



一般情况下,各个公司都会建立自己的数据仓库,尤其是当前大数据生态圈中使用最普遍的Hive数据仓库,需要集成这部分数据,向外提供这部分数据的查询接口。Spark SQL提供了分布式SQL引擎,支持直接运行SQL查询的接口,不用写任何代码。
运行的集群环境说明:在新建的集群上运行,部署的Spark版本和Hadoop版本和之前的集群一样,并添加了Hive环境,Hive版本为apache-hive-1.1.0,对应数据库的驱动jar包为:mysql-connector-java-5.1.35.tar.gz。
一、ThriftJDBC/ODBC的案例与解析
Spark SQL提供Thrift JDBC/ODBC支持,这里实现的Thrift JDBC/ODBC服务器与Hive0.13中的HiveServer2相一致。可以用在Spark或者Hive 0.13附带的beeline脚本测试JDBC服务器。
下面给出两种方式启动JDBC/ODBC服务的案例与解析。参考Hive的默认配置文件中的属性:

传输模式支持两种,Binary和HTTP,默认的为Binary。
(一)默认传输模式(Binary),启动JDBC/ODBC服务的案例与解析
这种情况下,在hive-site.xml中没有对hive.server2.transport.mode等属性进行修改。在Spark目录中,运行下面的命令启动JDBC/ODBC服务器。

这个脚本接受任何的bin/spark-submit命令行参数,加上一个--hiveconf参数用来指明Hive属性。可以运行“./sbin/start-thriftserver.sh--help”来获得所有可用选项的完整列表。默认情况下,服务器监听localhost:10000。
可以用环境变量覆盖这些变量,如下所示。
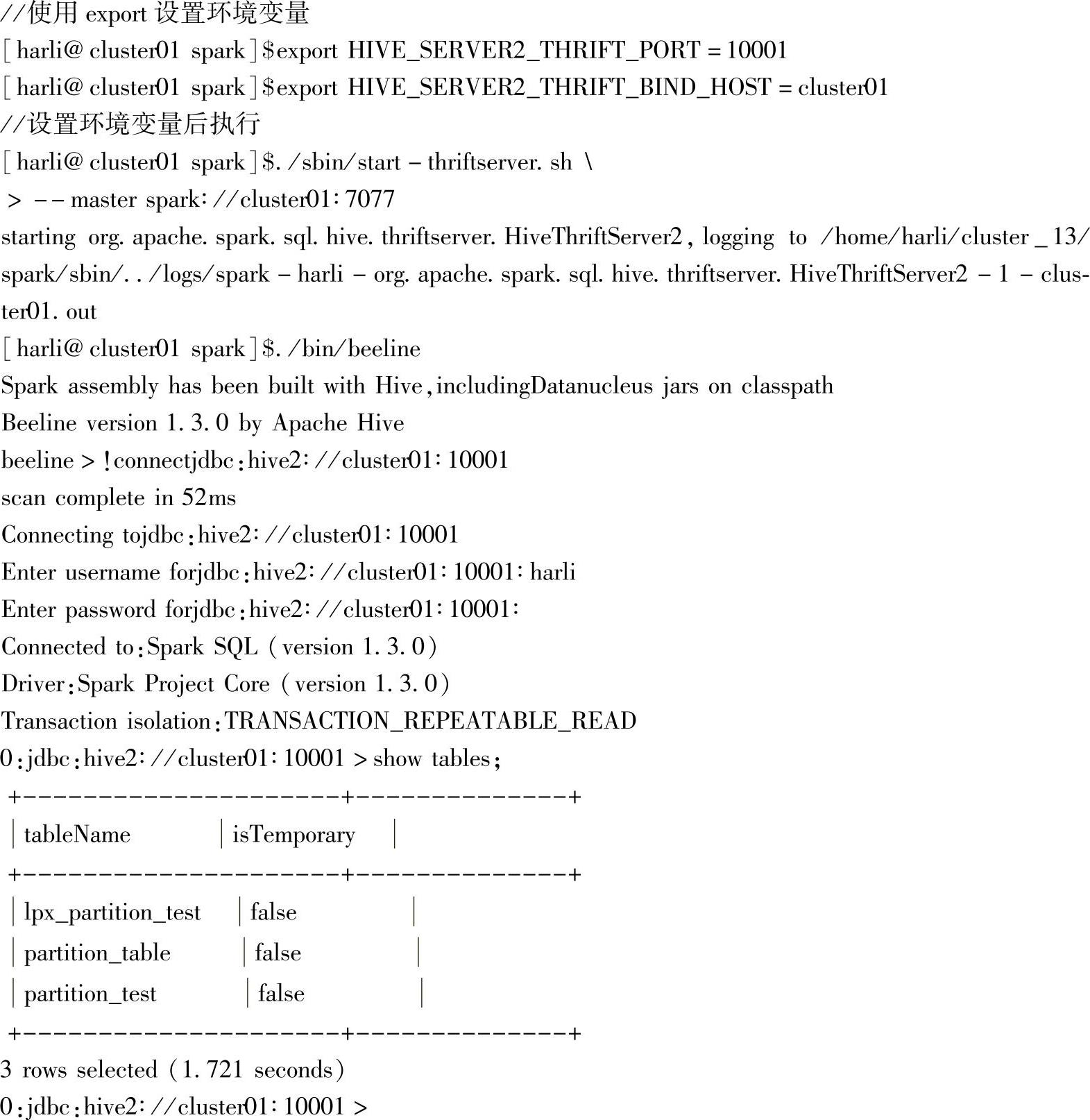
设置--master参数后,应用提交到Standaone集群,查看界面可以看到应用信息,具体内容如图3.21所示。
当前使用默认参数,具体参数和spark-submit一样,可以根据需要调整。
也可以通过系统变量覆盖,命令如下:

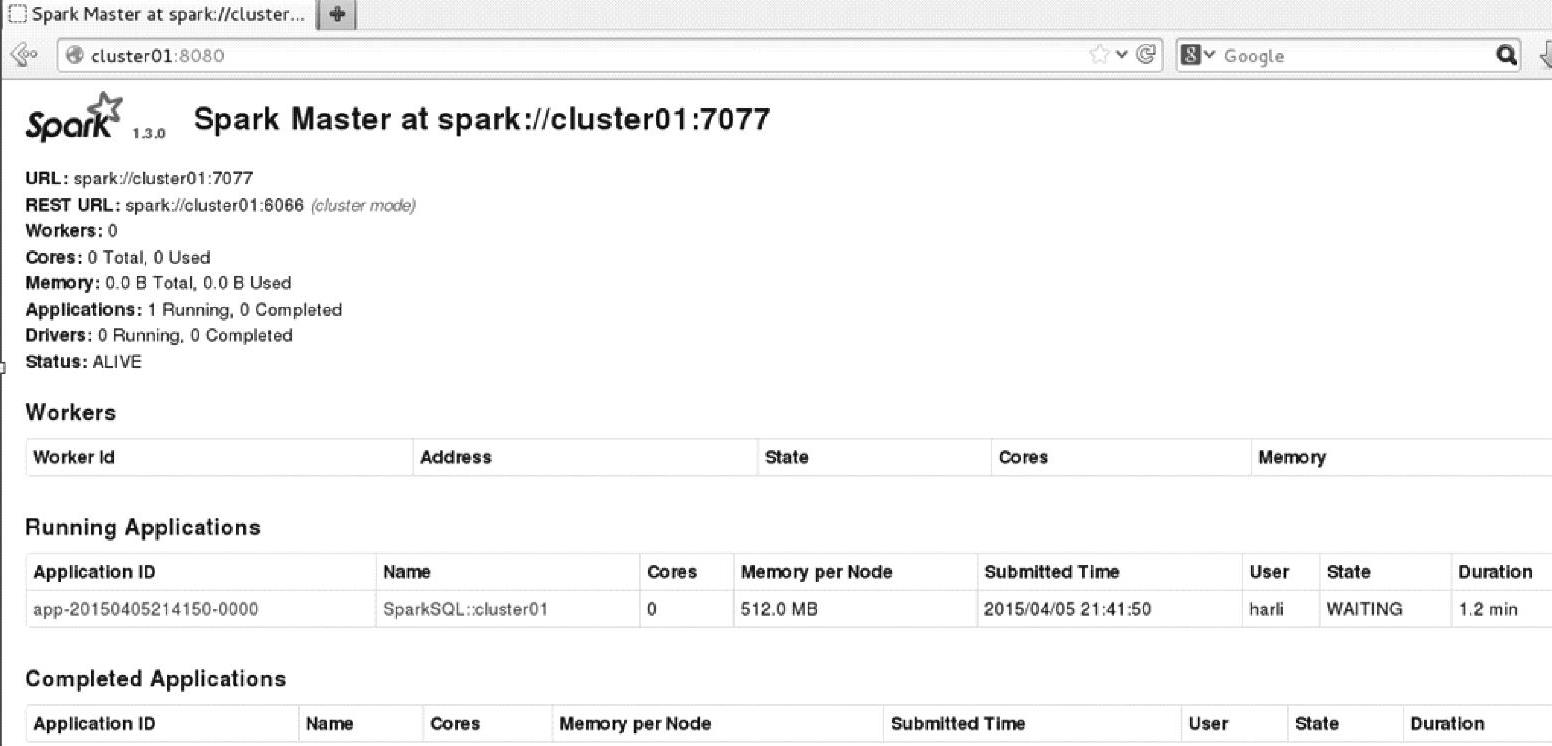
图3.21 Spark监控界面上的Applications信息
现在你可以用beeline来测试Thrift JDBC/ODBC服务器了。
在Spark部署主目录下输入:
连接到Thrift JDBC/ODBC服务器的方式如下:

这里的localhost和10000是默认的主机和端口号,可以用Thrift JDBC/ODBC服务启动时的实际主机和端口号进行替换。
Beeline将会询问用户名和密码。在非安全的模式,简单地输入机器的用户名和空密码就可以。对于安全模式,可以按照Beeline文档的说明来执行。
注意:当报URL连接无效时,如果确认URL正确,可以查看进程或日志,先确认下Thrift JDBC/OD-BC服务是否已经正常启动。
下面中beeline交互界面上执行基本的SQL语句,如下所示:

show tables可以看到之前用SQLContext在Hive中建立的所有表信息。
最后向beeline发送quit命令,退出:(https://www.xing528.com)
(二)HTTP传输模式启动JDBC/ODBC服务的案例与解析
Thrift JDBC服务业支持通过HTTP传输模式来发送thrift RPC消息。可以通过将HTTP模式的配置设置成系统属性,或修改conf下的hive-site.xml文件中的属性配置来实现,如下所示。

其中,最后一个为hive.server2.thrift.http.path属性(官网上的属性在默认hive-de-fault.xml中没有找到)。添加后,复制到“$Spark_HOME/conf”目录下。
编辑hive2server启动脚本:
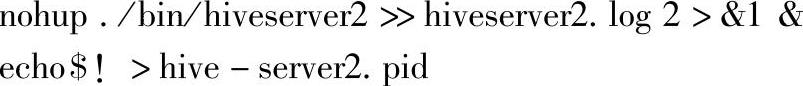
启动Thrift Server测试:

启动beeline连接、查询:

这里也可以试试启动Hive的服务Hive2server,如下所示:
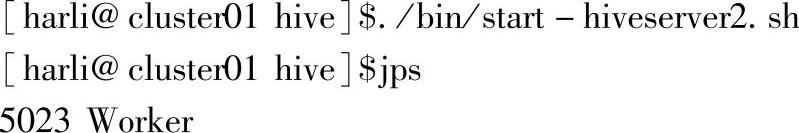

可以看到,这里增加了一个RunJar的进程。由于hivemetastore的进程名字一样,都是RunJar,Hive脚本中没有直接提供停止服务的操作,因此这里在脚本中将pid信息写入了各自的文件中。通过查看该文件,获取pid值,然后关闭进程。
启动HTTP模式下的beeline:

这里的10001为刚才设置属性hive.server2.thrift.http.port,default为默认的数据库。连接成功,并查询出当前Hive中已经有三个表。
二、SparkSQLCLI的案例与解析
Spark SQL CLI是一个便利的工具,它可以在本地运行Hive元存储服务、执行命令行输入的查询。注意,Spark SQL CLI不能与Thrift JDBC服务器通信。
在Spark目录运行下面的命令可以启动Spark SQL CLI:
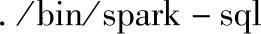
注意:如果Hive使用内置的默认derby数据库,同时只能允许一个会话连接,则启动Thrift JDBC服
务后再次启动Spark-sql将会报异常,异常信息会包含以下内容:

连接Hive时,在CLASSPATH中添加数据库驱动jar包,输入命令:
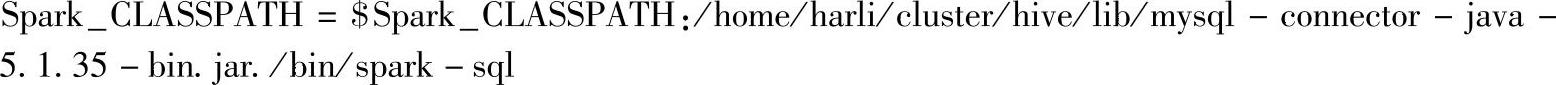
查询当前表信息:

查询成功,就可以开始执行其他的SQL语句了。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。