



除了Sockets,StreamingContext API还提供了从其他基础数据源创建DStream实例的方法,这里以文件数据源作为例子,解析文件流的处理,并在此基础上,引入Spark SQL,结合Spark Streaming和Spark SQL给出案例。
当企业的数据从各种数据源获取后,存入某个文件存储系统时(一般使用HDFS),比如将从Flume数据源收集来的日志文件存入HDFS文件系统等,可以使用文件流的方式去处理,该方法可以监控某一目录下的创建文件,并对文件进行处理。
案例中以手动构建文件,并移入监控目录来简化外部数据源存入该目录。实际在企业中应用时,应该引入类似Flume等日志聚合系统负责数据收集。
这里换一种方式执行应用,即在IDEA中运行应用程序,使用local方式运行,这种方式下,可以方便代码的调试。
具体代码如下:


打开配置Run的窗口,如图4.31所示。

图4.31 IDEA的应用的Run配置
进入Run配置的编辑界面,如图4.32所示。

图4.32 IDEA的应用的Run配置的编辑菜单
输入具体配置信息,如图4.33所示。
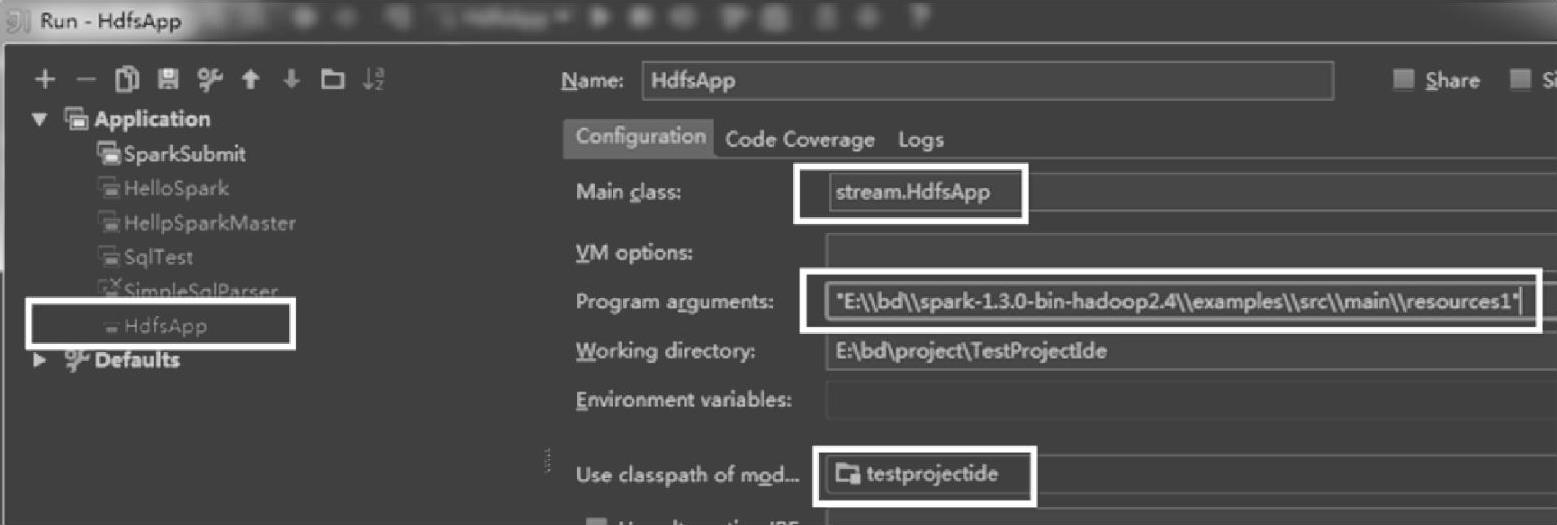
图4.33 IDEA的应用的Run配置的编辑界面
其中,在Program arguments部分,添加监控的路径,这里设置为本地文件系统下的监控目录“E∶\\bd\\spark-1.3.0-bin-hadoop2.4\\examples\\src\\main\\resources1”由于不是集群模式提交,因此Main class部分可以设置为当前的应用类,需要使用类的全路径。(https://www.xing528.com)
单击窗口的Run按钮,启动流处理。然后,手动将文件添加到监控目录下。
注意:
1.监控目录下的文件应该有一样的数据格式,避免在内部解析时报错。
2.文件必须是在监控目录下创建,可以通过原子性的移动或重命名操作,放入目录。
3.一旦移入目录,文件就不能再修改了,如果文件是持续写入的话,新的数据是无法读取的。
案例中,必须在启动后新建一个文件,然后移入目录,创建时间比启动早的文件,移入目录时不会处理。
案例中,使用的文件内容源自:E∶\bd\spark-1.3.0-bin-hadoop2.4\examples\src main\resources\kv1.txt,即Spark自带的kv文件。由于没有安装HDFS,所以默认的是本地文件系统,不需要添加file∶//的scheme信息。对应在HDFS系统上时,可以增加hdfs://的scheme信息。
输出结果为:

Spark 1.3版本中,增加了EmptyRDD的定义,用于源数据输入为空时构建的RDD,这里的代码,添加了EmptyRDD的判断,即if(!rdd.isEmpty()){…},通过判断RDD是否为空,来过滤空数据,从而避免相应的job提交。添加判断后,输出界面会像上面那样,只有收到数据时,才会提交job,进行处理。
如果没有添加该判断的话,代码会一直提交任务,但没有执行具体的数据处理,对应的界面如下:

另外,在代码中,MasterURL使用的是.setMaster("local[1]"),因为文件流不需要Receiver,也就不需要额外占用一个内核。
之前在spark-shell提交应用的方式下提到过spark-shell交互式中已经自动导入了SQLContext的隐式导入,因此不需要再自己添加,但对应的spark-submit方式提交应用时,必须手动在使用的代码中添加“import sqlContext.implicits._”这句隐式转换的导入语句,否则,后续的toDF等调用会编译失败。
在企业级的实时流处理中往往会引入Kafka作为分布式消息系统,以及Flume作为各种数据的收集系统。下面分别给出Spark Streaming整合Kafka的案例与解析,以及整合Flume的案例与解析。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。