



Spark SQL还支持读写存储在Apache Hive中的数据。Spark 1.3版本中,Spark默认构建实例时包含“-Phive”启用和“-Phive-thriftserver”这两个profile,因此实例构建后就已经支持Hive。可以通过将现有的Hive部署的hive-site.xml配置文件放置到Spark部署的conf目录下,来访问现有的Hive数据仓库。
当使用Hive时必须构造一个HiveContext实例,HiveContext继承自SQLContext,其功能是SQLContext功能的超集合,可以使用更加完备的HiveQL解析器来写查询语句,使用Hive UDFs,并可以访问Hive的MetaStore,从Hive表中读取数据。并且所有在SQLContext下可以获取的数据,在HiveContext中仍然可以获取。
我们不需要使用一个现有的Hive也可以创建一个HiveContext实例,当没有使用hive-site.xml配置文件时,context会自动地在当前目录下创建metastore_db和warehouse。
我们可以通过配置属性spark.sql.dialect来指定SQL所使用的查询解析器,具体使用方法可以参考下面的案例。
下面给出两种情况下使用HiveQL语句的示例。
一、不使用现有的Hive环境
1.构建表
通过“sqlContext.sql("CREATE TABLE IF NOT EXISTS src(key INT,value STRING)")”语句使用HiveQL的建表语句,构建了一个名为src的Hive表,包含key和value两列。


这是构建src表之前的Web Interface界面,如图3.17所示。
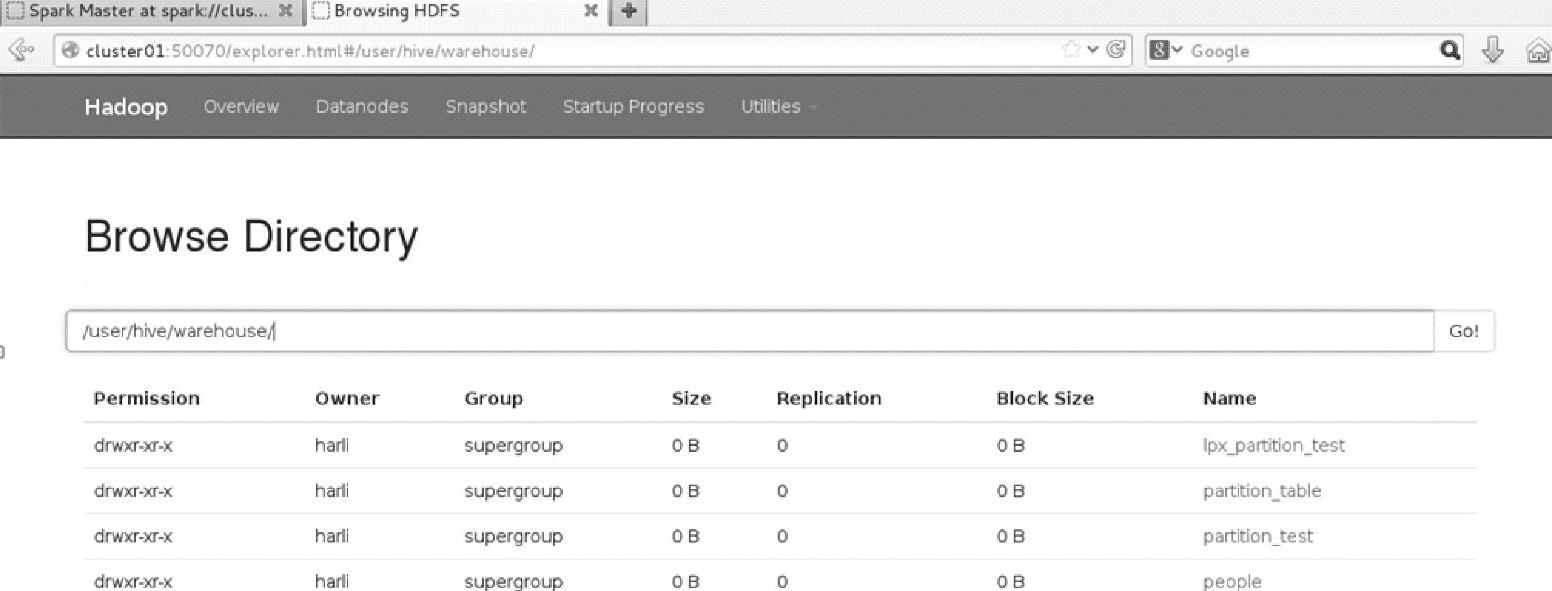
图3.17 Hadoop文件系统在构建src表之前的界面
这是构建src表之后的Web Interface界面,如图3.18所示。可以看到,src表已经在warehouse目录下构建成功。
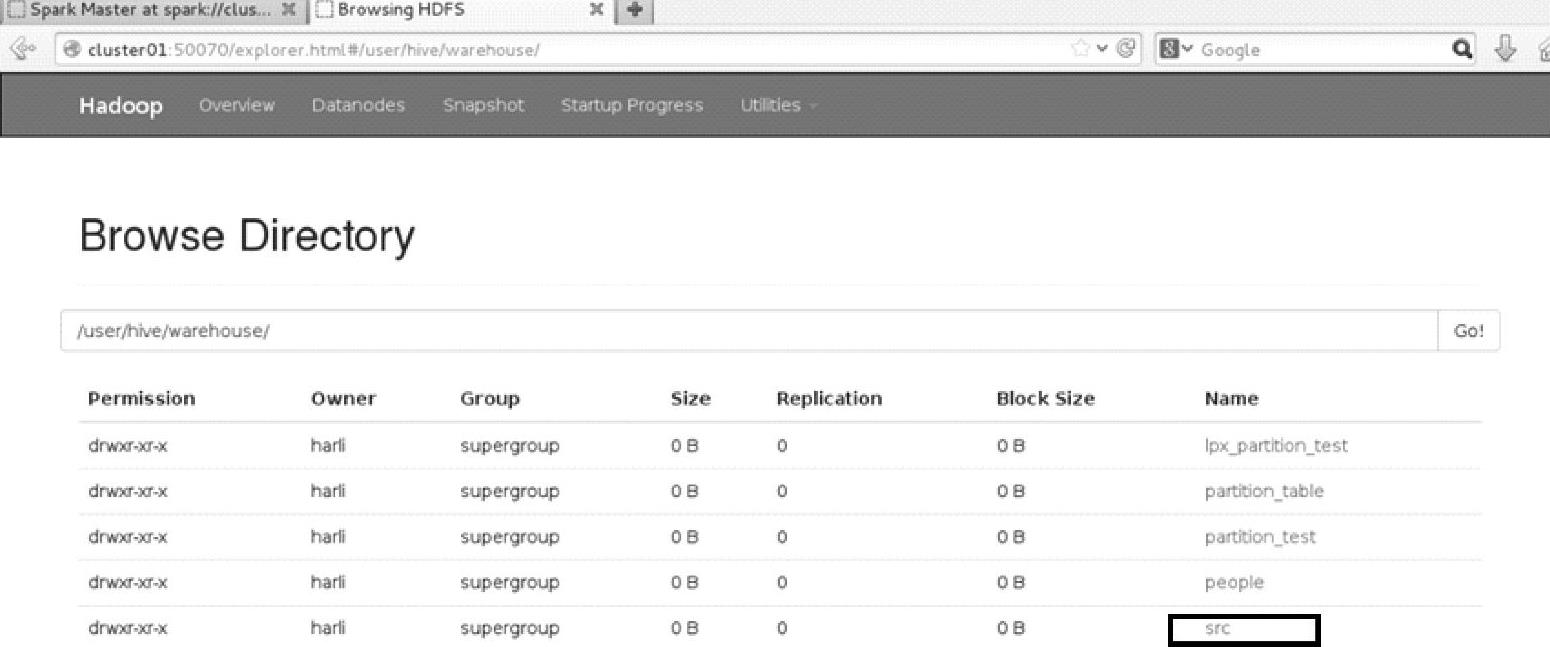
图3.18 Hadoop文件系统在构建src表之后的界面
2.加载本地文件到表中
通过HiveQL的LOAD语句“LOAD DATA LOCAL INPATH′examples/src/main/resources/kv1.tx′tINTO TABLE src”,将本地文件系统中的kv1.txt文件加载到src表中。该文件位于Spark部署目录下。



3.查询src表
从src表中查询key和value字段。

最后通过HiveQL的查询语句“FROM src SELECT key,value”,从src表中查询指定的key和value两列数据来构建出DataFrame实例。
4.在界面输出src表的查询结果
获取查询结果并在终端显示。

5.删除src表
使用drop table删除src表。


日志中包含了具体执行时的详细信息,比如HiveMetaStore部分,包含了当前使用的数据库,执行语句和表名等信息。在metastore.hivemetastoressimpl部分还包含了内部的实现细节,比如由于Hive表不是外部表,这里删除表的同时,也删除了对应的HDFS存储系统上的文件。其他日志信息还包含执行时间、锁操作等。通过对日志信息的分析,可以了解内部的执行流程和细节。
此时查看Web Interface界面,可以看到src表已经被删除,如图3.19所示。
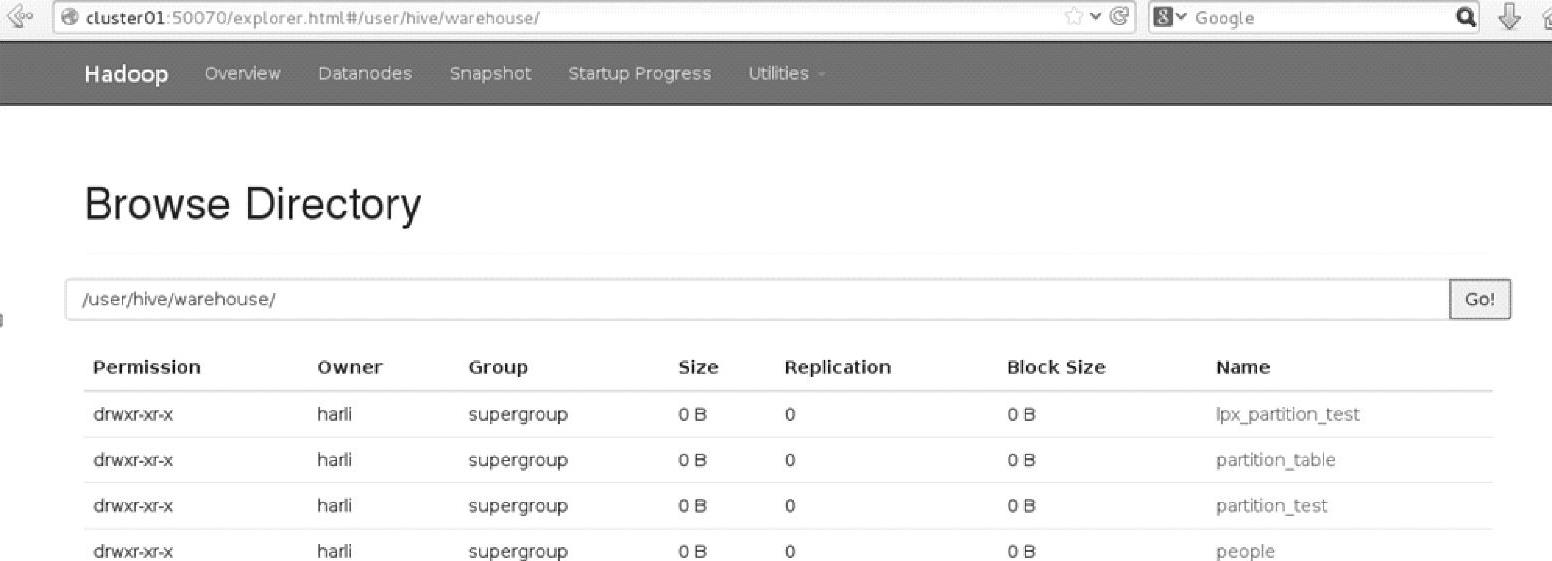
图3.19 Hadoop文件系统在删除表之后的界面
二、使用现有的Hive数据仓库
(一)准备工作
1.安装好mysql数据库。
2.安装好Hive环境,当前Hive环境使用MySQL作为默认的元数据数据库。
1)已将mysql-connector-java-5.1.35-bin.jar复制到hive/lib目录下。
2)已用Hive的jar包替换了Hadoop较低版本的相同jar包:用hive/lib/jline-2.12.jar替换share/hadoop/yarn/lib/jline-0.9.94.jar;如果没有替换,运行“./bin/hive”时会报jline的类不兼容错误。
3)在hive-env.sh中按实际集群修改下面三个属性:

4)hive-site.xml配置示例:


其中,javax.jdo.option.ConnectionURL为数据库连接的URL信息,根据MySQL具体安装设置。当前连接的用户名和密码为root/mysql,实际情况下最好不要使用root用户。
在此主要讲解Spark SQL的案例,因此只介绍最基本的Hive的环境配置。如果需要修改,可以参考Hive官网的部署文档。比如,可以增加Hive数据库的编码的属性设置:在配置javax.jdo.option.ConnectionURL中添加“&;characterEncoding=latin1”,metastore的远程访问的配置中为hive.metastore.uris设置value为thrift∶//cluster01∶9083,等等。其中,character Encoding设置的编码为latin/。
注意:ConnectionURL参数中的&符号在XML文件中需转义。驱动类比较旧时,比如mysql-connec-tor-java-5.1.6-bin.jar,在执行(比如drop table)语句时可能会出现如下异常:

这是由于MySQL的版本和驱动的版本不匹配导致的,测试时使用的MySQL版本是5.6,而案例使用的驱动是mysql-connector-java-5.1.6-bin.jar,由于MySQL 5.6已经抛弃了这个参数,所以会报上面错误,这里换成最新的驱动mysql-connector-java-5.1.35-bin.jar后问题解决。
当前MySQL版本信息如下:
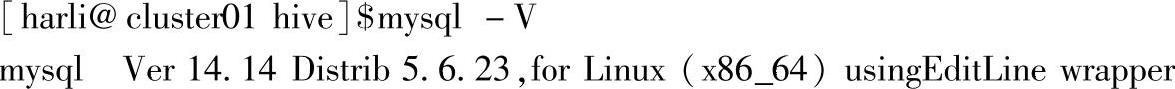 (https://www.xing528.com)
(https://www.xing528.com)
MySQL驱动的下载地址:http∶//dev.mysql.com/downloads/connector/j/(二)操作Hive表的案例
在Hive中启动./bin/hive
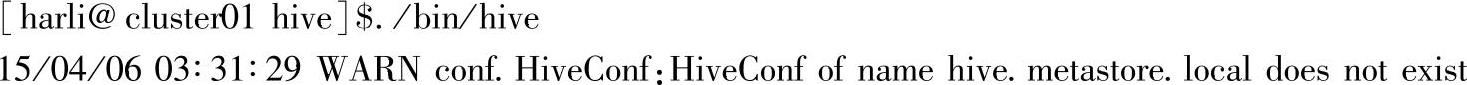

出现“hive>”提示后,开始创建一个表:
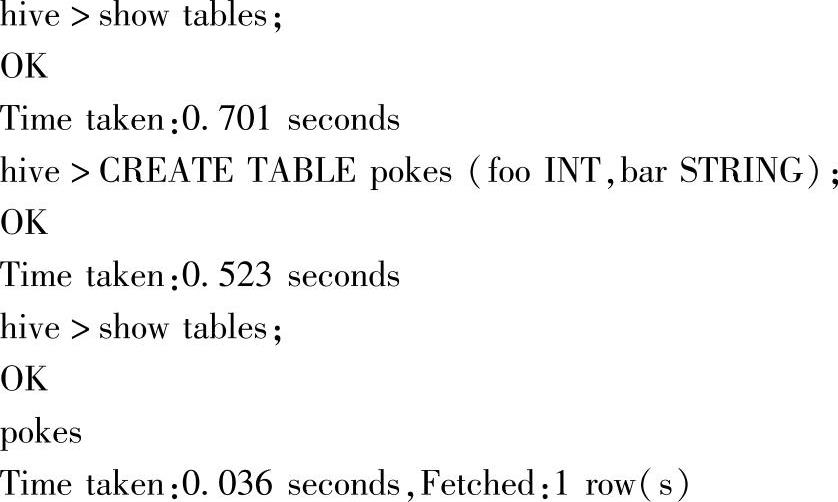
查看Web Interface界面上的文件系统信息,如图3.20所示。
图3.20 Hadoop文件系统在Hive的cli中构建表之后的界面
可以看到,中/user/hive/warehouse这个默认仓库目录下,生成列对应表名的目录pokes。
将mysql-connector-java-5.1.35-bin.jar路径添加到Spark_CLASSPATH下,启动Spark脚本,脚本内容如下:


在交互式界面中查询现有的表信息:

已经可以查看到Hive刚创建的表。
在Spark SQL中创建表:
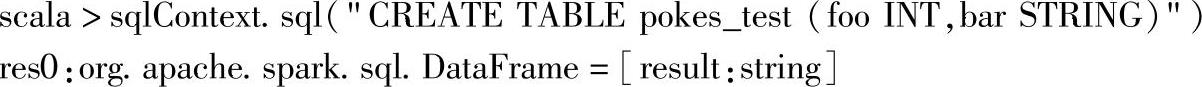
在Hive中查看:

注意:如果启动spark-shell脚本时,没有将mysql-connector-java-5.1.35-bin.jar包添加到当前的CLASS_PATH路径下,在加载类时会找不到类导致MySQL的数据库连接失败,这时候会出现包含以下信息的异常提示:


其中,第一个Caused by处提示连接创建失败,继续往下查可以看到驱动类(com.mysql.jdbc.Driver)找不到的异常DatastoreDriverNotFoundException。
小技巧:
1.当日志出现Error时,跟踪其调用堆栈信息,查找关键字为Caused by,可能其中一个异常堆栈信息中会出现多个Caused by,而最下方的Caused by,也就是最早抛出异常的地方,往往就是错误的根源,问题的根源才是解决问题的出发点。
2.类找不到的根本原因,参考章节3.3.5使用JDBC操作其他数据库的案例与解析部分的故障排除的内容,主要是由JVM的类加载机制导致的。如果在当前执行环境(需要注意在分布式计算框架下,是对应真正执行的节点,与提交点等其他节点的环境无关)下的CLASSPATH中找不到该jar包,就会出现类找不到的异常。
3.Spark计算框架已经提供了自动将所需jar包添加到执行环境的CLASSPATH上了,如果执行环境本身没有部署该jar包,就可以充分利用Spark的--jars参数来自动设置。
(三)远程访问MetaStoreServer的案例
修改hive-site.xml文件,添加:

远程访问MetaStoreServer时,需在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer来访问元数据库。当没有启动MetaStoreServer服务时,执行spark-shell会出现如下错误信息:


由于连接请求被拒绝导致HiveMetaStoreClient实例化失败,因此需要先启动远程的MetaStoreServer服务,启动代码如下:
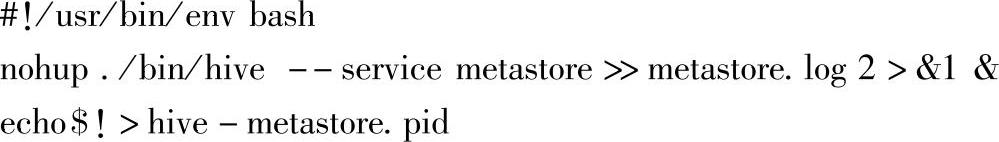
这里以后台进程方式启动metastore,同时保存进程ID到指定文件中。启动后,再次执行spark-shell后,运行命令访问Hive的metastore信息就可以正常执行了:

三、扩展用户定义函数场景下的实践案例与解析
在Spark 1.3版本中,在DataFrame领域特定语言(DSL)或SQL中使用的UDF,其注册操作被移到了SQLContext中。下面给出UDF注册实例,并基于该UDF的定义,给出DataFrame和SQL中的两种案例。
以下的数据准备和之前的案例是一样的:

其中people.txt是Spark提供的部署目录中的resources子目录下的文件。
注册名为strLen和fmtNum的两个UDF:

注册的strLen的函数功能为将传入的字符串转换为字符串的长度,fmtNum对Int型的age进行格式化。
在SQL中的使用案例如下:

在DataFrame中的UDF使用案例如下:


这里使用注册的strlen这个UDF后,返回的DataFrame的schema也会自动进行推导。对应的fmtNum函数被调用后,age字段也自动推导为String类型。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。