



Spark SQL还可以从其他数据库使用JDBC读取数据。这个功能应该优先于使用jdb-cRDD。因为它可以直接返回DataFrame,方便在Spark SQL进行处理,也可以很容易地和其他数据源进行join操作。Java或Python也很容易使用JDBC数据源,因为它不需要用户提供ClassTag。注意,这和使用Spark JDBC SQL服务器是不同的,Spark JDBC SQL服务器允许其他应用程序使用Spark SQL进行查询。
在案例操作开始前需要将对应数据库的JDBC驱动添加到Spark的CLASSPATH上。比如,在Spark Shell上连接postgres数据库时,需要使用下面的命令:
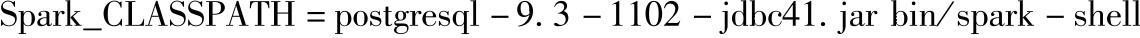
为了解决提交应用时,经常出现的在Executor上找不到驱动包的问题,下面给出两种情况下的案例与分析。通过两种案例解析,可以熟悉不同场景下如何使用提交应用的参数选项。
一、集群中所有集群部署相同,并在集群上的某一节点启动DriverProgram
这种场景下,所有节点上都部署了Spark、Hive,部署路径也相同,而且驱动类在Hive的lib目录下。这时候可以将Hive的lib目录下的驱动jar包添加到Spark_CLASSPATH中,添加时使用绝对路径,因此在每个节点上的CLASSPATH上都能在该绝对路径下找到驱动类。
当前案例以MySQL数据库为例,对应的命令为:
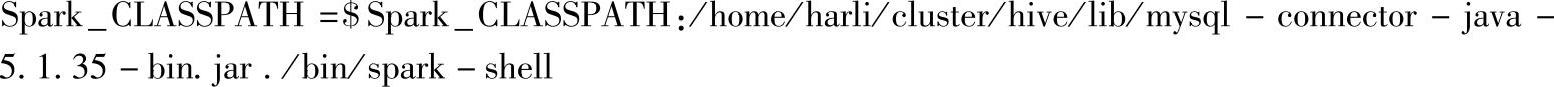
首先,登录MySQL客户端,查看当前Hive数据库下的表:


启动spark-shell:
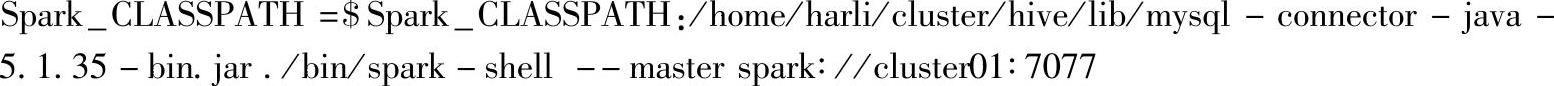
加载JDBC数据库Hive中的TBLS表。

将jdbcDF注册为临时表:

使用数据源API,可以将远程数据库的表装载成一个DataFrame或Spark SQL的临时表。数据源API支持的选项如表3.3所示。
表3.3 数据源API支持的选项

二、在集群上的某一节点启动DriverProgram
这种场景下,需要保证两点,一是Driver program能找到驱动类,二是执行任务的Exec-utor能找到驱动类。
使用第一种情况时,用JDBC表作为测试表。(https://www.xing528.com)
1.启动spark-shell
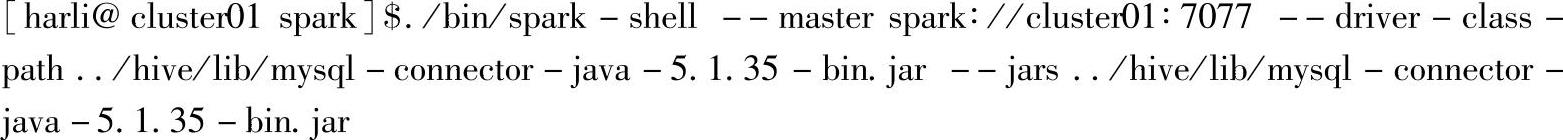
命令参数说明:
1)通过--driver-class-path选项,将driver program所在节点的驱动类路径加到CLASSPATH中;由于此时默认以Client部署模式提交,因此Driver Program在提交节点运行,所以这里可以使用相对路径。
2)通过--jars选项,将Executor需要使用的jar包上传,由于上传的jar包会自动添加到执行点的CLASSPATH,因此Executor执行时是可以识别的,不需要再手动添加到CLASS-PATH上。这里也是把本地的驱动jar包作为--jars参数。
注意:上传的jar包在执行时会自动下载。
2.加载JDBC表


3.显示JDBC表的内容。


注意:这里使用spark-shell,只支持Client部署模式,如果使用spark-submit方式提交Spark应用程序的话,可以使用Cluster部署模式,这时候,Driver Program会由Master(Standalone集群)或Resource-Manager(Spark on YARN)负责调度,此时,可以去掉针对本地Driver Program的CLASSPATH设置,即去掉--driver-class-path选项,--jars上传的驱动类也会自动添加到实际运行节点上的Driver Program的CLASSPATH中。
另外,--jars会随着应用上传,如果这种应用场景比较常用的话,建议使用配置属性,将驱动类的jar包部署到集群节点中。相关配置属性可以参考章节2.1.2应用程序的部署方式部分的提交脚本参数说明。
三、故障排除
当执行Spark应用程序时,如果出现ClassNotFounded、Connect建立失败,或者出现SQL语句解析异常等情况时,可以从以下两点进行故障排除:
1.JDBC驱动程序类对在客户端会话和所有的Executors的初始类加载器必须是可见的。这是因为Java的DriverManager类进行安全检查,导致当建立一个连接时,会忽视所有对初始类加载器不可见的驱动类。一个方法是修改所有worker节点上的compute_classpath.sh,让其包含驱动jar包。
在包含驱动jar包时,需要注意jar包设置的路径应该为全路径。
比如,在Spark_CLASSPATH中添加jar包依赖时,必须使用实际执行时所在的路径;如果路径设置错误,会导致驱动查找失败而异常。异常信息可能包含以下内容:

2.一些数据库,如H2,会将所有名称转换为大写。在Spark SQL中,需要使用大写来引用那些名字。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。