



一、准备工程,并构建测试类
(一)基于IDEA构建应用程序
在第2章构建的工程基础上,参考章节2.4.2基于IDEA构建Spark应用程序的实例部分,继续添加依赖包,如图4.5所示。

图4.5 IDEA中的Project Structure…选项
在IDEA中添加依赖包,如图4.6所示。

图4.6 IDEA中添加的依赖包
这里我们基于examples提供的NetworkWordCount类来实践TCP流数据的处理,相应的,为Spark-examples-1.3.0-hadoop2.4.0.jar添加源码关联,查找examples中的Network-WordCount类,查找结果如图4.7所示。

图4.7 IDEA中查找NetworkWordCount类
构建自己的package,名为stream,在scala目录下,单击右键打开上下文菜单,依次选择New→Package命令,操作步骤如图4.8所示。
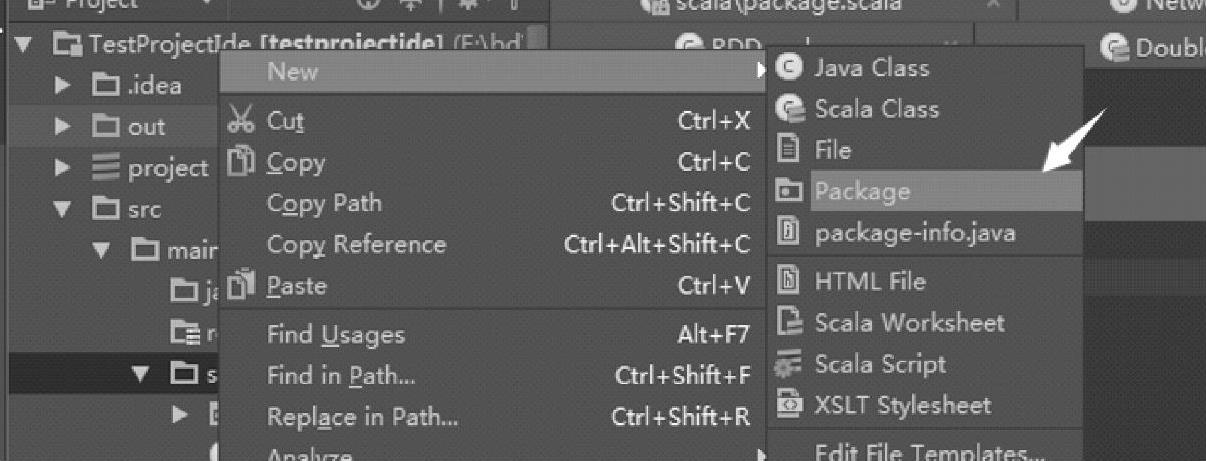
图4.8 IDEA中添加package
输入stream作为package名,单击OK按钮,如图4.9所示。
构建package后的目录结构如图4.10所示。
目录结构中,在stream上单击右键,在弹出窗口中创建一个名为NetworkWordCount的对象,如图4.11所示。
点击OK按钮,复制代码,如图4.12所示。

图4.9 IDEA中设置添加的package名称
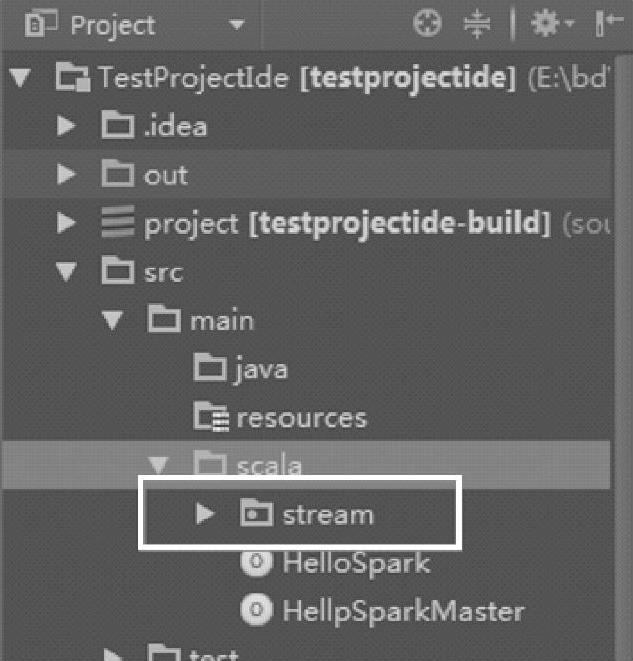
图4.10 IDEA中构建package后的目录结构
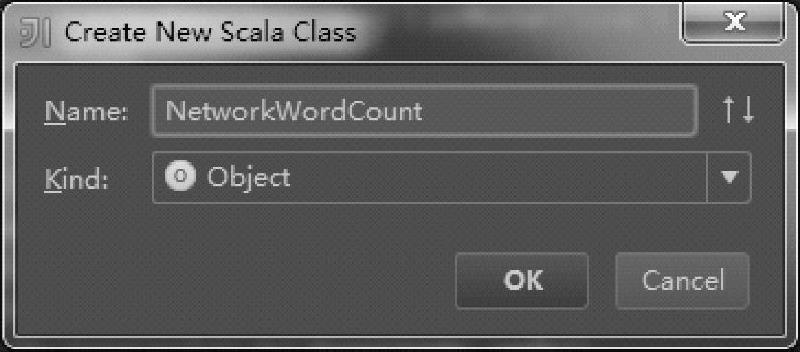
图4.11 IDEA中创建一个NetworkWordCount对象

图4.12 IDEA中复制NetworkWordCount对象的代码
构建应用程序的jar包,如图4.13所示。这里的Artifacts参见章节2.4.2基于IDEA构建Spark应用程序的实例部分。
查看构建的jar包,可以看到已经包含了NetworkWordCount类了,包含内容如图4.14所示。
可以通过WinRAR等解压工具打开jar包进行查看,也可以在命令行中使用jar命令来解压查看,使用方法和tar类似,具体可以查看命令的帮助信息。

图4.13 IDEA中构建应用程序的jar包

图4.14 查看构建的jar包的类
(二)基于SBT构建应用程序在build.sbt文件中添加:

注意:这里添加依赖的语法和前面有点差异,使用的“%%”,同时不需要指定Scala版本,这在比较新的SBT版本中才支持,具体可以参考SBT官方网站。
打开终端,如IDEA中的终端Terminal(也可以打开Windows下的CMD窗口),输入命令“sbt package”,具体操作如图4.15所示。
编译成功的输出信息如图4.16所示。
由于当前使用的Maven仓库中没有对应的Spark-examples的1.3版本的jar包,如图4.17所示。
在SBT编译前修改代码,注释掉//StreamingExamples.setStreamingLogLevels(),或将自己编译得到的jar包放入本地仓库中(可以在编译时加install),或者直接将Spark部署包中的Spark-examples-1.3.0-hadoop2.4.0.jar复制到本地仓库中。SBT打包应用程序可以参考章节2.4.1基于SBT构建Spark应用程序的实例部分。
这里使用IDEA方式构建应用程序,手动将依赖的jar包导入IDEA中,然后构建出应用程序的jar包,StreamingExamples.setStreamingLogLevels()这一行代码在实际测试过程中并不能去除日志信息,所以暂时使用以下代码来替代(可通过日志的配置文件进行修改,但不推荐在生产环境中去除INFO级别的日志):

图4.15 sbt package方式构建jar包
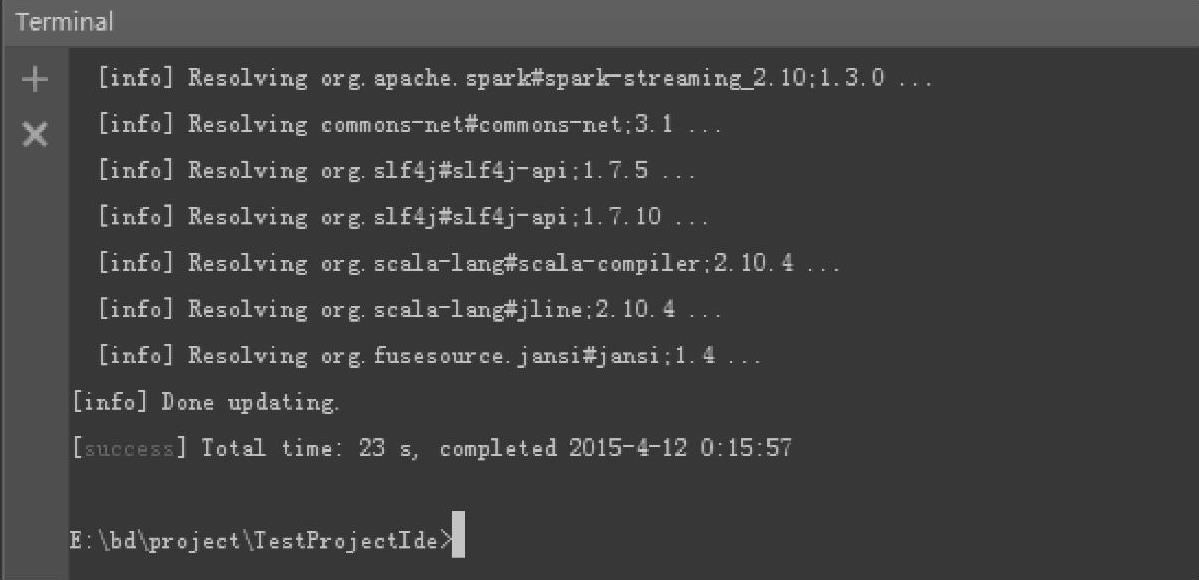
图4.16 sbt package方式构建jar包的结果界面
图4.17 maven仓库中jar包信息
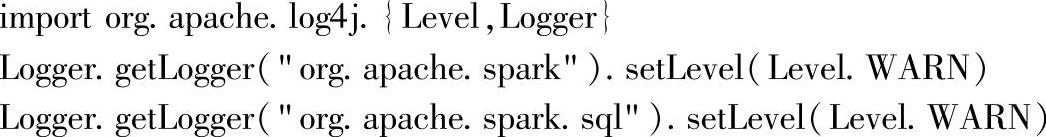

最终的应用程序NetworkWordCount的代码如下:

任何作用在DStream实例上的操作都会转换为对其底层RDD序列的操作,比如,代码中flatMap方法对应的DStream内部操作如图4.18所示。

图4.18 DStream的flatMap方法对应的内部操作
其中,一个框对应一个批数据,即一个RDD实例。
二、开始测试
这里使用cluster01的集群,cluster01对应部署了全部进程,除了集群设备较少之外,其他操作和多节点集群是一样的。
(一)Standalone模式提交
启动Spark集群后,在$Spark_HOME路径下输入:

根据NetworkWordCount应用的使用说明“Usage:NetworkWordCount<hostname><port>”,在spark-submit的最后输入对应的cluster019999,作为应用程序的参数。
需要注意的是,由于NetworkWordCount代码中使用了StreamingExamples类,因此需要将依赖的./lib/spark-examples-1.3.0-hadoop2.4.0.jar作--jars参数传入,否则Executor执行时会找不到StreamingExamples类,错误信息如下:

注意:这里使用spark-examples-1.3.0-hadoop2.4.0.jar主要是为了测试在不同集群模式下,用--jars添加依赖包的有效性(集群中没有将Spark的lib放到Hadoop的CLASSPATH路径下)。
查看界面,如图4.19所示。由于当前虚拟机设置了2个内核,因此该应用占用的内核数为2,刚好可以分配给Executor和接收流的Receiver。
为了方便测试,接下来将cluster01的虚拟机内核数改成4。
打开另一个终端,输入以下命令启动Netcat:

然后将$Spark_HOME路径下的README.md内容复制到该终端界面上。
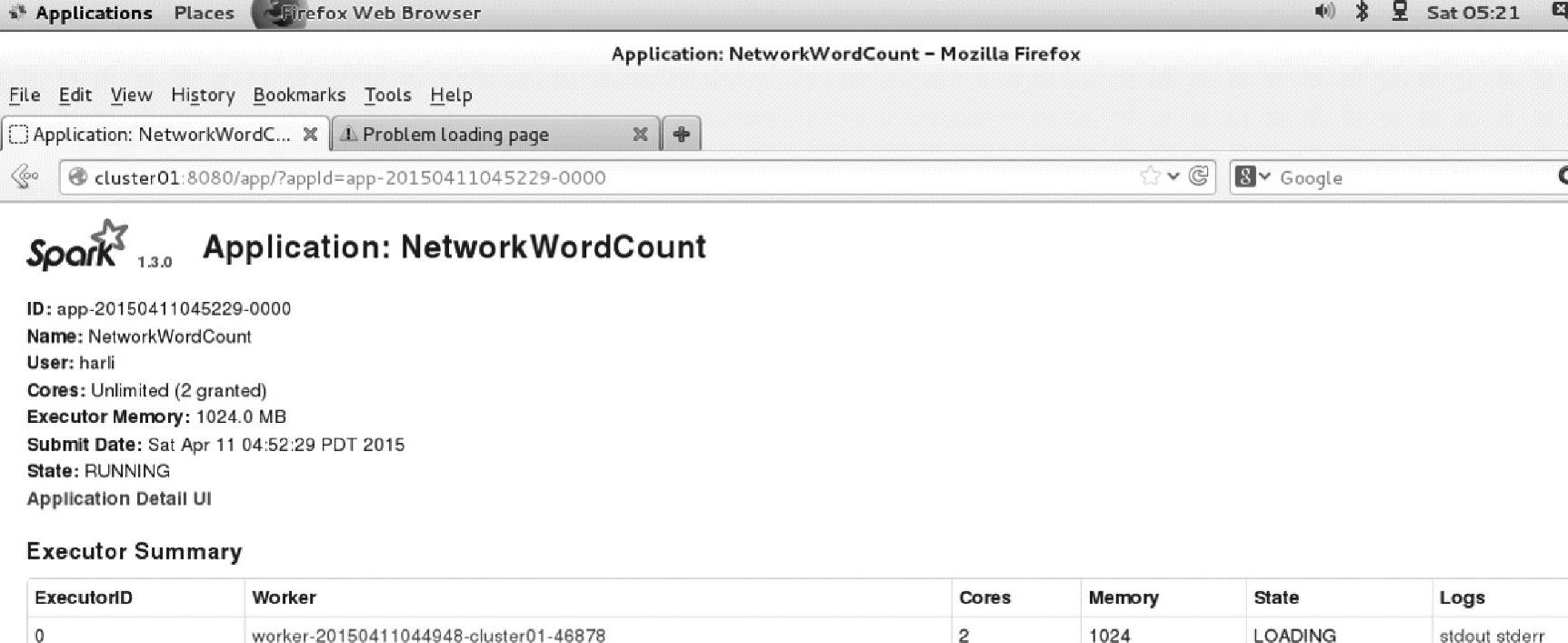
图4.19 Spark应用程序界面信息
切换到Spark-submit的终端,可以看到如下输出:


可以在Time处看到每隔1s提交一次job进行单词统计,这里还有统计时没有收到数据但也提交job的,后续会在案例中给出处理空RDD的方法。
(二)Yarn模式提交
首先停止之前的Spark-submit命令,用【Ctrl+C】组合键停止,然后使用jps命令查询:

使用kill命令终止SparkSubmit进程:(https://www.xing528.com)
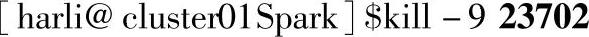
这里使用Client部署模式提交,可以不用【Ctrl+C】组合键,而是直接在另一个终端上查询pid然后使用kill命令关闭:

启动Yarn服务:

到$Spark_HOME路径下,再次提交命令:

注意:由于Hadoop上也没有部署spark-examples-1.3.0-hadoop2.4.0.jar,因此需要使--jars参数进行上传。
在nc终端继续将README.md文件内容复制进去,再次看到NetworkWordCount应用输出单词统计信息:

打开Hadoop的ResourceManager监控界面,查看应用提交结果,如图4.20所示。

图4.20 HadoopResourceManager监控界面的应用程序信息
ResourceManager监控界面地址为:http://cluster01:8088,其中cluster01是启动ResourceManager进程的节点。
切换成yarn-cluster方式提交时,查看Hadoop界面,如图4.21所示。
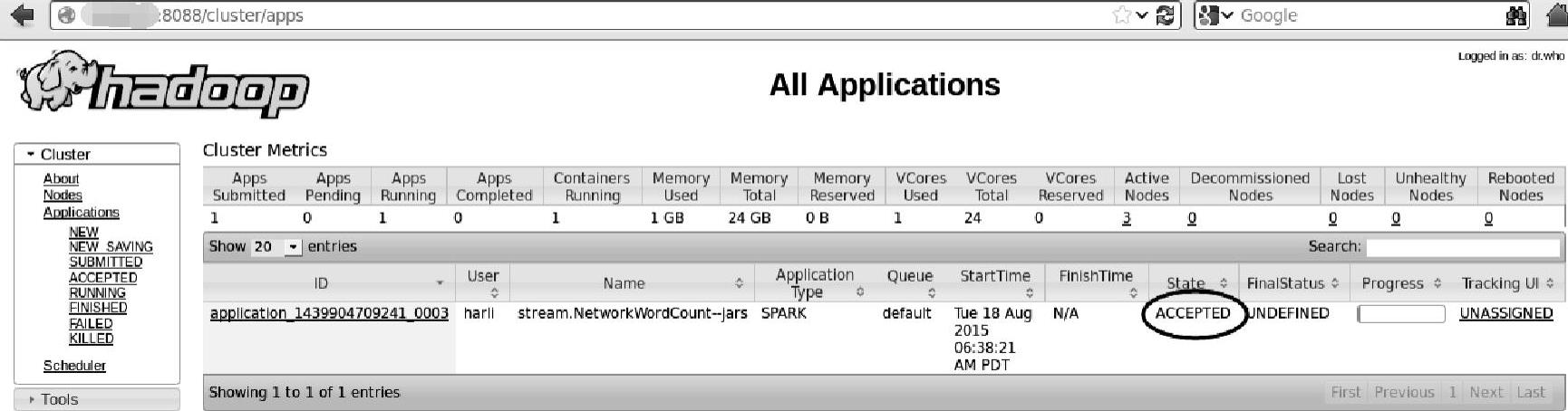
图4.21 HadoopResourceManager监控界面的AM信息
提交成功,单击进入应用后,如图4.22所示出现界面。

图4.22 Spark的job信息
继续查看Executors信息,如图4.23所示。

图4.23 Spark的Executors信息
当前虚拟机的内核数为4,Yarn模式下,提交时Executor的个数默认为2,分配内核为1,因此总的使用内核数为2,对应加一个ApplicationMaster,即图中的driver,一共对应3个内核。
在图4.23中可看到在Hadoop界面对应的driver中没有Logs信息stdout和stderr,不过可以在终端打开该应用下的日志。查看driver的日志输出信息,和我们用Client方式提交时的界面信息是一样的。
当前运行的driver程序日志所在路径为:

logs目录位于执行driver的节点上(在Addresse列可以看到当前执行的节点),其中,application_1428755808048_0004对应应用程序的ID。
对应在Yarn模式下执行的应用程序,可以用以下命令关闭,相关的几个进程也会被关闭:
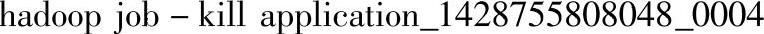
上面是旧的版本所使用的命令,也可以用较新版本的命令,如下所示:

(三)Yarn模式提交补充案例
由于前面yarn-cluster提交的案例是在单机上模拟集群进行的,这时候依赖的第三方包在集群中都是相同位置。同时,针对第三方包的依赖具体过程的疑问,如同时提交出现类找不到等问题,这里为了进一步详细描述,用最新的集群(在基于Tachyon实践案例与解析基础上部署的新的集群——3个节点上),重新给出案例,并在案例中给出详细的包的上传、下载的路径信息。
首先,启动Yarn服务:

启动命令:
./bin/Spark-submit--executor-memory 1g\
--master yarn-cluster\
--num-executors 3\
--class stream.NetworkWordCount\
--jars./Spark-examples-1.3.0-hadoop2.6.0.jar../applications/testprojectide.jar cluster049999
这里以yarn-cluster模式提交,同时,启动了3个Executor。在另一个终端启动nc,并输入要统计的数据:


启动TCP流处理命令:

可以看到,在yarn-cluster模式提交时,会将依赖的jar包和主资源jar包一起上传到HDFS上。
查看上传后的路径下的文件:

可以看到文件已经成功上传。
查看各个执行节点上的缓存文件,这里以cluster06节点为例,其包含文件如下:

可以看到,执行节点已经成功将所依赖的jar包下载到NodeManager的本地路径下,为应用提供依赖jar包。
其中,nm-local-dir是NodeManager执行应用时的local目录,执行时应该从HDFS上下载下来,并存放到该目录下。
这里给出不同于前面的另一种查看输出日志的方法。
1)进入RM节点的Web Interface界面(http∶//cluster04∶8088/cluster),如图4.24所示。
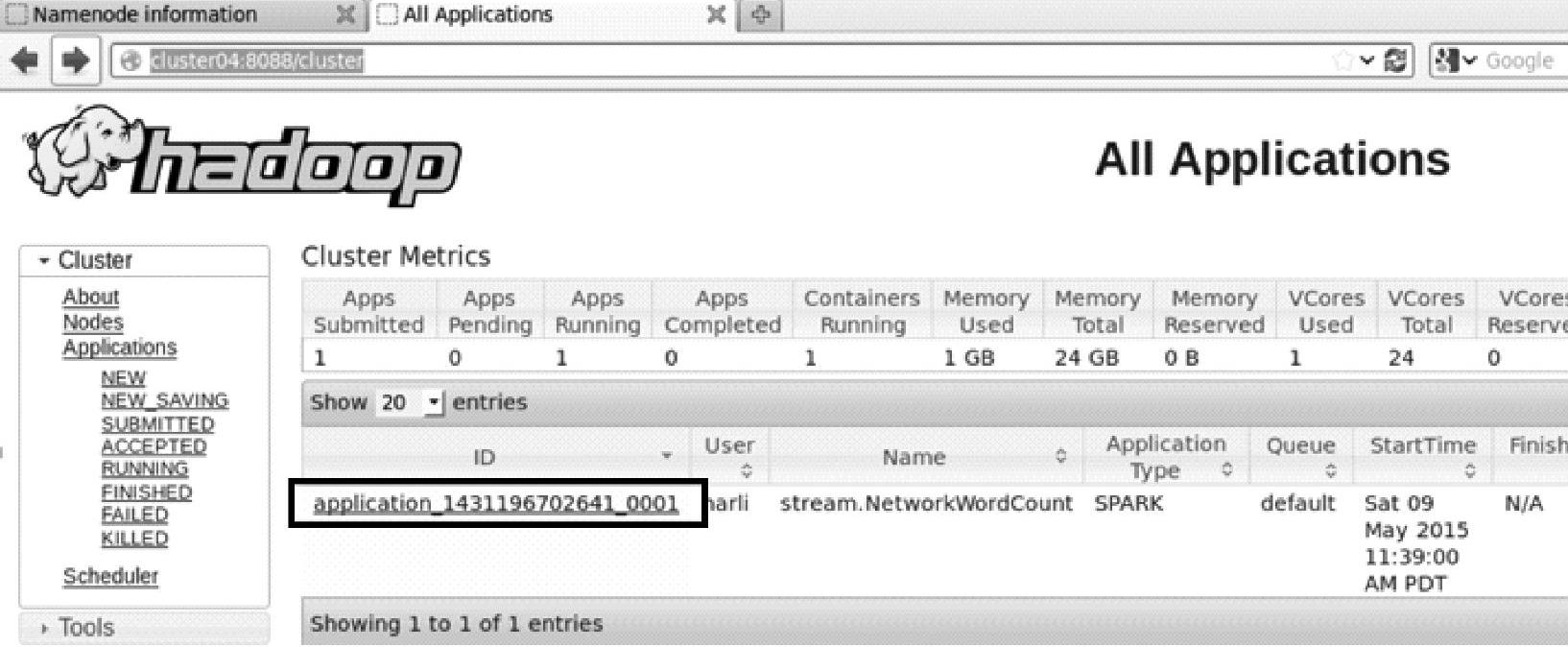
图4.24 HadoopRM的应用信息
2)单击application_1431196702641_0001,查看Application的具体信息,如图4.25所示。
3)单击cluster04∶8042,查看Node节点具体信息,如图4.26所示。
4)单击List of Containers,查看容器信息,如图4.27所示。
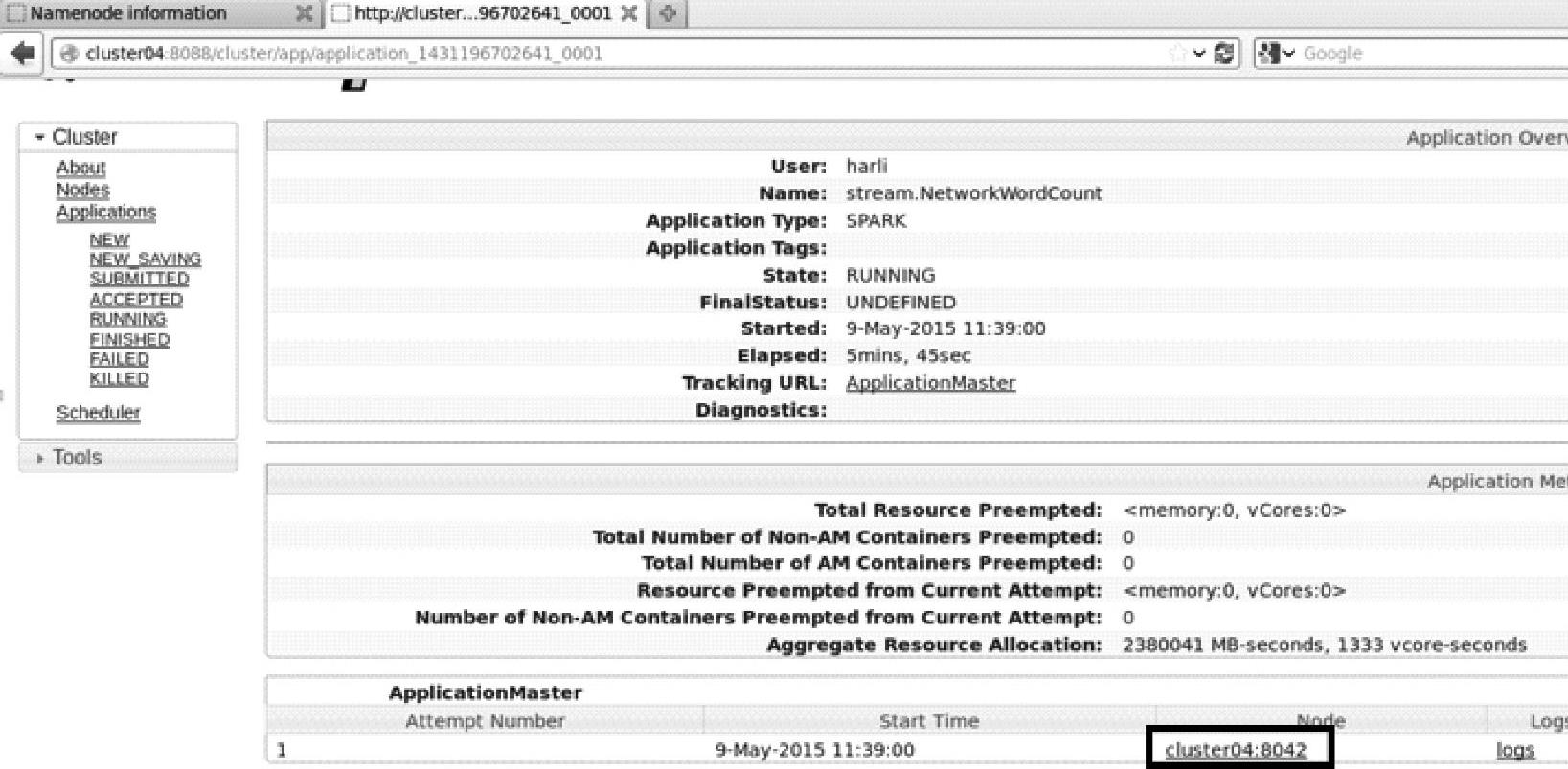
图4.25 HadoopRM的指定应用的信息

图4.26 HadoopRM的指定node的信息

图4.27 HadoopRM的指定应用的容器的信息
5)单击container_1431196702641_0001_01_000001,查看容器具体信息,如图4.28所示。
图4.28 HadoopRM的指定应用的容器的日志信息
6)单击Link to logs,选择特定日志信息,如图4.29所示。
图4.29 HadoopRM的指定应用的容器的日志信息
7)单击stdout:Total file length is 45405 bytes,查看stdout日志信息,如图4.30所示。

图4.30 HadoopRM的指定应用的容器的stdout日志信息
可以看到,stdout中已经成功输出在client模式提交时的界面信息。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。