream,是每隔一个滑动时间间隔构建一个RDD,slideDuration就是窗口操作中的滑动时间间隔。虽然都是每隔slideDuration间隔就构建一个RDD,但普通的DStream构建的RDD的数据是在一个slideDuration间隔内的,而如果是WindowedDStream的话,RDD包含的数据是windowDuration间隔内的。
总之,slideDuration是控制RDD构建频率的时间间隔。windowDuration是控制RDD数据对应的时间长度。同时,普通DStream的windowDuration(实际上没有这个属性)等于slide-Duration,即等于时间片大小。
下面这两个属性用于控制内存中持久化时,数据保留的时间:
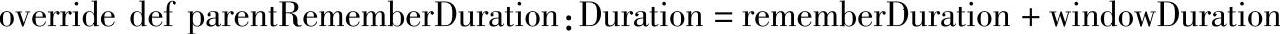
其中rememberDuration为DStream属性:
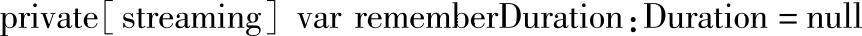
最后,最关键的一个方法是compute方法,对应源码为:

其中:
1)val currentWindow=new Interval(validTime-windowDuration+parent.slideDuration,validTime):parent.slideDuration是构建RDD对应的时间,“validTime-windowDuration”是计算回退windowDuration(窗口长度)的时间长度,为了和validTime一样,需要调整Interval的起始点,如图4.36所示。
2)val rddsInWindow=parent.slice(currentWindow):parent即DStream,slice方法构建对应currentWindow这个时间范围的RDD。
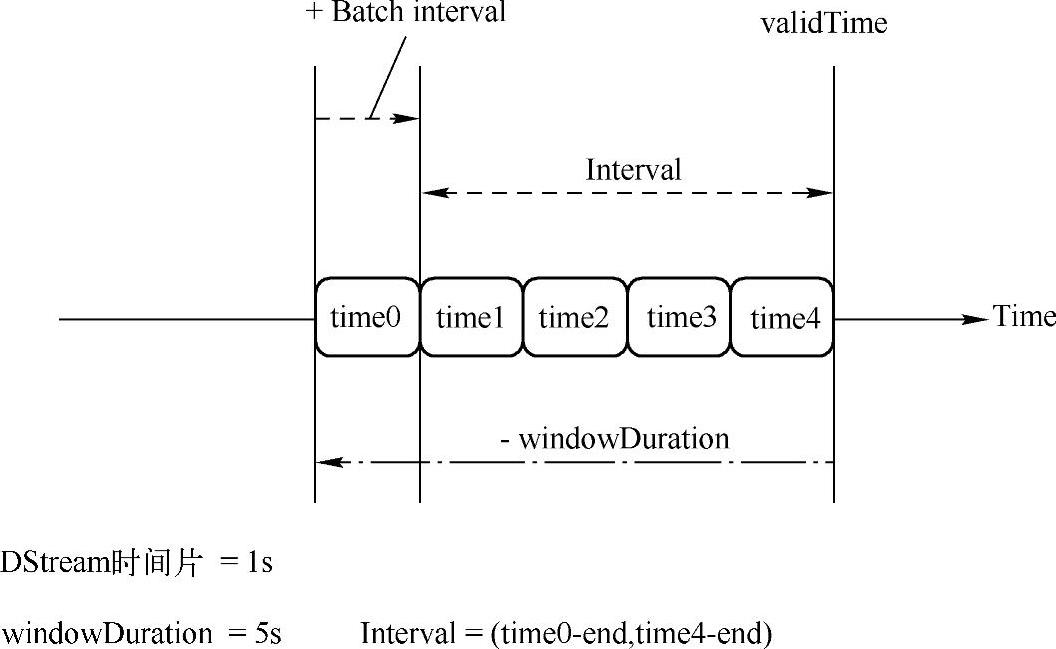
图4.36 窗口操作中的Interval计算
3)最后通过UnionRDD操作将得到的RDD集合进行合并(RDD实例是和时间片一一对应的,因此slice得到的应该是多个时间片的RDD的集合)。
由UnionRDD操作我们可以推导出,最终合并后的RDD的分区数将是批数据时间片对应的RDD的分区数的sum(求和)值。因此,当分区数据量不是很大时,在进行窗口类型的操作时,可以优先考虑使用带分区设置参数的重载方法。相应的,内存中存储的RDD就应该足够装载指定窗口长度的对应数据量了。
底层的RDD是对应一个时间片的批数据的,对应的分区数应该是由该时间片内的数据设置。由于底层的参数Spark.streaming.blockInterval用于控制接收数据块的最小单位的时间,所以这个最小单位时间对应接收到的数据应该就是RDD中的block。也就是说,batch-Interval/blockInterval就是对应的RDD的分区数了。
比如,当前流的时间片设置为2秒时,由于参数Spark.streaming.blockInterval默认为200毫秒,因此对应的RDD的分区数是10。
四、启动WAL的案例解析
为了避免在数据处理过程中出现故障而导致的数据丢失问题,在Spark 1.2中Spark Streaming引入了WAL,用于保存offset信息,在失败时,可以通过重新加载offset信息,读取处理故障的数据,避免数据丢失。
启动WAL只需要配置属性“Spark.streaming.receiver.writeAheadLog.enable”,将默认的false修改为true即可。
该配置设置为true后,从一个Receiver接受的所有数据都会写入配置的Checkpoint目录中的一个预写日志(a write ahead log)中(可以参考HBase中的WAL)。使用WAL可以避免在Driver恢复后的数据丢失问题,可以确保零数据丢失。由于增加了数据的预写日志,所以启动WAL不可避免地会降低每个Receiver的吞吐量。在实际应用时,我们可以通过使用更多的Receiver来并行接收数据,以提高整体的吞吐量。
在上面的源码分析中,我们已经看到了流的创建,对应创建创建流的源码如下:
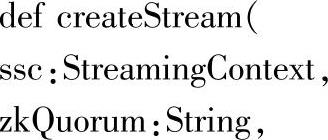
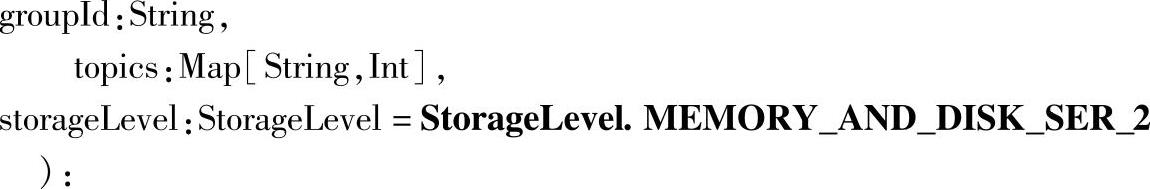
创建流时,默认的StorageLevel为StorageLevel.MEMORY_AND_DISK_SER_2,这里的_2用于对数据进行备份,保证容错性,如果我们启动了WAL,数据会自动备份到存储系统上。这时候可以将input stream默认的存储级别修改为StorageLevel.MEMORY_AND_DISK_SER,即内部的数据存储不需要再进行数据备份了。
WAL的启用,只需要修改一个配置,而同时在代码中构建流时,需修改默认的存储级别。修改配置属性可以在Spark-defaults.conf中增加以下一行内容:
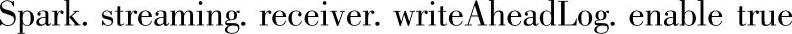
注意:由于WAL要将数据存储到Checkpoint目录下,代码中也要调用streamingContext.checkpoint()来设置Checkpoint目录才可以。
这里有一个细节需要注意,即Driver失败后重启部分,如果是Spark on Yarn模式的话,由Yarn负责重启Driver,即ApplicationsMaster;如果是在Standalone模式下开启Driver失败时启动的话,可以查看spark-shell或spark-submit的帮助信息,即将Driver失败时重启的选项打开即可,如下所示:

在启动交互式或直接提交应用时,加上--supervise就可以让Driver在失败时重启了,需要注意的是,这是在“Standalone+Cluster”模式下才有效的。
注意:WAL在Spark 1.3版本中,Flume部分在内部测试出现了回退现象,这部分已经提交了PR,具体内容可以参考Spark 1.3.1版本的release说明。
由于本书重点内容在案例与解析部分,属性配置等相关内容介绍的不多,具体可以参考官方网站的配置页(http://Spark.apache.org/docs/latest/configuration.html)。
常见问题与分析:在使用Receiver接收数据的流处理中,有时候会碰到无法接收数据的现象,这时可以先从两个方面初步排查问题:
1)发布消息时,是否使用了队列模式的消息发布模式,这时候在某个Consumer上会表现为数据丢失等现象。
2)任何一个使用了Receiver的流处理,都需要注意一点,每个Receiver本身就会占用一个内核,如果没有分配足够的内核的话,就无法启动数据处理,表面上就像是没有接收到数据一样,实际上是没有启动数据处理任务。如果是local模式的话,对应地设置足够的N(local[N]),如果是集群模式,对应的Executor(一个Executor对应一个Receiver)需要设置足够的内核个数。
Kafka相关问题的分析与排查等,可以借助Spark应用程序的Web Interface界面上新增的Streaming页面,也可以借助第三方工具,如ApacheKafka监控系列KafkaOffsetMonitor开源项目,可以用来监控Kafka的Consumer相关信息,来帮助分析与排查Kafka相关问题。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。