



针对相同功能的API进行分组,基本上以官方网站上API的顺序给出应用案例。
一、collect与collectAsList
1.定义

2.功能描述
collect返回一个数组,包含DataFrame中包含的全部Rows。
collectAsList返回一个Java List,包含DataFrame中包含的全部Rows。
3.示例

4.示例解析
案例中首先加载列people.json文件,然后以表格形式呈现其内容。
两个collect型的方法都可以获取df的全部Rows数据,只是返回的类型不同。调用col-lect方法,返回的是数组,数组元素的类型为org.apache.spark.sql.Row;调用collectAslist,返回类型java.util.List[org.apache.spark.sql.Row]。
二、count
1.定义
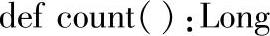
2.功能描述
返回DataFrame的rows个数。
3.示例

三、first
1.定义
def first():Row
2.功能描述
返回DataFrame的第一个row。
3.示例

四、head
1.定义
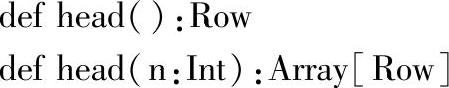
2.功能描述
不带参数的head方法,返回DataFrame的第一个Row。指定参数n时,则返回前n个Rows。
3.示例

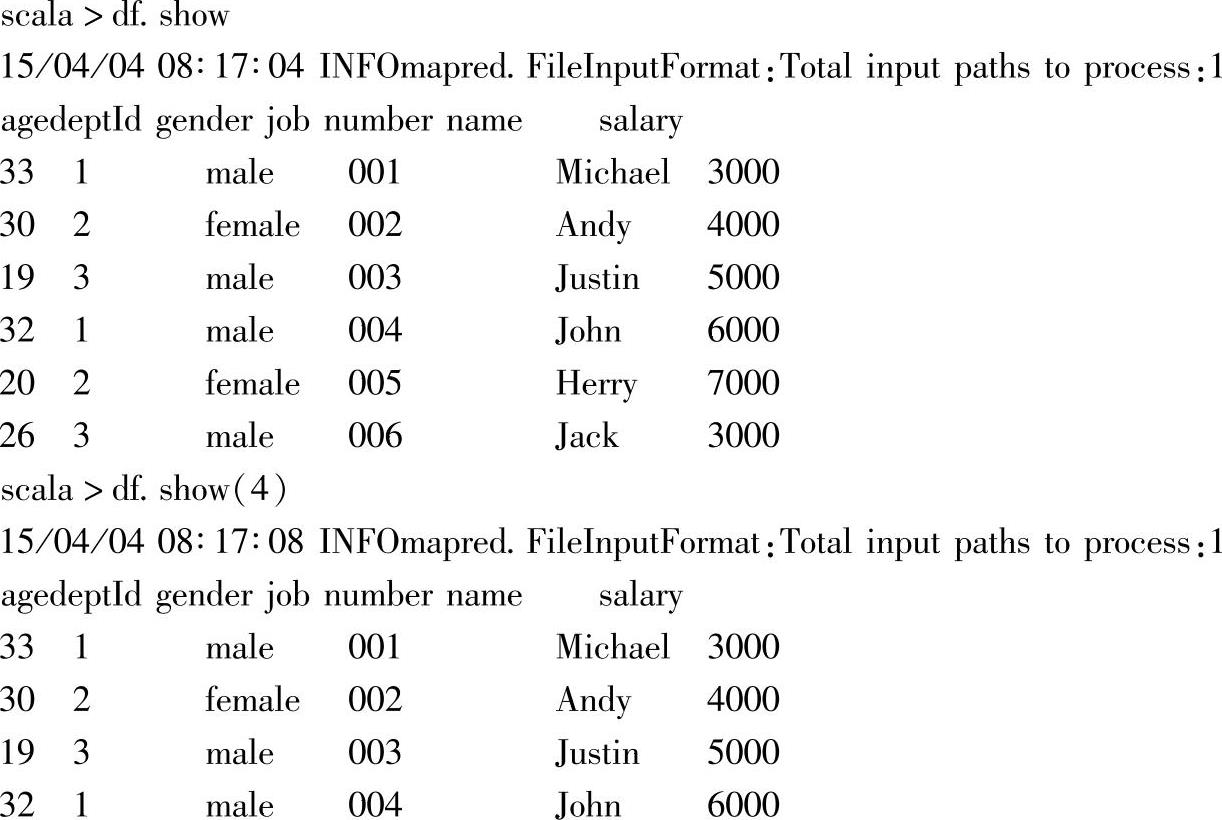
五、show
1.定义

2.功能描述
不带参数的show方法,以表格形式显示DataFrame的前20个Rows。指定参数numRows时,则显示指定numRows个数的Rows。
3.示例
六、take
1.定义
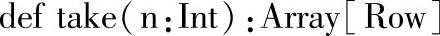
2.功能描述
返回DataFrame中指定的前n个Rows。
3.示例

七、cache
1.定义
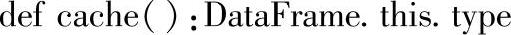
2.功能描述
将DataFrame缓存到内存中。
3.示例

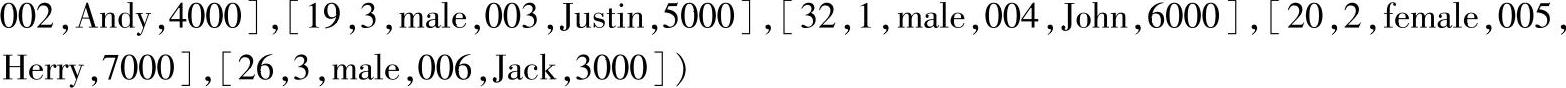
可以看到,当执行了cache操作后,对DataFrame执行操作时,不需要再从原始数据源加载数据。
八、Columns
1.定义
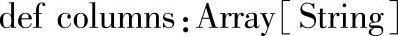
2.API的功能描述
以数组形式返回DataFrame的全部列名。
3.示例

九、dtypes
1.定义
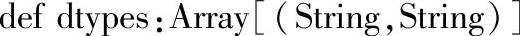
2.功能描述
以数组形式返回DataFrame的所有列名及其对应数据类型。
3.示·例
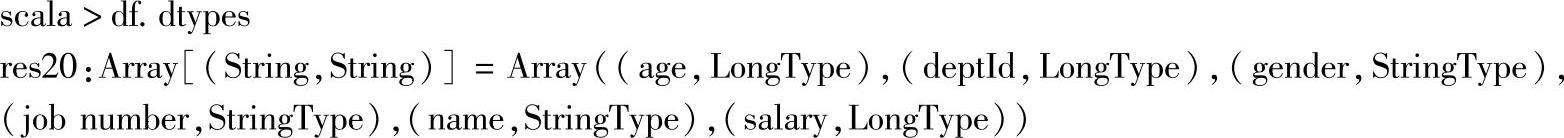
十、explain
1.定义

2.功能描述
这两个方法用于调试目的,不带参数时,仅将DataFrame的物理计划打印到控制台上;当指定参数extended为true时,打印所有计划到控制台上,包括物理计划、逻辑计划。
3.示例


由“Code Generation:false”可以看到,当前代码生成(CG)优化没有开启。
十一、isLocal
1.定义
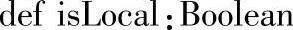
2.功能描述
如果collect和take方法可以在本地运行(即不需要任何Spark Executors)时,返回true。
3.示例

十二、printSchema
1.定义
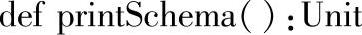
2.功能描述
以树型结构将DataFrame的Schema信息打印到控制台上。
3.示例

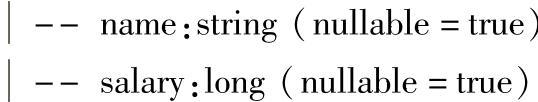
树节点由列名及其数据类型组成,其中nullable表示该列是否可以取null值。
十三、registerTempTable
1.定义
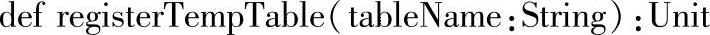
2.功能描述
将DataFrame注册为指定名字的临时表。
3.示例

注册成临时表之后,可以使用SQLContext的sql方法,执行SQL语句。
十四、schema
1.定义
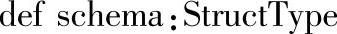
2.功能描述
返回DataFrame的Schema信息,对应类型为StructType。
3.示例

十五、toDF
1.定义

2.功能描述
不带参数的toDF返回它本身,带字符串数组的参数时,返回新的DataFrame,该Dat-aFrame重命名了各列名。
3.示例

注意:在调用带参的toDF方法时,参数个数必须和调用者DataFrame的列个数一样。
十六、agg
1.定义

2.功能描述
agg这一系列的方法,为DataFrame提供数据列不需要经过groups就可以执行的统计操作。
3.示例

可以看到,直接用agg方法和先用groupBy分组再调用agg方法的结果是一样的。这里分别统计了age的最大值和salary的平均值。
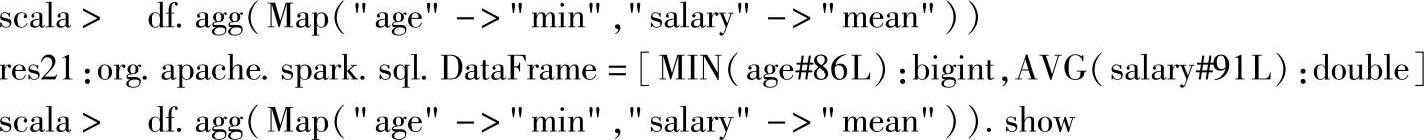
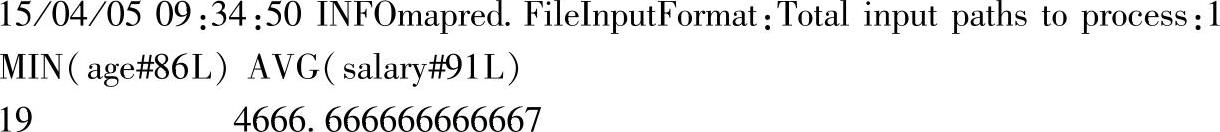
这是使用Map作为参数的示例,分别统计列age的最小值和salary的平均值。

这是使用二元组重复参数作为参数的示例,分别统计列age的最小值和salary的平均值。
十七、apply
1.定义
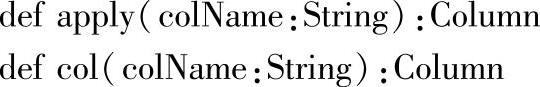
2.功能描述
这两个方法都可以根据指定列名返回DataFrame的列,其类型为Column。
3.示例
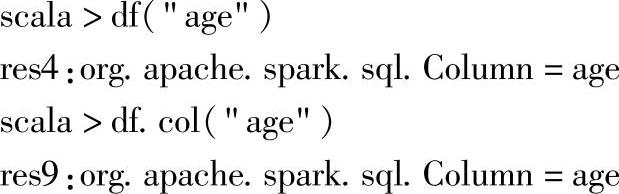
十八、as
1.定义
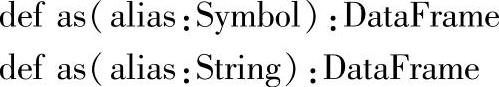
2.功能描述
调用as方法后,使用别名构建DataFrame。
3.解析
为了分析这个方法的作用,查看带as方法和不带的两种情况。
首先修改调试日志的级别,方便查看调试信息:
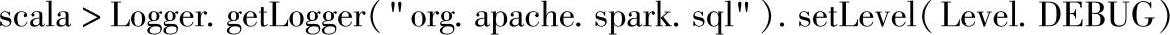
不带as方法时的调试信息:


带as方法时的调试信息:


调用as方法后,仅在解析逻辑计划时,解析的第一步使用了别名:Subquery alias(在Parsed Logical Plan处)。
十九、distinct
1.定义
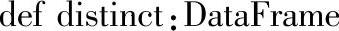
2.功能描述
返回对DataFrame的Rows去重后的DataFrame。
3.示例

示例中加载newPeople.json文件,构建了newPeople(是个DataFrame),通过unionAll方法合并df与newPeople,然后选择有重复Rows的“name”列,最后调用distinct方法进行去重。
二十、except
1.定义
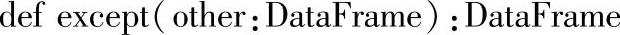
2.功能描述
返回DataFrame,包含当前Frame的Rows,同时这些Rows不在另一个Frame中。相当于两个DataFrame做减法。
3.示例

二十一、explode
1.定义

2.功能描述
返回一个新的DataFrame,其中原来的每一列都被指定的函数扩展成零行或多行。
3.示例


二十二、filter
1.定义

2.功能描述
按参数指定的SQL表达式的条件过滤DataFrame。
3.示例(https://www.xing528.com)

二十三、groupBy
1.定义
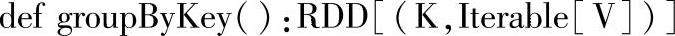
2.功能描述
使用一个或多个指定的列对DataFrame进行分组,以便对它们执行聚合操作。
3.示例
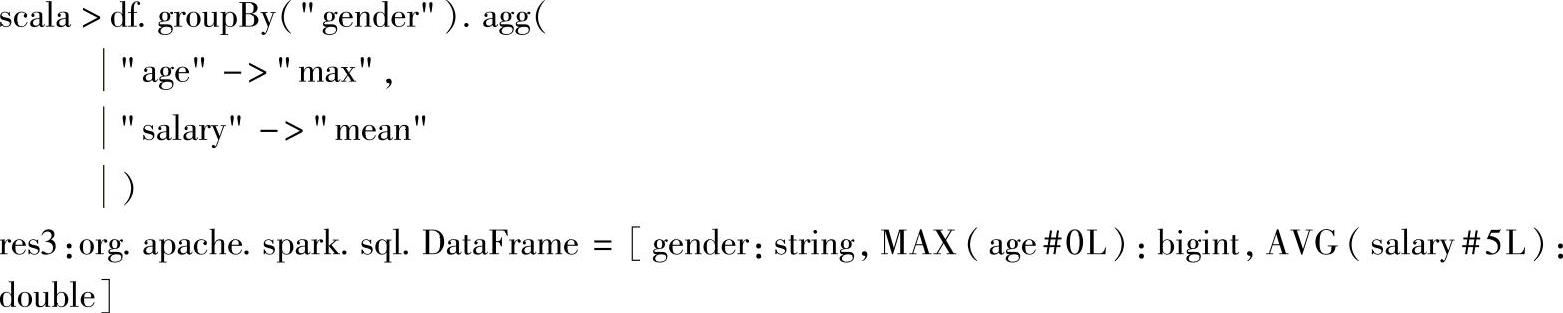
示例中先根据“gender”列对df进行分组,分组后再求“age”的最大值和“salary”列的平均值。
二十四、intersect
1.定义

2.功能描述
取两个DataFrame中同时存在的Rows,返回DataFrame。
3.示例

二十五、join
1.定义

2.功能描述
对两个DataFrame求join操作。不带参数时取笛卡儿积,仅带join Exprs时默认为Inner Join,第三个join参数joinType可以指定具体的join操作。
3.示例
1)与前面的案例一样,加载测试文件:

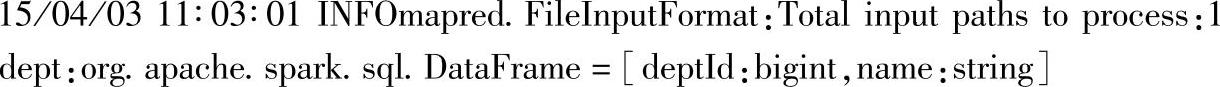
2)将部门信息和人员信息做外联操作:

二十六、limit
1.定义
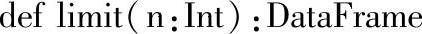
2.功能描述
返回DataFrame的前n个Rows。
3.示例

二十七、orderBy和sort
1.定义

2.功能描述
按指定的一列或多列进行排序,分别支持字符串或Column的参数列表。
3.示例
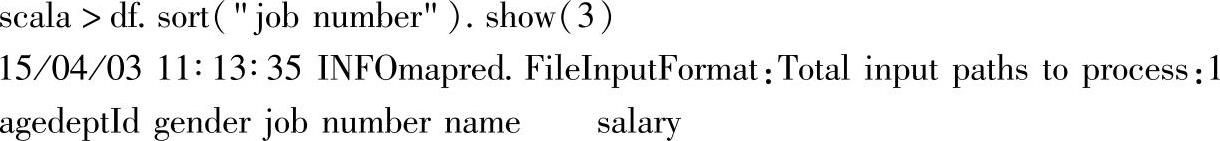

二十八、sample
1.定义
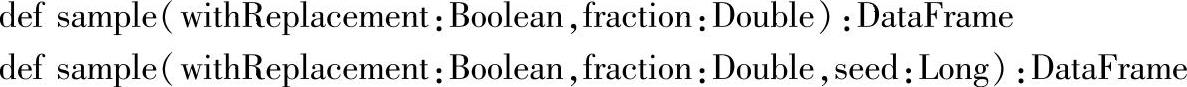
2.功能描述
按指定因子对DataFrame的Rows进行取样,如果指定withReplacement为true时,使用指定的种子或随机的种子进行替换。
3.示例
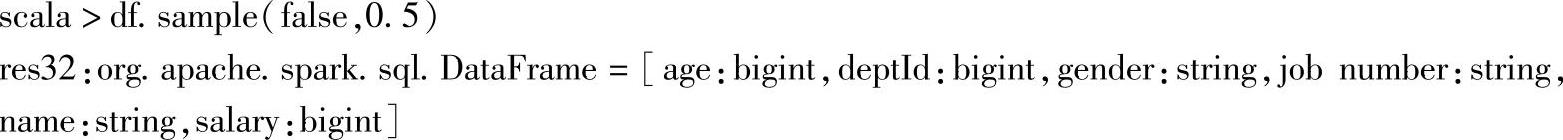

当withReplacement为false时,指定的种子无效,为true时,会根据指定的种子,对应Rows的序号进行替换。
二十九、Select系列
1.定义
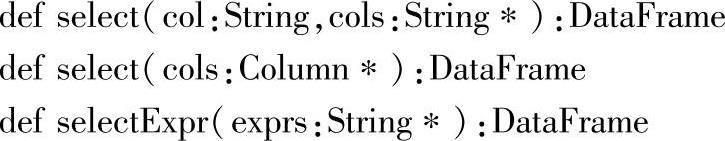
2.功能描述
从DataFrame选取指定的列,返回DataFrame。指定列有三种方式,可以用列名字符串的重复参数,或Column重复参数及列名表达式的多个参数来指定。
3.示例


三十、unionAll
1.定义

2.功能描述
联合调用者和参数这两个DataFrame的Rows。
3.示例

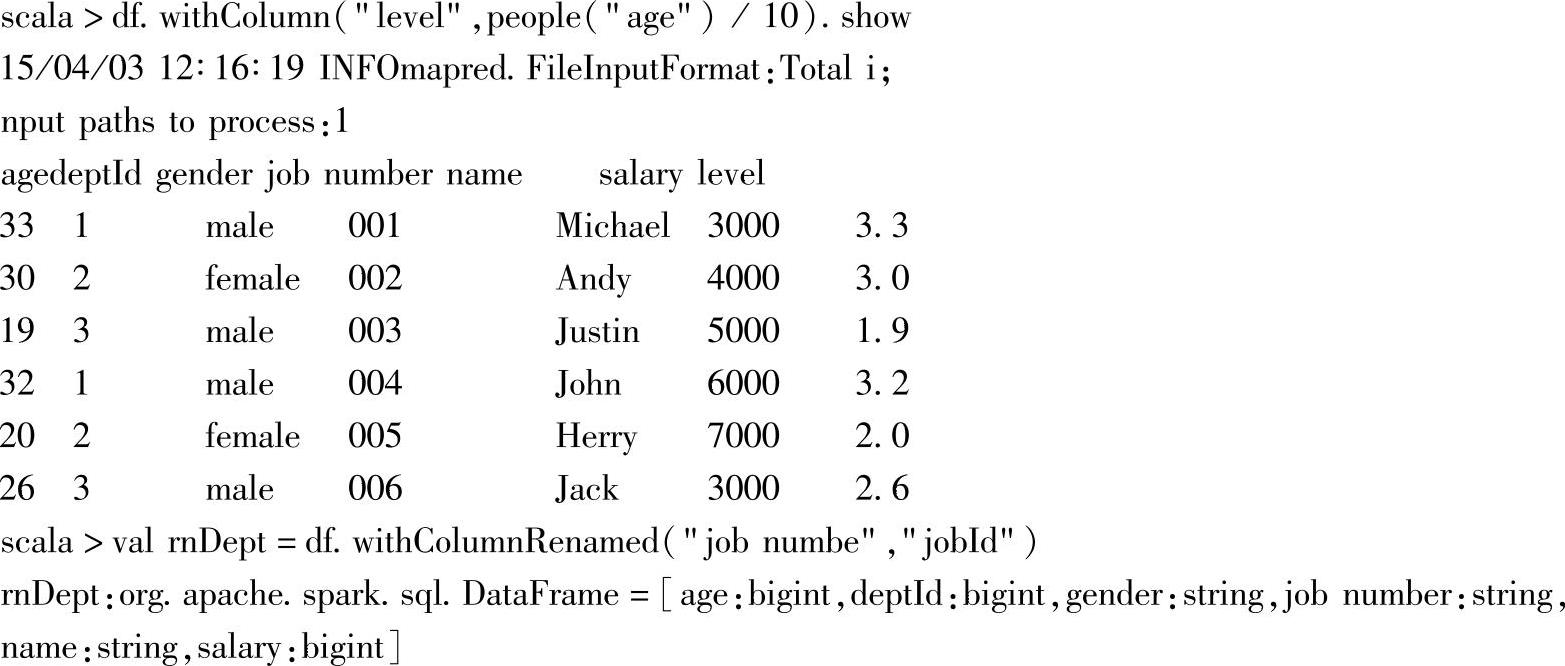
三十一、withColumn和withColumnRenamed
1.定义
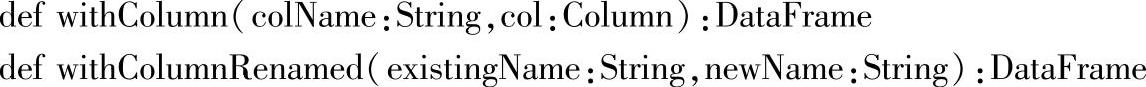
2.功能描述
对DataFrame列进行操作,withColumn增加DataFrame的列信息,withColumnRenamed则是对DataFrame的列进行重命名。
3.示例
三十二、insertInto、insertIntoJDBC和createJDBCTable
1.定义

2.功能描述
insert系列的方法:向指定表中增加DataFrame的Rows数据。带参数overwrite且为true时,insert into会导致覆写原表的数据(即插入前先truncate表)。参数url用来指定数据库信息。
createJDBCTable用于创建外部数据库的表,参数包含数据库连接的url信息,表名ta-ble,以及allowExisting表示是否允许表已存在。如果allowExisting为true,会在create表之前先delete表。
3.示例


示例中首先构建了两个DataFrame,用其中一个调用createJDBCTable方法构建了一个表:“TEST_JDBC”,这里createJDBCTable的第三个参数设置为true,当表存在时会先drop表,然后再create表。
创建表之后,使用insertIntoJDBC方法,将第二个DataFrame插入到刚创建的表“TEST_JDBC”中,其中,insertIntoJDBC的第三个参数选择了false,因此不会覆盖原有的表数据。
三十三、save
1.定义

2.功能描述
将DataFrame的数据保存到指定路径下,其中path为数据存储路径,source为数据源标识,mode为保存模型,各个模型的具体信息可以参见章节3.3.1通用的加载/保存功能的案例与解析部分的保存模型的内容。
3.示例

通过hdfs命令查看/user/harli/allword.json:

三十四、saveAsParquetFile
1.定义
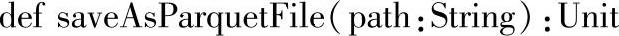
2.功能描述
将DataFrame保存到数据源为“parquet”的指定路径下。
3.示例


通过hdfs命令查看路径“/user/harli/allword.parquet”:

三十五、saveAsTable
1.定义

2.功能描述
将DataFrame保存到表中,参数和save方法一样。
3.示例


三十六、flatMap
1.定义
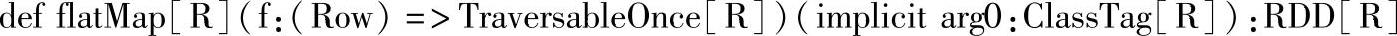
2.功能描述
对DataFrame中Rows进行处理,并且将处理结果。
3.示例

示例中将Row转换为由每一列组成的List。
三十七、foreach
1.定义

2.功能描述
foreach方法上对DataFrame中的Rows进行处理。foreachPartition方法则是对应分区中的Rows进行处理,即Iterator[Row],使用方法类似。
3.示例

由于这是分布式计算,因此需要到Executor所在节点查看输出信息,查看Web Interface界面(http∶//master∶8080),获取输出信息,依次跳转界面,如图3.8所示。
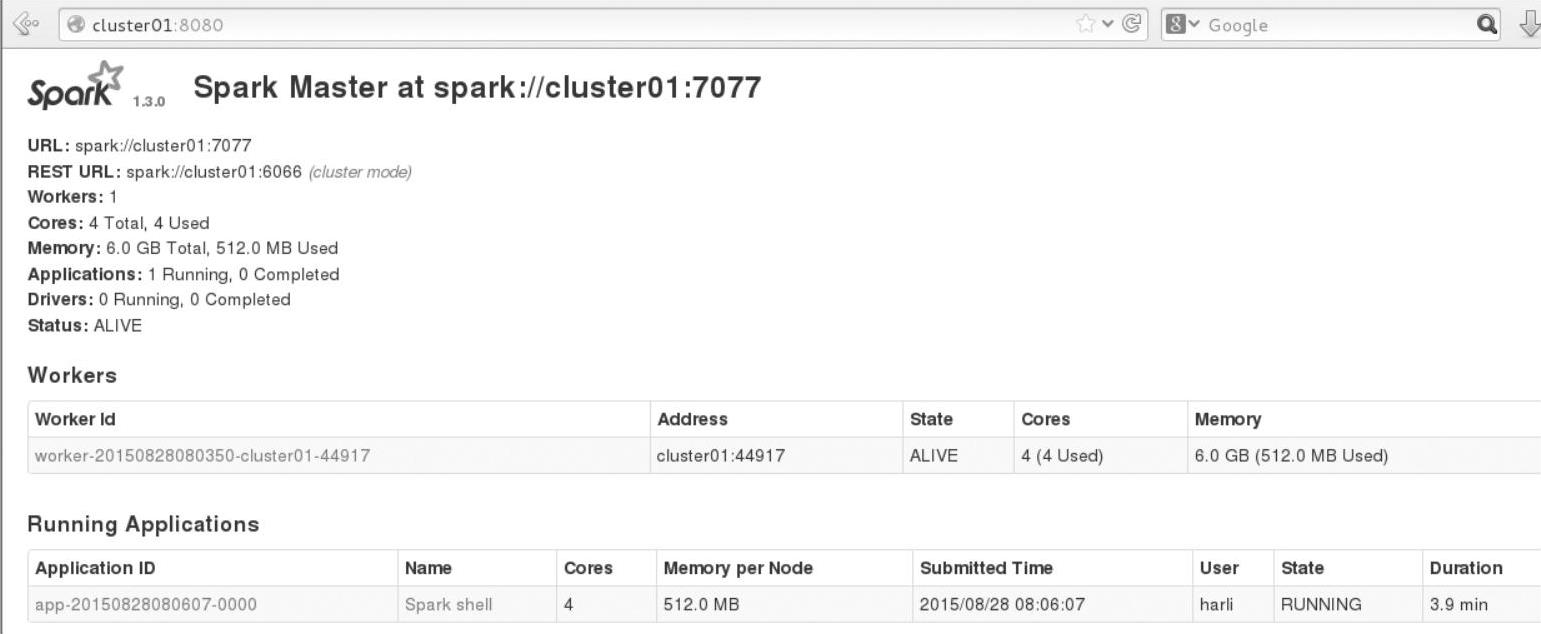
图3.8 Spark监控界面上的Application信息
监控界面上的特定Executor的日志信息如图3.9所示。
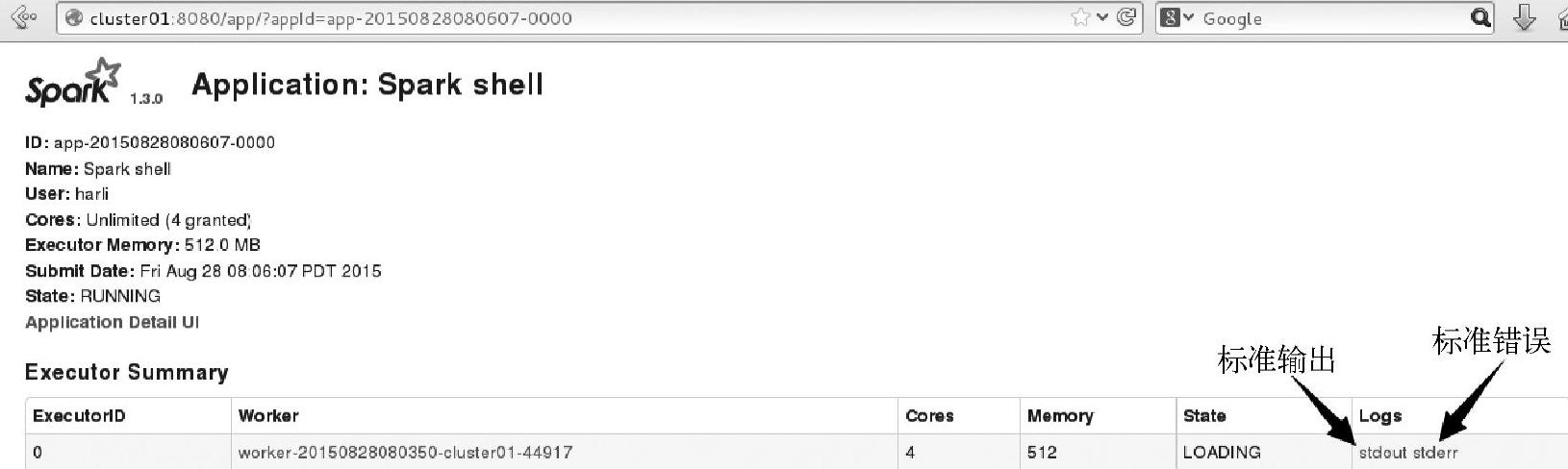
图3.9 Spark监控界面上特定Executor的日志信息
单击Logs下的stdout,可以查看到输出信息,如图3.10所示。
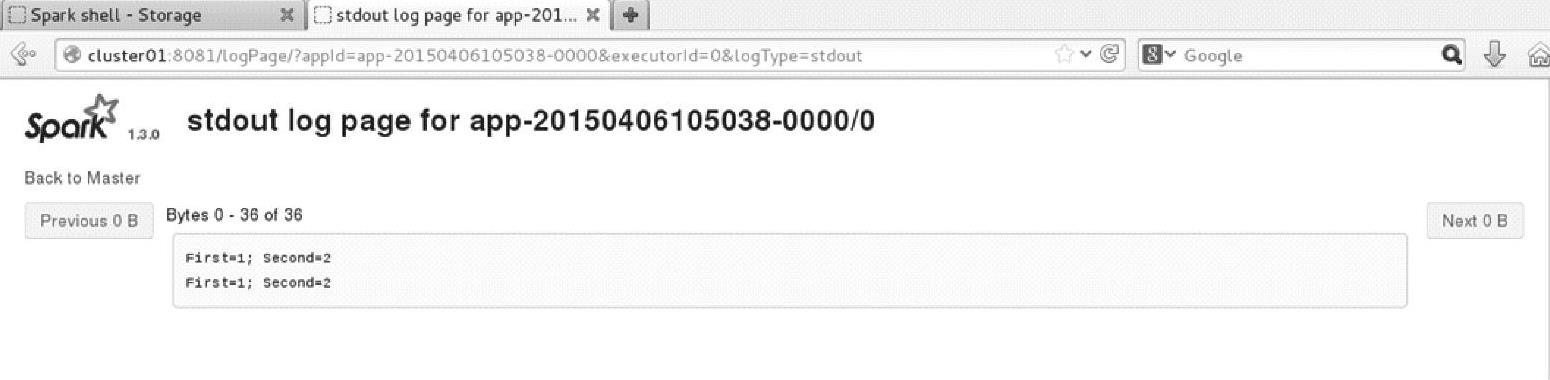
图3.10 Spark监控界面上特定Executor的stdout日志信息
由于当前执行了两次,因此stdout上有两行输出信息。
注意:这是在另一个集群中运行,cluster01是运行Spark的Master进程的节点。
三十八、map和mapPartitions
1.定义

2.功能描述
map方法将DataFrame的Row按指定的函数参数映射成R实例,并返回以R为元素类型的RDD实例。
mapPartitions方法和map类似,只是函数参数作用在Iterator[Row]。
3.示例


4.应用场景
这里重点分析mapPartitions的应用场景,该API对大数据量进行处理时,如果应用得当,可以极大提高计算性能,通过查看源码,可以看到许多性能优化都是通过直接调用该方法来实现的。
具体的应用场景,比如求TopN型的场景,如果基于大数据量进行排序然后取topN,这在性能上是不可接受的,参看源码中使用了mapPartitions方法的takeOrdered方法:

可以看到,该方法将大数据量的聚合转变成了分区小数据量的聚合操作,这里的聚合是分区的topN操作,原理上,和aggregate型的API是一样的,只是在对分区聚合结果上的处理有点差异,aggregate型的API是对分区的聚合结果再次进行二次聚合,然后封装成RDD类型返回,而takeOrdered方法,只需要对分区的聚合结果进行二次聚合,也就是上面源码中的mapRDDs.reduce{(queue1,queue2)…部分,二次聚合后直接把得到的新的topN数组返回即可,不需要再封装成RDD。
从上面的分析可以看到,对分布式的计算,基本原则就是化整为零,然后根据具体应用场景,对细节进行优化。因此,当需要实现类似于TopN的场景时,可以借鉴takeOrdered方法,但后面的具体细节处理,可以根据应用场景进行优化。
需要注意的是,takeOrdered方法在分区聚合结果的处理上,是基于N的值比较小的情况下,如果分区数为K的话,那么mapRDDs.reduce{(queue1,queue2)…}这一步得到的数据集的大小就是K∗N(在每个分区都有N个的情况下),如果K∗N数据量太大,超出内存装载能力,那就可能出现OMM的问题了。解决方法还是一样的,就是根据前面讲的,根据具体场景的实际情况,在细节的处理上进行优化。比如:
1)先用aggregate型的API方法进行初步聚合,然后在得到的结果RDD上,重分区,合并各个分区的TopN值,这样K就减少成了M,最终Driver Program端再进行sort时,数据集就可以从K∗N变成了M∗N,可以有效避免内存不足(Out of Memory)的问题。其中减少分区的方法可以使用coalesce方法进行重分区,参数shuffle设置为false,避免shuffle的过程。
2)也可以用另一种方法,修改mapRDDs.reduce{(queue1,queue2)…}方法的聚合操作,不再使用“queue1++=queue2”,而是将后面的toArray.sorted(ord)移入reduce中,每次reduce后取queue1、queue2的TopN,这种方法其实就是再次利用val mapRDDs=mapPar-titions{…}.中对分区排序的处理方式。实际上这种方法是没有必要的,如果数据量小,直接合并后再排序效率会更高,如果数据量大,那么在Driver Program端进行排序就失去了分布式并行计算的优势了。
这里使用“queue1++=queue2”是由于大部分场景下,TopN的N值都不会太大,即使“++”也不会造成OOM的问题,而上面两种解决方法,都是一种用性能换内存的权衡结果,大部分场景下是不需要的。
三十九、repartition
1.定义
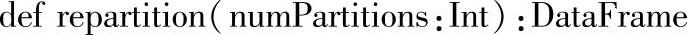
2.功能描述
返回一个DataFrame,该DataFrame按指定numPartitioins对原DataFrame进行重分区。
3.示例

示例中,重分区后返回的DataFrame对应的RDD的分区个数已经改为1。
DataFrame的分区,实际上对应其RDD的数据分区。因此分区个数也对应了RDD的分区个数。
四十、toJSON
1.定义
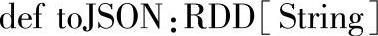
2.功能描述
把DataFrame的内容用包含JSON字符串的RDD返回。
3.示例
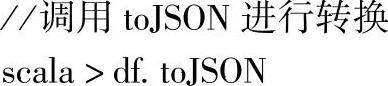

四十一、queryExecution
1.定义
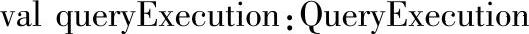
2.功能描述
返回DataFrame的查询执行语句,包含逻辑计划和物理计划。
3.示例

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。