



这一节给出了一个集团公司对人事信息处理场景的简单案例,详细分析DataFrame上的各种常用操作,包括集团子公司间的职工人事信息的合并、职工的部门相关信息查询、职工信息的统计、关联职工与部门信息的统计,以及如何将各种统计得到的结果存储到外部存储系统等。
在案例中,涉及的DtaFrame实例内容包括从外部文件构建DataFrame,在DataFrame上比较常用的操作,多个DataFrame之间的操作,以及DataFrame的持久化操作等内容。
一、数据准备
数据准备包含两部分内容,一是实践案例的数据设计部分,二是将数据文件上传到HDFS存储系统上。
1.创建本地文件的目录
在本地文件目录中构建包含实践数据的文件,包含员工信息的文件、新增员工信息的文件以及部门信息的文件。
2.编辑文件people.json

people.json文件包含了员工的相关信息,每一列分别对应:员工姓名、工号、年龄、性别、部门ID以及薪资。
3.编辑文件newPeople.json
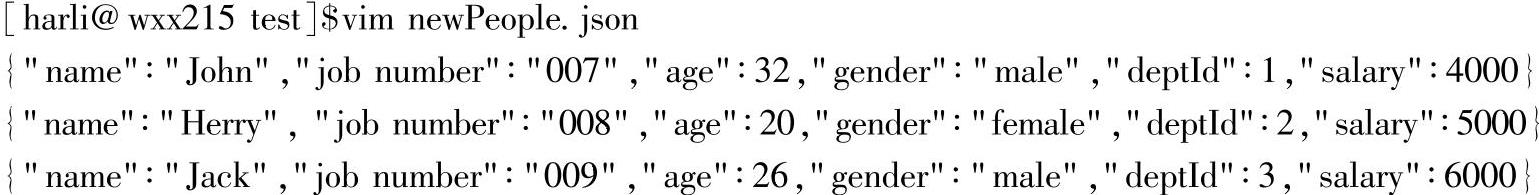
该文件对应新入职员工的信息,这里简化了不同子集团员工信息的结构差异,如果子集团员工具有不同的信息结构,可以通过在样本类people中将缺失的列设置为默认值,从而保证所有的员工信息在结构上的一致性。
4.编辑文件department.json

department.json文件是员工的部门信息,内容包含部门的名称和部门ID。其中,部门ID对应员工信息中的部门ID,即员工的deptId列。
5.上传文件

将所需的三个文件上传到Hadoop集群中,作为实践案例的集群数据。
1)查看上传结果:
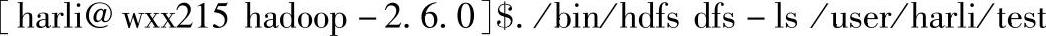

通过Hadoop的命令行,查看上传文件是否成功。可以看到,三个文件已经成功上传到HDFS存储系统上。
2)查看界面显示:Web Interface(http∶//namenode∶50070/explorer.html#/user/harli/test)的界面信息如图3.2所示。
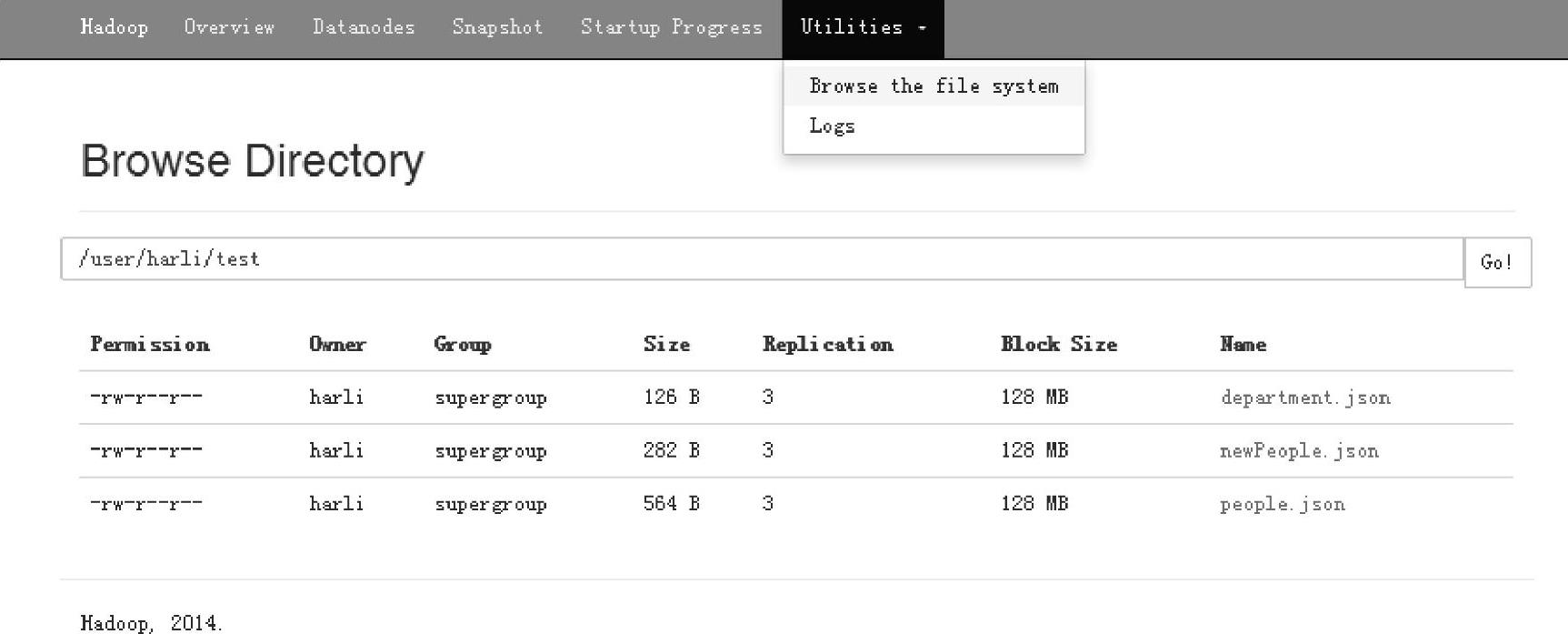
图3.2 Hadoop文件系统上传结果的界面
登录HDFS的namenode节点(namenode节点为启动NameNode进程的节点,当前环境下的节点地址为192.168.70.214。)的50070端口,在Utilities菜单上单击Browse the file sys- tem命令,开始浏览当前HDFS的文件系统信息,内容包含文件的访问权限、所有者、所有者所在组、文件大小、复制因子、块大小以及文件的名字。
可以在路径导航栏部分输入指定的目录,然后单击“Go!”按钮跳转到该目录下。在浏览目录文件时,可以通过单击文件名来打开文件具体信息的窗口,在打开的窗口上还提供了文件下载的功能。
二、启动交互式界面
当前以集群模式启动spark-shell应用,在spark部署目录下,输入以下命令:
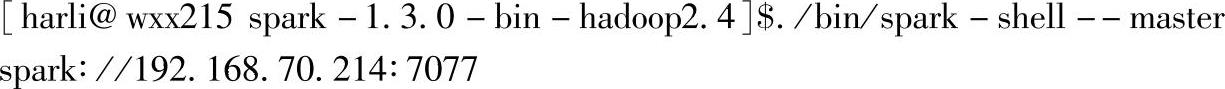
启动后出现如下信息:


在启动界面最后会生成SparkContext和SQLContext两个实例,对应sc和sqlContext。直接使用sqlContext进行操作:

按【Enter】键后进入交互式界面,开始案例的操作。
从上述信息中,我们可以看到交互式工具spark-shell启动后创建的是带Hive支持的SQLContext,对应的提示信息为:repl.SparkILoop:Created sql context(with Hive support)。
查找对应的源码,我们可以看到,在repl.SparkLoop类中构建sqlContext时使用的是HiveContext类,源码如下:


当Spark带Hive编译时,对应创建的就是HiveContext实例,而当该实例构建失败时,创建的是SQLContxt实例。
注意:当我们使用spark-submit来提交应用程序时,在应用程序中,应该用相同的方式去构建SQL-Context实例,通过该实例进行Spark SQL的操作。同时,使用spark-shell时,已经自动导入一些隐式转换,对应的,使用spark-submit提交时,应在代码中手动加入,如import sqlContext.implicits._。
三、案例实操
这部分内容对员工信息以及员工的部门信息进行处理,以下是各类数据操作的具体操作及分析。
1.修改日志等级
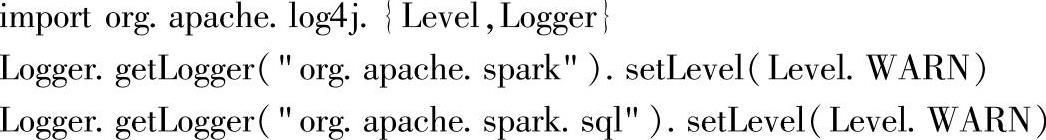
这个操作的目的是为了简化界面的输出。在交互界面上输入以上代码,将日志级别调整到Level.WARN。
2.加载文件

这里提供了两种方式加载之前上传到HDFS存储系统上的员工信息文件和部门信息文件,可以看到,文件加载后得到了两个DataFrame实例:people和dept,同时根据文件内容自动地推导出两个DataFrame实例的schema信息,schema信息包含了列的名字以及对应的数据类型,如dept的schema信息为[deptId:bigint,name:string]。
构建DataFrame的其他方式及其解析参见后续章节的内容。
3.以表格形式查看DataFrame信息
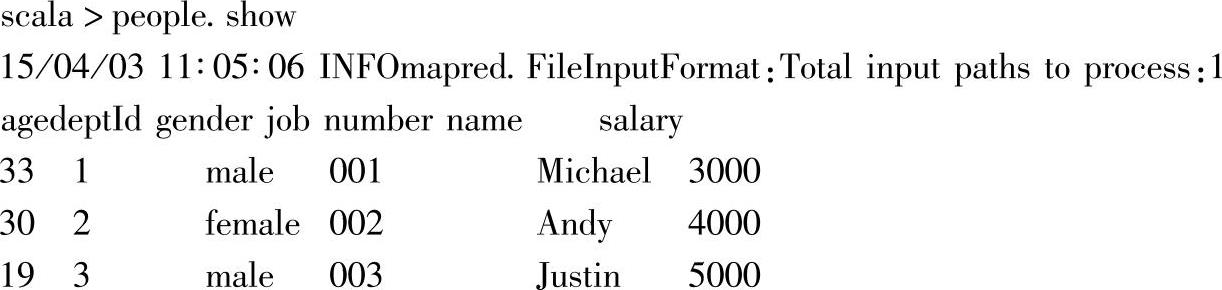
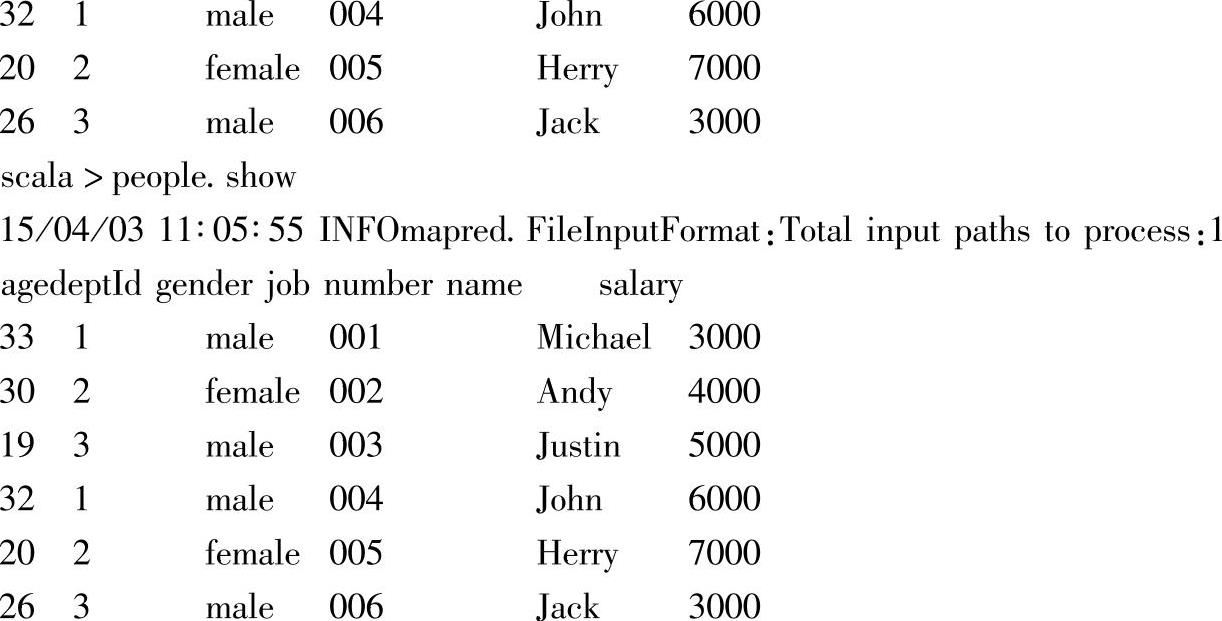
通过show方法,可以以表格形式输出各个DataFrame的内容。如上所示,可以看到该DataFrame加载的文件路径数,以及包含的各个列名和数据内容,默认情况下会显示Dat-aFrame的前20条记录,可以通过设置show方法的参数来指定输出的记录条数,如peo-ple.show(10),显示前10条记录。
4.DataFrame基本信息的查询

这部分内容针对员工信息的DataFrame,即people,进行一些基本信息的查询操作,具体包含:
1)使用DataFrame的columns方法,查询people包含的全部列(Columns)信息,以数组形式返回列名组。
2)使用DataFrame的count方法,统计people包含的记录条数,即员工个数。
3)使用DataFrame的take方法,获取前三条员工记录信息,并以数组形式呈现出来。
4)最后使用DataFrame的toJSON方法,将people转换为JsonRDD类型,并使用RDD的collect方法返回其包含的员工信息。
5.对员工信息进行条件查询,并输出结果

这部分内容针对员工信息的DataFrame,即people,进行一些条件查询的操作,具体包含:
1)使用count方法统计了“gender”列为“male”的员工数量。
2)基于“age”和“gender”这两列,使用不同的查询条件,不同的DataFrame API,即where和filter方法,对员工信息进行过滤。
3)最后仍然使用show方法,将查询结果以表格形式呈现出来。
4)在各个例子中,使用了几种不同的方式,作为查询条件的参数。
6.根据指定的列名,以不同方式进行排序

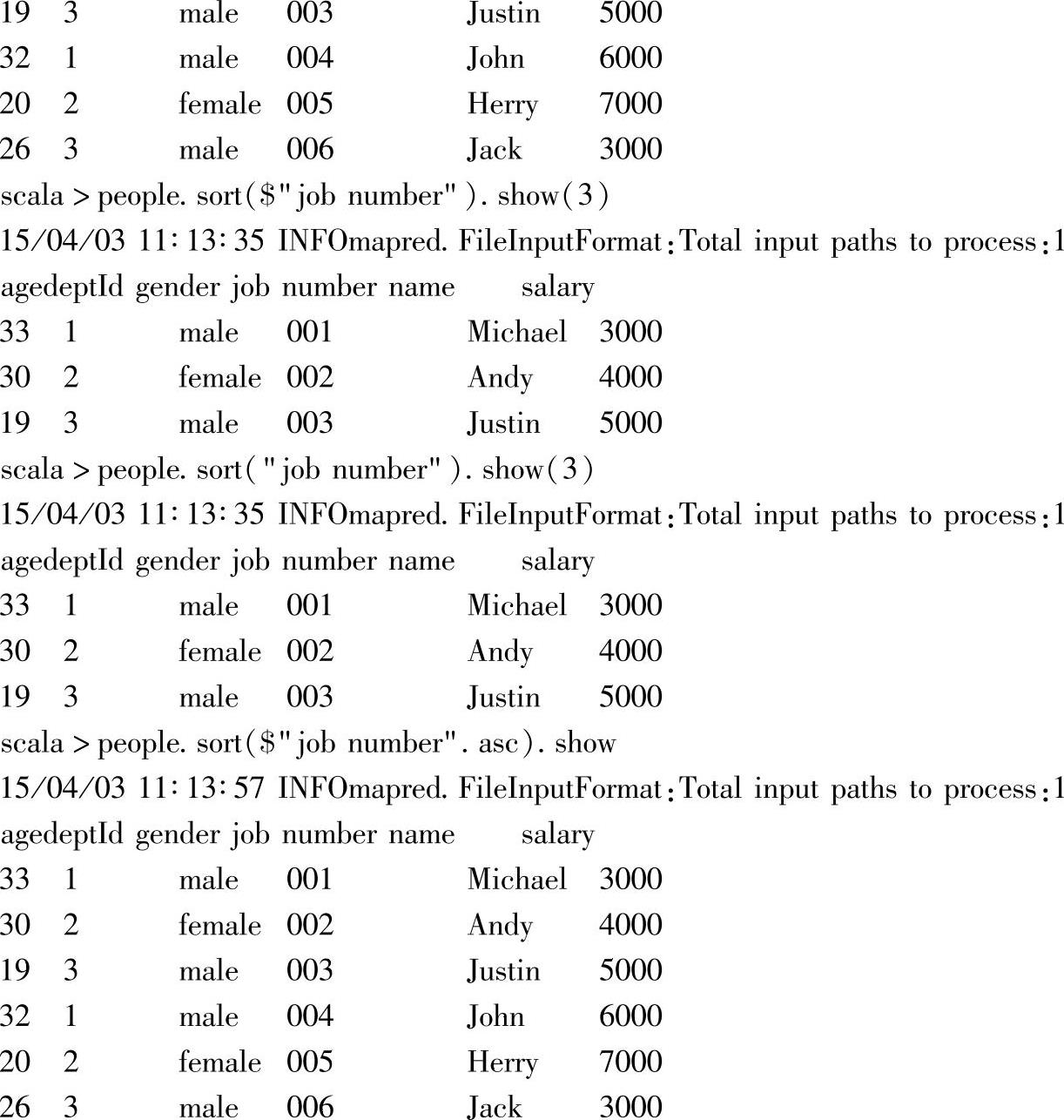
这部分内容针对员工信息的DataFrame,即people,基于“job number”和“deptId”列,用sort方法,并以不同方式进行排序,并输出结果,具体包含:
1)以先“job number”列升序,然后再“deptId”列降序的方式,对people进行排序,并输出排序后的内容;这里给出了两种指定列的方式。(https://www.xing528.com)
2)以“job number”列进行默认排序(升序),并显示排序后的3条记录;这里也给出了两种指定列的方式。
3)以“job number”列,指定降序方式进行排序,并显示排序后的3条记录。
7.为员工信息增加一列:等级(“level”)
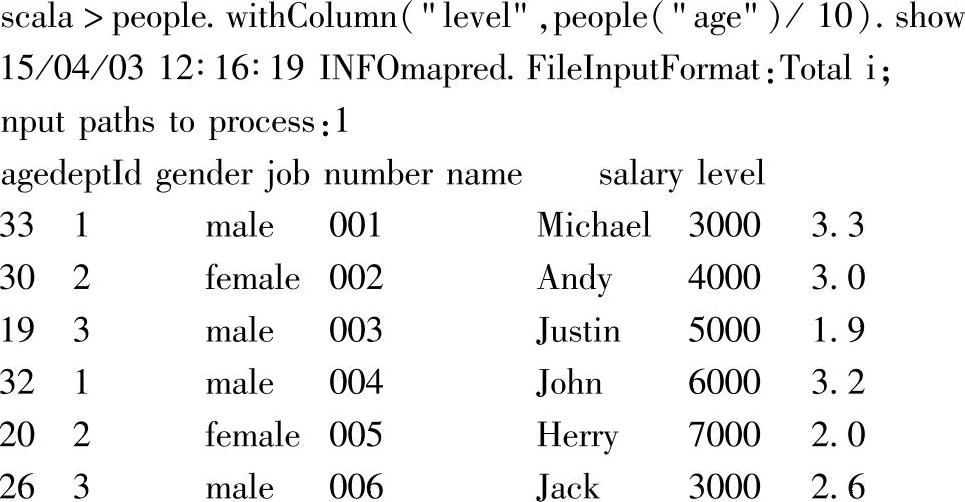
这部分内容针对员工信息的DataFrame,即people,通过withColumns方法增加了新的一列等级信息,列名为“level”。
其中,withColumns方法的“level”参数指定了新增列的列名,第二个参数指定了该列的实例,即通过“age”列转换得到的新列;而people("age")方法则调用了DataFrame的apply方法,返回“age”列名对应的列。
8.修改工号列名

这部分内容针对员工信息的DataFrame,即people,通过withColumnRenamed方法修改其现有的列名。
在示例中,将people的“job number”列名修改为“jobId”。通过交互式反馈信息可以看到列名已经被修改。
注意,修改的列名必须存在,如果不存在,不会报错,但列名不会修改,例如:

在示例中,指定修改的“job numbe”列名拼写错误,可以看到列名并没有被修改。
9.增加新员工

示例中使用jsonFile方法加载了新员工信息的文件,然后调用people的unionAll方法,将新加载的newPeople合并进来。
可以看到,最终合并时,对应的输入文件路径为2,即对应了新旧两个员工信息的文件,这是因为加载文件是lazy性质的。这里由于没有对DataFrame进行缓存,因此合并时会重新进行加载。
10.查同名员工

示例中,首先通过unionAll方法将people和newPeople进行合并,然后使用groupBy方法将合并后的DataFrame按照“name”列进行分组,分组操作会得到一个GroupData类的实例groupName,实例会自动带上分组的列,以及“count”列;GroupData类型提供了一组非常有用的统计操作,这里继续调用它的count方法,最终实现对员工名字的分组计数。
接着上对groupName实例进行过滤操作,使用filter方法,获取“name”列的计数大于1的内容,并表格形式予以呈现。
最后一个示例,使用函数式编程范式对前两个的合并,得到的结果是一样的。
11.分组统计信息
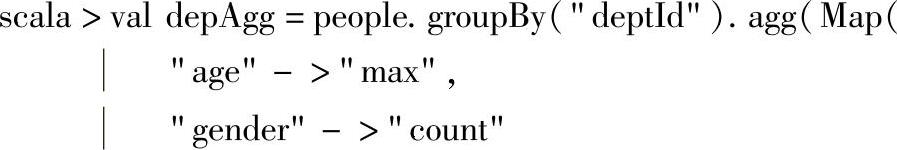

这里继续对分组统计实例进行解析。首先针对people的“deptId”列进行分组,分组后得到的GroupData实例继续调用agg方法,分别对“age”列求最大值,对“gender”进行计数。
由交互式界面反馈可知,最终返回DataFrame,并且它的schema为[deptId:bigint,MAX(age#0L):bigint,COUNT(gender#2):bigint],即除了带上分组用的“deptId”列外,还带上列聚合操作后的两列信息。
最后一步,调用DataFrame的toDF方法,重新命名之前聚合得到的depAgg的全部列名,增加了列名的可读性。
12.名字去重


示例中首先显示新旧员工信息合并后的“name”列,作为后续去重的比较对象。
通过unionAll新旧员工信息,并只选择其中的“name”列信息后,出现的“name”信息就出现列重复,通过继续调用DataFrame的distinct方法后,可以去除重复的记录数据。
13.对比新旧员工表

示例中,包含了对people和newPeople两个员工信息的“name”列的两种比较方式,具体如下。
1)第一种:分别选取people和newPeople两个员工信息的“name”列,然后通过调用except方法,获取在people中出现、但同时不在newPeople中出现的“name”信息,最后以表格形式呈现结果。
2)第二种:求“name”的交集,即分别选取people和newPeople两个员工信息的“name”列,然后通过调用intersect方法,获取在people中出现、但同时又在newPeople中出现的“name”信息,最后以表格形式呈现结果。
14.join两个DataFrame实例
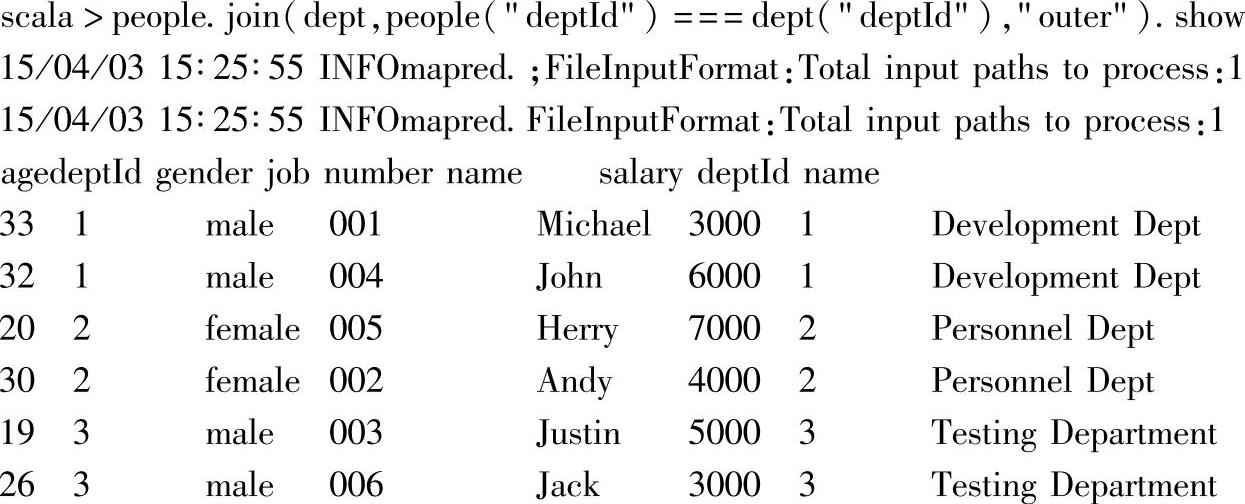
在示例中,people通过调用join方法,基于people的“deptId”列与dept的“deptId”列进行outer join联合操作。由于people与dept的两个DataFrame中用于联合的列名相同,都是“dept”,因此,指定联合条件表达式时,需要指出列所属的具体DataFrame实例,否则报错。
在作为join联合条件的列表达式中,如果列名不同,则可以直接使用列名,比如:

15.join后按部门名分组统计

这里使用了上例中基于“deptId”列对people与dept进行join的结果,即joinP。
通过对joinP调用groupBy方法,在联合结果上继续根据dept的“name”列进行分组,并在分组后对指定的列执行指定的聚合操作,这里对“age”列求最大值,对“count”列进行计数。
最后显示的结果上,按部门名称,统计部门员工最大的年龄以及部门的员工的性别(只有“female”,“male”两种)。
16.保存为表
在对各个DataFrame实例进行操作后,获取了目标信息,如果后续需要这些信息的话,就必须执行持久化操作,即将文件保存到存储系统或表中。
下面给出几种持久化的案例。
1)首先将实例持久化到表中。


此时,使用的默认的hive,没有连接到现有的hive环境上。
通过调用DataFrame的saveAsTable方法,将实例持久化到hive的“peopleDeplJion”表中。对应地,会在HDFS上构建hive用户的目录,即/user/hive,同时生成hive的仓库目录,即/user/hive/warehouse,每个构建的hive表,都会对应到该仓库下的一个子目录,持久化DataFrame实例后,对应创建列“peopleDeplJion”这个子目录。
通过Web Interface界面(http∶//namenode∶50070)查看目录结构,如图3.3所示。其中namenode为启动NameNode进程的节点,当前环境下的节点地址为192.168.70.214。
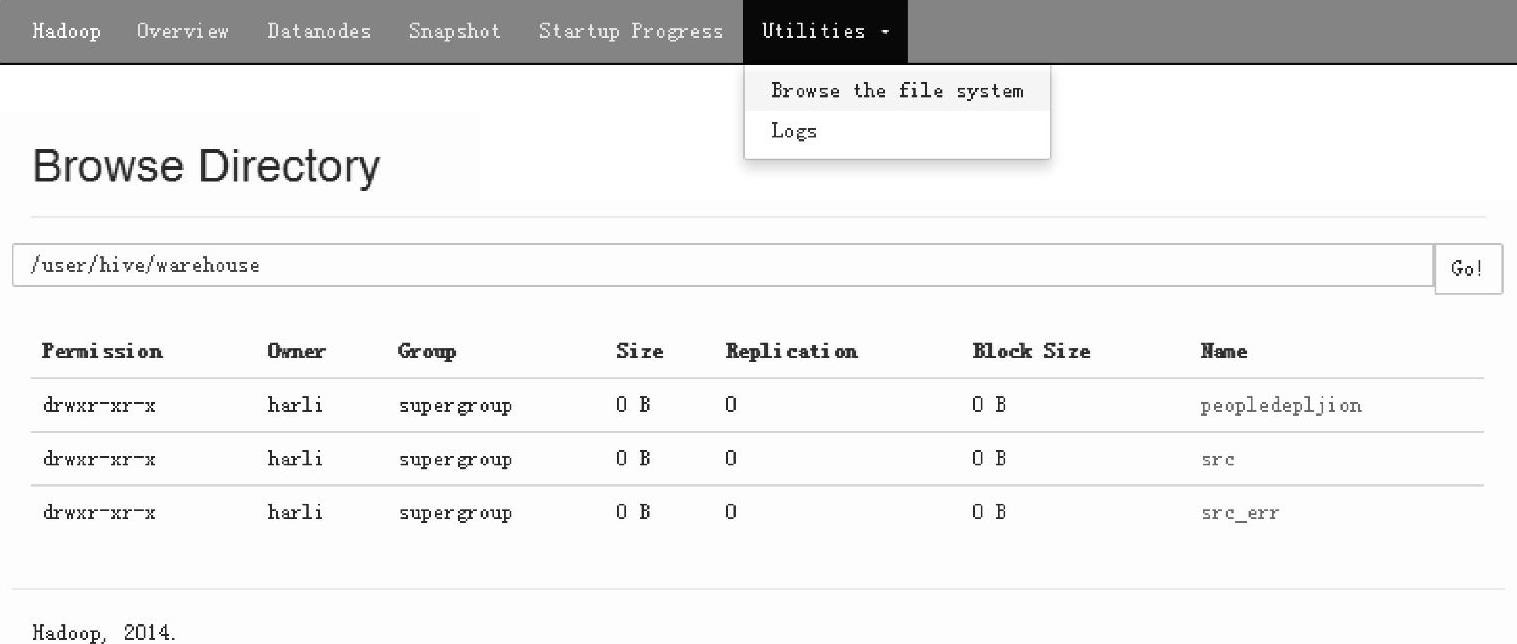
图3.3 Hadoop文件系统持久化后的界面
表相关的操作还有registerTempTable方法,这部分将在下一章节进行分析。
2)保存为json文件

这里使用save方法,通过在方法中指定数据源为“json”,可以将DataFrame实例持久化到指定的路径上。
通过Web Interface界面查看保存为json文件的结果,如图3.4所示,在/user/harli路径下生成列指定的hsqlDF.json文件。
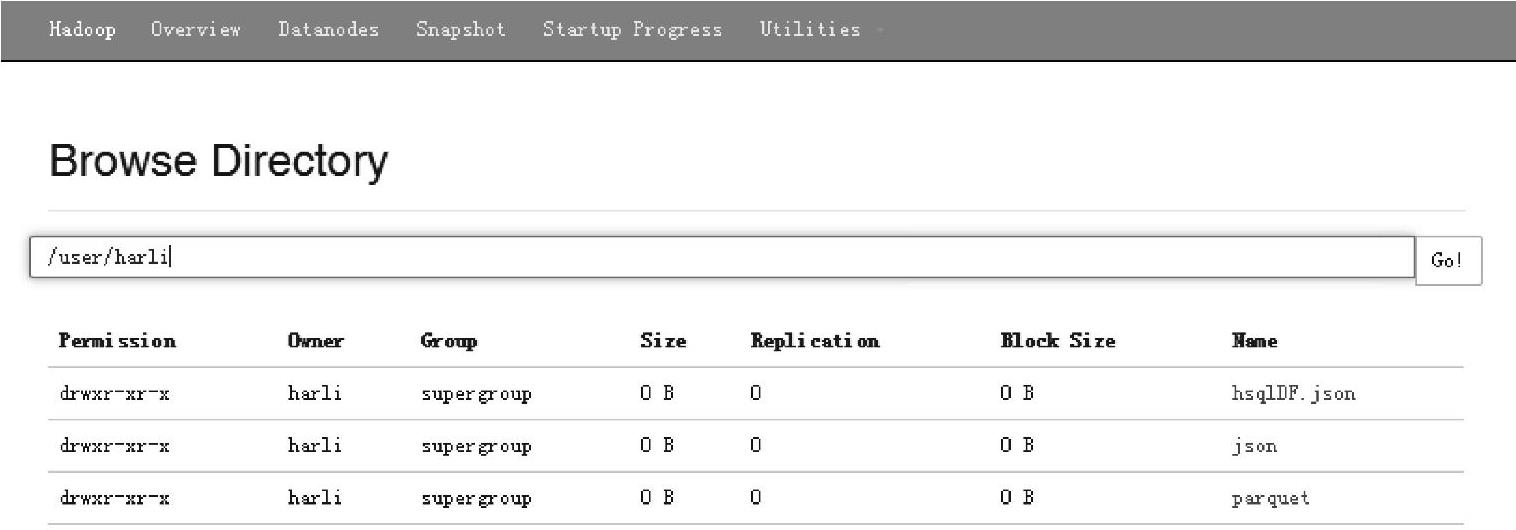
图3.4 Hadoop文件系统保存为json后的界面
3)保存为parquet文件
这里使用save方法,通过在方法中指定数据源为“parquet”,可以将DataFrame实例持久化到指定的路径上。
通过Web Interface界面查看保存为parquet文件的结果,如图3.5所示,在/user/harli路径下生成列指定的hsqlDF.parquet文件。
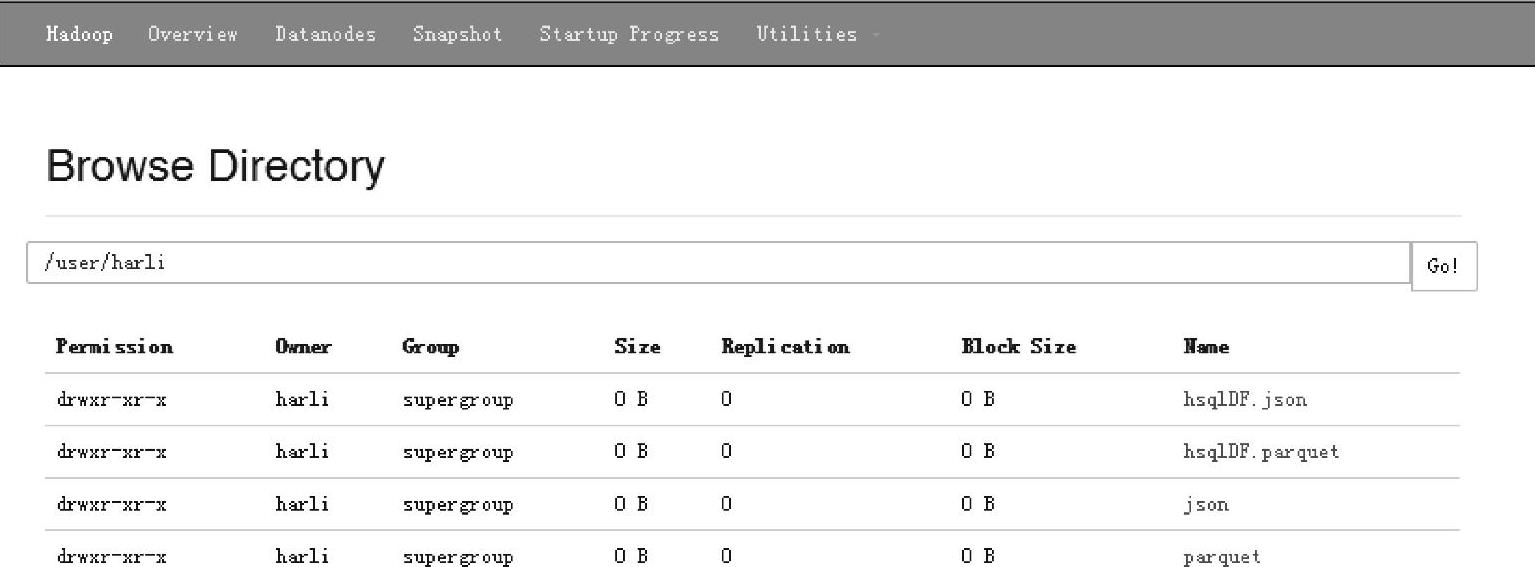
图3.5 Hadoop文件系统保存为parquet后的界面
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。